English version (most probably outdated)
Elecciones presidenciales, México 2006
¿Anomalías en el PREP?
Luis Mochán
CCF-UNAM, Cuernavaca, Morelos
Julio 2-9, 2006
Ultima actualización:
$Id: index.html,v 1.12 2006/07/14 03:15:09 mochan Exp mochan $ (Ojo:
el reloj de mi computadora está 5 hrs. adelantado pues olvidó su
huso horario)
Lista de modificaciones recientes.
Archivo RCS con todas las versiones
previas (a partir de 11/vii/06). Las puede obtener con el comando
co.
Archivo comprimido.
Nuevo: (13/vii/06) Bases de datos del
conteo distrital
Se presenta un análisis
fenomenológico inicial de los datos publicados por el IFE de manera
electrónica respecto al proceso electoral llevado a cabo en México el dos de
julio del 2006. Se discuten algunos comportamientos de los datos que me han
parecido extraños.
Espejos
Varios lectores han contribuido con espejos de esta página. Es
recomendable guardar las ligas por si mi computadora se vuelve
inaccesible (lo cual sucede con cierta frecuencia):
- Versión
original (ocasionalmente estará un poco más actualizada que los
espejos).
- Espejo
1 (cortesía de LibertadExpresa).
-
Espejo
2 (cortesía del Departamento de Física del
CINVESTAV).
-
Espejo
3
(Cortesía de ScriptConnector). Para
facilitar el acceso, el Ing. Francisco Sam Castillo dividió la página
en partes más pequeñas las cuales pueden ser accesadas a través de las
siguientes ligas:
Parte
I,
Parte II,
Parte III y
Parte IV. Hay además un micrositio
de seguimiento al proceso electoral que contiene este estudio en la
sección Mexico 2006-2012/PREP.
- Espejo
4 (cortesía de Patria Nueva). Marcelo
Flores hizo además una breve presentación
del trabajo.
- Probablemente aún me falten otros espejos. ¡Gracias!
Por favor háganme saber aquí
los errores que hallen en las ligas mencionadas arriba.
-
Advertencia: Lo que sigue no debe tomarse como un estudio
científico concluido, aunque sí podría considerarse como la parte
inicial de uno. Tiene algo de datos duros verificables obtenidos de
fