Se presenta un meta-estudio de opinión para medir cuantitativamente el grado de influencia que en promedio tiene sobre un encuestado su percepción de la opinión de los demás. Se obtuvo un alto grado de influenciabilidad o de manipulabilidad, cercano a m=1/2. Se muestra también que dados los resultados de una encuesta se puede modificar el resultado cambiando el método de una elección. Finalmente, se demuestra que el resultado de la elección presidencial del 2006 no fue significativo, pues sus incertidumbres superan la ventaja del supuesto ganador.
``Nunca se ha demostrado que el resultado de una encuesta sea capaz de alterar el resultado de una elección.´´ Esta frase, reiterada por representantes de las principales casas encuestadoras de México durante el proceso electoral en curso, es intrigante: ¿será posible demostrar el impacto de las encuestas en los resultado electorales? Quizás no exista forma alguna de hacerlo. Las encuestas pretenden ser fotografías que muestran las preferencias de una sociedad en ciertos instantes, espejos en los que la sociedad se ve a sí misma. Una encuesta bien hecha, honesta y realizada sobre una muestra representativa, coincidiría necesariamente con las preferencias de la sociedad al momento de ser realizada. Dicha coincidencia no indicaría inducción alguna. Las preferencias electorales son un ente dinámico; naturalmente evolucionan con el tiempo. Si posteriormente a la publicación de una encuesta las opiniones variaran, ¿cómo podríamos saber si la causa del cambio fue la publicación de la encuesta o algún otro factor? ¿Cómo establecer una relación causa-efecto? Es imposible realizar experimentos controlados, levantando numerosas elecciones en la misma sociedad, entre las mismas opciones y en las que nada difiriera excepto las encuestas publicadas. Este ejercicio no podría plantearse ni en forma serial ni en forma paralela, dada la temporalidad, escala y secresía de los ejercicios electorales. Además, estudios controlados del efecto de las encuestas requerirían la publicación de resultados distintos entre sí, los cuales no podrían todos ser verdaderos. ¿Qué casa encuestadora arriesgaría su prestigio en un experimento de ésta índole? ¿Cómo podrían publicar abiertamente en revistas académicas sus resultados? Por ello, es casi tautológica la afirmación de que nunca se ha demostrado la influencia de las encuestas en las elecciones. Claro que no se ha demostrado, pues aún si dicha influencia existiera, ¡sería imposible de comprobar!.
El 9 de marzo de 2012 recibí una atenta invitación de Areceli Damián y Marisela Connelly a participar en el foro Quinto Poder: Las Encuestas y la Construcción Social del Ganador, organizado en el Colegio Nacional por la Asociación de Académicos Daniel Cosío Villegas. En un principio rechacé la invitación puesto que mi trabajo electoral consistió básicamente en un análisis estadístico [1] de las anomalías en los resultados de las elecciones presidenciales del 2006, sin tomar en cuenta las encuestas previas a dicha elección. Sin embargo, recordé haber publicado un artículo de divulgación científica [2] un par de años antes sobre las paradojas matemáticas existentes en encuestas y elecciones, y el teorema de Arrow [3] sobre la imposibilidad de definir las preferencias de una sociedad a partir de las preferencias de sus miembros. Consideré que presentar ese trabajo podría justificar mi participación en el foro y ante la amable reiteración de las organizadoras acepté participar. Además del trabajo referido arriba, decidí añadir el resultado más sólido y menos sujeto a interpretaciones de mi análisis electoral, el análisis de los errores en los resultados de la elección del 2006 [4]. Éste muestra que las incertidumbres pueden cuantificarse y que fueron tan grandes que impidieron designar, desde el punto de vista técnico, al ganador, superando en un orden de magnitud a la diferencia en el número de votos recibidos por los dos primeros lugares, por lo que dicha diferencia resultó no significativa.
Finalmente, habiendo aceptado que participaría en el foro, decidí hacer un trabajo que sí estuviese relacionado directamente con el tema central a discutir. En la prensa escrita y electrónica han habido acusaciones hacia las grandes casas encuestadoras de hacer encuestas a modo con el propósito de complacer a los clientes que las pagan, y cuyo propósito es posicionar a alguno de los candidatos, establecer la percepción de que es un ganador y con ello atraer a los votantes hacia su candidatura. Las encuestadoras han contestado unánimemente que dicha acusación es necesariamente falsa, argumentando por un lado que la supervivencia de una empresa de estudios de opinión depende críticamente de su prestigio como empresa honesta y precisa, y por otro lado, que manipular encuestas sería inútil, aduciendo la frase con la que inicia esta introducción. Para obtener información objetiva sobre esta discusión, decidí hacer un estudio simple que permitiera evaluar cuantitativamente la influenciabilidad o la manipulabilidad de opiniones de un conjunto de encuestados al mostrárseles resultados de estudios de opinión en curso antes de darles la oportunidad de que ellos manifiesten su propia opinión. Desde luego, un estudio de opinión no es lo mismo que una elección federal, y si los resultados mostrasen el grado en que nuestras opiniones pueden ser modificadas por las opiniones de nuestros congéneres, quizás no habremos demostrado estrictamente que la publicación de resultados de encuestas modifiquen el resultado de elecciones subsiguientes, pero sí habremos mostrado que es muy plausible que así sea.
En la sección 2 de este artículo se presentará la metodología del estudio realizado mientras que la sección 3 mostrará sus resultados. Las secciones 4 y 5 incluirán los otros dos temas mencionados arriba, las paradojas matemáticas asociadas a las encuestas y elecciones y el análisis de errores e incertidumbres en la elección presidencial del 2006. Finalmente, en la sección 6 presentaré una discusión de los resultados y mis conclusiones.
Como fue discutido en la introducción, el propósito del meta-estudio de opinión fue medir la influenciabilidad o manipulabilidad de nuestra población ante intentos de inducir preferencias, si no electorales, sí de opinión, mediante la publicación de resultados de la encuesta en curso. Para ello se preparó una lista de veinte afirmaciones (ver Tabla 1).
Mi intención fue elegir frases algo controversiales similares a frases discutidas en la prensa. Intenté escoger frases tales que los encuestados se hallasen típicamente de acuerdo con aproximadamente la mitad. Encuestados de derecha tenderían a estar de acuerdo con el primer grupo de diez afirmaciones mientras que encuestados de izquierda estarían de acuerdo con las segundas diez afirmaciones (probablemente, este no fue el caso con la última afirmación). Sin embargo, el contenido de cada afirmación y su tendencia no son demasiado importantes para el análisis que sigue.
Se elaboró una página WEB [5] dinámica controlada por un pequeño programa CGI escrito en el lenguaje PERL [6] (ver apéndice) y una base de datos SQLite3 [7] que implementaron el siguiente procedimiento:
|
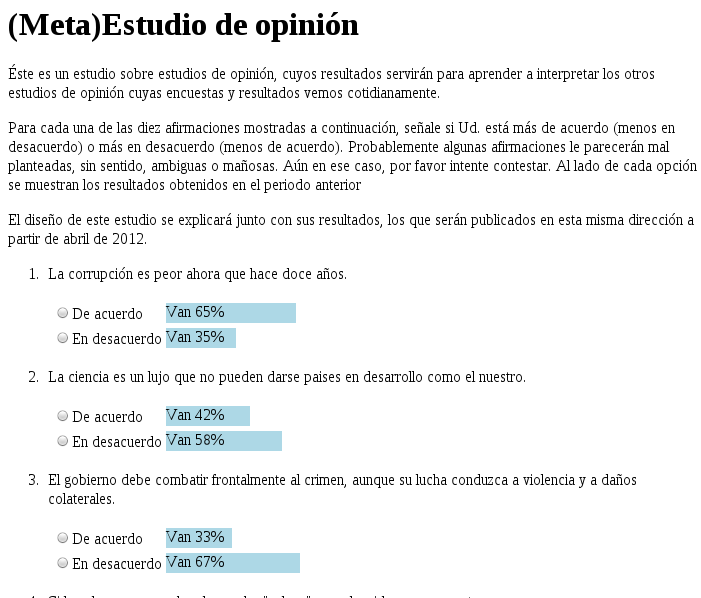
| Fig. 1. Parte de una de las encuestas aplicadas en [5]. Después de una breve introducción e instrucciones se presentaron una serie de afirmaciones, cada una con dos botones de radio para manifestar estar de acuerdo o en desacuerdo e información sobre resultados obtenidos durante el periodo anterior. |
Al final de cada encuesta se incluyó una nota aclaratoria afirmando que los porcentajes de acuerdos mostrados para cada afirmación no tenían validez estadística. Ésta es una verdad a medias, pues dichos porcentajes no tenían validez alguna, habiendo sido generados mediante un proceso aleatorio. El propósito de mostrar dichos porcentajes era correlacionarlos con la respuesta de los encuestados para poder obtener de ahí su manipulabilidad, es decir, qué tanto se puede influenciar la preferencia de la población por mostrarle preferencias previas, aunque éstas fuesen falsas.
La página web [5] para aplicar la encuesta fue montada el día 19 de marzo de 2012, y fue anunciada mediante un par de mensajes en Twitter y un mensaje en Facebook, así como en un addendum a un mensaje para anunciar un evento musical de Leika Mochán que fue enviado a una lista de distribución con 300 miembros. Todos los mensajes pedían redistribuir la invitación a participar en el estudio. La página permaneció abierta durante una semana hasta el día 26. Durante dicho periodo se llenaron 421 cuestionarios y se calificaron 4090 afirmaciones. El 85% de los encuestados provinieron de México, el 5% de los Estados Unidos, el 3% de España y el resto de países varios. Curiosamente, varios de los participantes sugirieron no mostrar los resultados preliminares sino hasta después de que la encuesta hubiese sido contestada para evitar inducir las respuestas. Una de las ventajas de las bases de datos SQLite3 es que toda ella se halla contenida en un solo archivo. El archivo con los resultados crudos de la encuesta está disponible en [9].
Los porcentajes de acuerdos con cada una de las afirmaciones se muestra como un número entre paréntesis al lado de cada una de las sentencias en la tabla 1. Aunque dichos datos puedan parecer interesantes, es muy probable que no reflejen las opiniones de la población en general, pues en este estudio no se realizó ningún esfuerzo por garantizar que la encuesta fuese aplicada a un grupo cuya opinión fuese representativa en sentido alguno. Los encuestados fueron convocados a partir de seguidores en redes sociales y de corresponsales. Quizás la mayoría de quienes respondieron son cercanos a los medios académicos.
No me detendré más en las respuestas obtenidas, pues el propósito de este estudio no fue obtener información sobre las opiniones de la población en general ni de los participantes en el estudio; el propósito era obtener información sobre la posibilidad de manipular dichas opiniones a través de la publicación previa de información estadística falsa. Es por ello que denominé al mismo como un meta-estudio de opinión.
Como se describió en la sección anterior, los porcentajes inductores fueron sintetizados aleatoriamente sumando dos números I y F distribuidos uniformemente sobre los intervales 20 a 80 y -12 a 12 respectivamente. Por lo tanto, su distribución consistiría de una rampa lineal ascendente en el intervalo 8 a 32 y una rampa lineal descendiente en el intervalo 68 a 92, siendo una distribución uniforme sólo en la región que va de 32 hasta 68. Para simplificar el análisis de los resultados, en un primer paso deseché todos los datos cuyo porcentaje inductor se hallase fuera de la región uniforme 32-68. Para evitar que algún usuario deformase los resultados contestando varias encuestas desde una misma computadora, para cada número IP seleccioné el primer cuestionario respondido y deseché los demás. La aplicación de estos filtros eliminó 1656 datos, dejando 2434 respuestas. Estas se ordenaron de acuerdo al porcentaje inductor y se agruparon en 6 grupos de alrededor de 406 miembros. Para cada grupo se obtuvo el promedio <A> del porcentaje inductor de acuerdos, el porcentaje <R> de las afirmaciones del grupo que obtuvo la respuesta De acuerdo, la incertidumbre ΔA correspondiente a los porcentajes inductores, la incertidumbre esperada ΔR en el porcentaje de acuerdos suponiendo una distribución binomial, y el número de respuestas G incluidas en el grupo.
| <A> | <R> | ΔA | ΔR | G |
|---|---|---|---|---|
| 34.15 | 36.21 | 1.66 | 2.39 | 406 |
| 40.09 | 40.39 | 1.78 | 2.44 | 406 |
| 46.55 | 46.80 | 1.95 | 2.48 | 406 |
| 52.86 | 49.51 | 1.72 | 2.48 | 406 |
| 59.17 | 49.51 | 2.08 | 2.48 | 406 |
| 65.57 | 51.24 | 1.62 | 2.49 | 404 |
Tabla 2: Resultados del metaestudio de opinión. Las columnas de la tabla son el porcentaje inductor promedio <A>, el porcentaje de acuerdo <R>, la incertidumbre en el porcentaje inductor ΔA, la incertidumbre en la respuesta ΔR y el tamaño del grupo de afirmaciones G.
Podemos apreciar que las incertidumbres en los datos presentados están contenidas en el rango 1.5%-3.0%. En la fig. 2 mostramos gráficamente los resultados contenidos en la tabla 2; en el eje vertical graficamos el porcentaje <R> de afirmaciones de cada grupo con el que los encuestados manifestaron su acuerdo, como función del promedio <A> del porcentaje que se le mostró a los encuestados como supuesto resultado de cortes previos de la misma encuesta, i.e., el porcentaje inductor. Se muestran además las barras de error de cada dato. Aunque los resultados parecen tener un comportamiento descrito por una curva convexa, al tomar en cuenta las incertidumbres de cada punto, es claro que también son consistentes con una línea recta. De una simple regresión lineal obtenemos que dicha recta tiene una pendiente m=0.48±0.09. El coeficiente de correlación de Pearson [10] es r=0.94.
Desde luego, sería imposible someter a cada individuo a distintos niveles de inducción y comparar sus respuestas, pues este experimento requiere que el individuo crea que los porcentajes que le son presentados son reales. Sin embargo, por la forma en que fue elaborada la prueba, cada individuo contribuyó a tres grupos consecutivos de los seis grupos mostrados en la tabla 2 y en la fig. 2 y dada la naturaleza aleatoria con que se seleccionaron los porcentajes inductores, los individuos y las preguntas que contribuyen a cada fila de la tabla y a cada punto de la gráfica son equivalentes a los correspondientes a las demás filas y a los demás puntos. El único cambio significativo entre unos y otros es el porcentaje inductor y el número de acuerdos obtenidos. Por lo tanto, se puede interpretar nuestro resultado diciendo que, en promedio, cada vez que a un individuo se le induce a percibir que el porcentaje de aceptación de cierta afirmación aumenta en, digamos, 2%, la probabilidad de que dicho individuo se manifieste de acuerdo aumenta en aproximadamente 1%, i.e., nuestra manipulabilidad es cercana a 1/2.
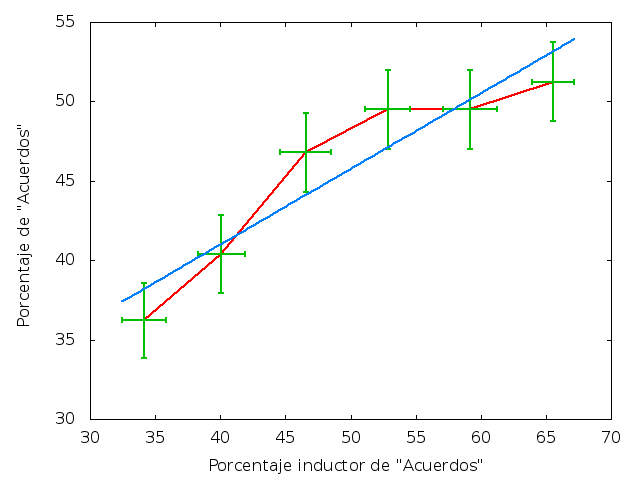 |
| Fig. 2: Porcentaje <R> de afirmaciones que recibieron la respuesta de acuerdo como función del porcentaje <A> inductor de acuerdos. Se muestran las barras de error de cada dato. |
Esperando que los resultados de esta encuesta le permitan a Ud. elegir democráticamente al candidato que Ud. considere idóneo, quedo de Ud., Atentamente... Con esta despedida concluyó una broma electoral basada en un estudio de opinión adaptado de un libro de John Allen Paulos [11] y que fue publicada en La Unión de Morelos en un espacio [2] a cargo de la Academia de Ciencias de Morelos [12]. La broma se refiere a cierta elección en la que participan cuatro candidatos, llamémosles A, B, C y D, en la que una encuesta arroja la siguiente tabla de preferencias:
| Tabla de preferencias | ||||
|---|---|---|---|---|
| A | B | C | D | Primera Opción |
| D | D | B | C | Segunda Opción |
| C | C | D | B | Tercera Opción |
| B | A | A | A | Cuarta Opción |
| 48% | 24% | 20% | 8% | Porcentaje |
Tabla 3: Tabla de preferencias durante cierta elección con cuatro candidatos A, B, C y D. Cada columna corresponde a una secuencia de preferencias y al final se muestra el porcentaje de la población que comparte dichas preferencias.
La tabla muestra que el 48% de la población prefiere al candidato A sobre D, a D sobre C y a C sobre B, mientras que el 24% prefiere a B sobre D, a éste sobre C y por último a A, etc. En base a los resultados anteriores, podría llevarse a cabo:
Este ejemplo ilustra cómo empleando la misma tabla de preferencias, cada uno de cuatro métodos comunes de elección (votación sencilla, a dos vueltas, rondas eliminatorias y voto ponderado) lleva a cuatro resultados totalmente distintos. ¿Cuál es el correcto? Es imposible contestar. Podría argumentarse que el resultado correcto es que A gane pues tiene más adeptos que los demás, pero podría contra-argumentarse que A debería perder, pues la mayor parte de la población lo detesta.
Este ejemplo ilustra los profundos problemas a que se enfrentan los sistemas electorales, algunos de los cuales han sido capturados en un resultado matemático conocido como el Teorema de Imposibilidad de Arrow, introducido por el economista Kenneth J. Arrow. Considere una elección de la cual resulte una lista de las preferencias de una sociedad, determinada a partir de las preferencias individuales de sus miembros. Idealmente se deberían cumplir las siguientes condiciones:
El teorema de Arrow establece que no existe ningún mecanismo de elección entre tres o más candidatos que cumpla con todos los criterios enunciados arriba. Este es un teorema matemático: No muestra que hayamos sido incapaces de encontrar mecanismos idóneos, justos y objetivos para que la sociedad tome decisiones considerando las preferencias de todos sus miembros en toda circunstancia y cumpliendo con las razonables condiciones enunciadas arriba; nos dice que es y será imposible hallar dicho mecanismo, sin importar cuánto nos esforcemos en buscarlo. Lo anterior se suele resumir diciendo que, matemáticamente, no puede haber una democracia perfecta.
Levantar e interpretar encuestas es un proceso estadístico permeado de incertidumbres que deben valorarse. Las encuestas suelen realizarse sobre muestras relativamente pequeñas de la población cuyas preferencias o características deseamos averiguar. Para ser significativa, dicha muestra debe ser representativa de la población en su conjunto. Un problema fundamental de la estadística, la ciencia del estado, es la adecuada selección de la muestra, las pruebas a realizar para garantizar su representatividad y la estimación de las posibles desviaciones debidas a fluctuaciones estadísticas originadas en la finitud y pequeñez del número de participantes. Además, deben atenderse otras sutilezas, tales como la incorporación de mecanismos que permitan diagnosticar la veracidad de las respuestas y eliminar los datos no confiables.
En contraste, las elecciones son un procedimiento conceptualmente simple. Sólo es necesario contar de forma exhaustiva todos los votos emitidos por todos los votantes, un ejercicio masivo pero esencialmente exacto. Sin embargo, aún al contar se pueden cometer errores, intencionales o inadvertidos. También se pueden cometer errores al transcribir los datos hacia las actas electorales. Por lo tanto, es imperativo cuantificar la magnitud de dichos errores. Afortunadamente, las bases de datos correspondientes al Programa de Resultados Electorales Preliminares (PREP) de las elecciones del 2006 contienen una serie de datos que en principio deberían ser redundantes, i.e., algunos de ellos deberían estar determinados por los demás. Por ejemplo, consideremos el número de boletas electorales depositadas en una urna. Este podría obtenerse simplemente contando las boletas una a una y anotando el resultado. El mismo número podría obtenerse sumando el número de votos que obtuvo cada uno de los candidatos registrados para la elección y añadiendoles las votos para candidatos no registrados y las boletas anuladas. Un tercer procedimiento para obtener dicho número sería contar a través del número de sellos estampados en la lista de electores el número de ciudadanos que se presentaron a votar. También podrían contarse antes de iniciar la votación las boletas electorales recibidas y restar de este número las boletas electorales sobrantes al terminar la elección. Todos estos números deberían coincidir entre sí. Sus discrepancias son indicadores de error. La cuantificación de estos errores nos proporciona una medición de las incertidumbres en los resultados electorales.
Un estudio detallado de la base de datos del PREP (se pueden consultar copias de dichas bases de datos en [1]) correspondiente a la elección presidencial del 2006 arroja los siguientes resultados:
Algunos de estos errores se debieron a electores que confundieron la urna donde deberían depositar su voto con las urnas de casillas contiguas. Sin embargo, los errores no disminuyen significativamente cuando los resultados de todas las casillas contiguas se agregan entre sí, por lo que dicha confusión no es suficientemente grande para explicarlos.
Durante los cómputos distritales sólo se corrigieron cuatro mil resultados. Curiosamente, las correcciones mostraron que los errores cometidos estaban sesgados. Únicamente se abrieron 2.9 mil paquetes a pesar de haber errores de uno u otro tipo en más de la mitad de las casillas. Por lo tanto, ante la pregunta ¿quién ganó las elecciones presidenciales del 2006 en México? la respuesta técnicamente correcta es que la diferencia de aproximadamente 250 mil votos entre el candidato del partido Acción Nacional y el de la Coalición por el Bien de Todos fue no significativa por ser alrededor de un orden de magnitud menor que las incertidumbres de los resultados electorales. Por lo tanto, en el mejor de los casos, no sabemos quién ganó la elección.
Los detalles de este análisis pueden hallarse en la referencia [4] y en el sitio [1].
En este trabajo presentamos un meta-estudio de opinión que muestra una manipulabilidad sorprendentemente alta, cercana a m=1/2. Ello significa que por cada aumento que percibimos en la aceptación de cierta idea, la probabilidad de que manifestemos estar de acuerdo con ella aumenta en la mitad. Por ejemplo, si creyeramos que 10% más de la población aprueba cierta afirmación, la probabilidad de que nosotros la aprobemos aumentaría en 5%. El meta-estudio realizado fue de proporciones modestas, de sólo unos cuantos cientos de encuestados y unos cuantos miles de respuestas. Sería deseable repetir el estudio con una muestra mucho mayor. Sin embargo, una dificultad con esta clase de estudio es que, en analogía al empleo de placebos en pruebas clínicas de medicamentos, implican un engaño intencional al encuestado. Una vez descubierto este engaño, el mismo encuestado y el mismo encuestador estarían imposibilitados de repetir un estudio similar. En todo caso, los resultados obtenidos son significativos y su sistemática supera a sus fluctuaciones. A pesar de que la población muestreada no fue representativa, lo cual es común en todas las encuestas en línea, el objetivo no era estudiar sus opiniones sino la posibilidad de influenciar éstas. A priori, no parece haber elementos para creer que otros grupos de la población sean menos influenciables que los participantes en esta encuesta. Más bien, podría esperarse que otros grupos, más lejanos del medio académico, sean aún más influenciables.
Dada la gran manipulabilidad hacia la construcción de consensos de opinión demostrada por el meta-estudio descrito arriba, creo que no sería demasiado aventurado extrapolar los resultados hacia los procesos electorales y concluir que las encuestas sí podrían jugar un papel fundamental en la construcción social del ganador. Por lo tanto, sí habría una motivación para que grupos de interés busquen la publicación de resultados que favorezcan a uno u otro candidato, lo cual bastaría para que la ciudadanía desconfíe de los resultados que se le presentan. Desde luego, este estudio no demuestra que las encuestas publicadas recientemente o por publicarse hayan sido o vayan a ser manipuladas, pero sí muestra que puede haber interés por hacerlo. Sería importante elaborar mecanismos y ofrecer información adicional que permita a la ciudadanía verificar la veracidad de las encuestas públicas. Una legislación que garantizara el acceso, aunque fuese a posteriori, a la información existente en las encuestas privadas, las cuales tendrían menos motivos para ser manipuladas, podría ayudar a calificar la veracidad de las encuestas.
En otra parte de este trabajo mostramos cómo dada una tabla de preferencias electorales de una población, distintos métodos electorales pueden llevar a resultados muy distintos. Por lo tanto, la población debe estar alerta ante cualquier cambio de procedimientos electorales y asegurarse de que su intención no es la manipulación de los resultados en vista de datos arrojados por encuestas previas a la elección. Si bien esto puede ser de poca importancia en elecciones federales, donde el tipo de elección está bien establecido con anticipación, si es de importancia en otro tipo de elecciones que afectan, por ejemplo, la toma de decisiones en un grupo, la vida sindical, etc.
Por último, discutimos las incertidumbres presentes en procesos que en principio debieran ser exactos pero que en los hechos no lo son. En particular, evaluamos las incertidumbres en la elección presidencial del 2006 y demostramos que el resultado de la misma fue no conclusivo pues la diferencia entre las votaciones alcanzadas por los principales contendientes fue no significativa. En este respecto es importante impulsar cambios en la legislación que obliguen a medir la incertidumbre como parte integral del proceso electoral y establecer una diferencia de votos significativa entre los contendientes, que supere dicha incertidumbre, como un requisito para poder designar al ganador. Tambien es fundamental impedir que el Instituto Federal Electoral (IFE) elimine aquellos campos de las actas electorales y de las bases de datos del PREP que permiten evaluar las incertidumbres, por considerar que el llenado de dichos campos puede ser confuso y conduce al error, como algunos funcionarios del mismo IFE han afirmado. Esos campos no producen errores; más bien, permiten su cuantificación.
Si bien las matemáticas nos aseguran que no hay un sistema ideal, ellas mismas pueden ayudarnos a evaluar diversos sistemas electorales para desechar los peores y establecer los mejores. Las matemáticas también nos permiten estudiar las propiedades estadísticas de los resultados y la confiabilidad de los mismos y nos enseñan a cuantificar sus márgenes de incertidumbre. El teorema de Arrow y la consecuente imposibilidad de la perfección no nos debe volver complacientes frente a las deficiencias de nuestro sistema electoral.
Agradezco las útiles sugerencias de H. Larralde y de J.E. Mochán y la lectura crítica de G. Quesnel.
#! /nombre/del/interprete/de/perl -T
# Programa para levantar la Meta-encuesta de Opinión.
use strict;
use warnings;
use Captcha::reCAPTCHA;
use DBI;
use CGI qw/:standard/;
use CGI::Carp 'fatalsToBrowser';
$CGI::POST_MAX=50*1024; #limita la información a subir
$CGI::DISABLE_UPLOADS = 1; #para evitar ataques
# base de datos
my $dbname="/home/mochan/txt/talks/12/encuestas/database/database.db";
my $dbh=DBI->connect("dbi:SQLite:dbname=$dbname", "", "",
{RaiseError=>1} );
# prueba de Turing
my $captcha=Captcha::reCAPTCHA->new;
my $pubkey="6Lf82M4SAAAAADklPE8WtSN-H_qIlgfpD4ew7f4i";
my $privkey="aquí va la clave privada";
# Encabezados y textos
my $titulo="(Meta)Estudio de opinión";
my @instrucciones1=l(
q(Éste es un estudio sobre estudios de
opinión, cuyos resultados servirán para aprender a
interpretar los otros estudios de opinión cuyas encuestas y
resultados vemos cotidianamente.),
q(Para cada una de las diez afirmaciones mostradas a continuación,
señale si Ud. está más de acuerdo (menos en
desacuerdo) o más en desacuerdo (menos de acuerdo). Probablemente
algunas
afirmaciones le parecerán mal planteadas, sin sentido, ambiguas
o mañosas. Aún en ese caso, por favor intente contestar. Al
lado de cada opción se muestran los resultados obtenidos en el
periodo anterior),
q(El diseño de este estudio se explicará junto con sus
resultados, los que serán publicados en esta misma dirección a
partir de abril de 2012. ),
);
my $instrucciones2=l(
q{Con objeto de evitar que los datos recabados en este estudio se vean
falseados por algún autómata, debemos pedirle que por favor
identifique y escriba en el cuadro abajo las palabras que se
muestran a continuación } .
b(q(distinguiendo )) .
q{mayúsculas de minúsculas e
incluyendo dígitos y signos de puntuación si los hubiese (disculpe las
molestias). Finalmente, pulse el botón } .
b('Finalizar') .
"."
);
my $instrucciones3=l(<<'FIN');
'
Desafortunadamente, las palabras que introdujo no coincidieron con las
que le habíamos mostrado. Por favor, vaya al final de esta forma y
vuelva a intentarlo.
'
FIN
my $instrucciones4=[(
q(Muchas gracias por haber apoyado el presente estudio. La información
que nos ha proporcionado ha quedado registrada. Su
participación ha sido muy importante. Los resultados de este
estudio serán
dados a conocer en esta misma dirección a partir de abril de
2012. Esperamos su visita.),
q(Para que los resultados de este estudio adquieran validez
estadística necesitamos una amplia participación. Por favor ).
em(q(promueva entre sus amigos, conocidos, contactos y/o seguidores la
participación en este estudio
invitándolos a entrar a la
dirección ))
.
a({href=>"http://bit.ly/FPviji"}, "http://bit.ly/FPviji. ")
.
q(¡Gracias!),
q(Ahora puede cerrar esta página o pulsar el
boton ATRÁS para dejar este sitio y seguir navegando.))];
my $instrucciones5=l(
q(Nota: Las porcentajes de preferencias asociadas a cada respuesta
arriba no tienen (aún) validez estadística));
my %encuesta;
# revuelve al azar afirmaciones
sub randomize {
my @args=@_;
my @out;
while (@args) {
my $i=int(rand(scalar @args));
push @out, splice @args, $i, 1;
}
return @out;
}
# ilustra un porcentaje como una barra
sub barra {
my ($p, $c)=@_;
my $l = $p*2;
return div({style=>qq(
background-color:$c;
width:${l}px;height:20px;solid \#000)}, "Van $p%");
}
# Prepara una pregunta
sub pregunta {
my $index=shift;
my @radio= radio_group(
-name=>"$index",
-values=>[0,1,2],
-labels=>{
0=>"-",
1=>"De acuerdo",
2=>"En desacuerdo"},
-linebreak=>1,
-default=>0
);
return
p(["$encuesta{$index}{afirmacion}.",
table(Tr([td([$radio[1],
barra($encuesta{$index}{porcentaje}, "lightblue")]),
td([$radio[2],
barra(100-$encuesta{$index}{porcentaje},"lightblue")])]))]);
}
# lee datos de la base de datos.
sub leedatos {
my $afirmaciones=$dbh->selectall_arrayref(
"SELECT * FROM afirmaciones", {Slice=>{}});
my $getporcentajes=$dbh->prepare(
qq{SELECT porcentaje FROM porcentajes
WHERE ip="$ENV{REMOTE_ADDR}" and pregunta=?});
foreach my $afirmacion(@$afirmaciones){
my $indice=$afirmacion->{indice};
$getporcentajes->execute($indice) or die $getporcentajes->errstr;
# fetch a percetage
my $porcentaje=$getporcentajes->fetchrow_array;
#if neccesary make percentages up
nuevosporcentajes($afirmaciones), redo unless $porcentaje;
$encuesta{$indice}{afirmacion}=$afirmacion->{afirmacion};
#$encuesta{$indice}{izquierda}=$afirmacion->{izquierda};
$encuesta{$indice}{porcentaje}=$porcentaje;
}
}
# inventa porcentajes de ser necesario
sub nuevosporcentajes {
# Añade porcentajes para todas las preguntas para una ip.
my $afirmaciones=shift;
my ($min, $max)=(20, 80); #cotas porcentajes;
my $fluc=12; #cotas fluctuaciones
my $percentizq = $min+int(rand($max-$min)); #probabilidad de votar izquierda
my $putporcentajes=$dbh->prepare(
qq{INSERT INTO porcentajes (timestamp, ip, pregunta, porcentaje)
VALUES(current_timestamp, "$ENV{REMOTE_ADDR}", ?, ?)});
foreach(@$afirmaciones){
#añade fluctuaciones
my $p=$percentizq-$fluc+int(rand(2*$fluc));
$p=$percentizq+int(rand($fluc)) until $p>0 && $p<100;
#complementa para preguntas de derecha
$p=100-$p unless $_->{izquierda};
$putporcentajes->execute($_->{indice}, $p);
}
}
# guarda datos en la base de datos.
sub escribedatos {
my $guarda=$dbh->prepare(<<"FIN");
INSERT INTO respuestas (timestamp, ip, pregunta, porcentaje, respuesta)
VALUES (current_timestamp, \"$ENV{REMOTE_ADDR}\", ?, ?, ?)
FIN
map
$guarda->execute($_, $encuesta{$_}{porcentaje},param($_)),
grep m/^\d+$/, param;
}
# imprime una encuesta
sub encuesta {
leedatos();
#elige diez preguntas al azar
my @preguntas=randomize(keys %encuesta);
@preguntas=splice @preguntas,0,10;
print header(-charset=>'utf-8'),
start_html(-title=>$titulo, -author=>'mochan@fis.unam.mx'),
h1($titulo),
p([@instrucciones1]),
start_form,
ol(map li(pregunta($_)), @preguntas),
p($instrucciones2),
#pide un Captcha
table(Tr(td([$captcha->get_html($pubkey),
submit(-name=>'guarda', -value=>'FINALIZAR')]))),
end_form,
hr,
p($instrucciones5),
end_html;
}
# repite las preguntas que ya teniamos en caso de errores
sub denuez {
leedatos();
#elige las preguntas que teníamos
my @preguntas= grep m/^\d+$/, param;
print header(-charset=>'utf-8'),
start_html($titulo),
h1($titulo),
p(font({-color=>'RED'},$instrucciones3)),
hr,
p([@instrucciones1]),
start_form,
ol(li([map pregunta($_), @preguntas])),
p($instrucciones2),
#pide un Captcha
$captcha->get_html($pubkey),
submit(-name=>'guarda', -value=>'Finalizar'),
end_form,
hr,
p($instrucciones5),
end_html;
}
# agradece la participación si todo sale bien.
sub vientos {
leedatos();
escribedatos();
print header(-charset=>'utf-8'),
start_html($titulo),
h1($titulo),
p($instrucciones4),
end_html;
}
# prepara una encuesta la primera vez
encuesta() unless(param());
# si ya terminó de contestar, checa que sea humano
if(param('guarda')){
my $challenge=param('recaptcha_challenge_field');
my $response=param('recaptcha_response_field');
my $result=$captcha->check_answer(
$privkey, $ENV{'REMOTE_ADDR'}, $challenge, $response
);
denuez() unless $result->{is_valid};
vientos() if $result->{is_valid};
}
sub l { #limpia texto de comentarios y líneas con puras comillas
my @res;
while($_=shift @_){
s/^'$//mg;
s/^\#.*\n//mg;
push @res, $_;
}
return @res if wantarray;
return shift @res;
}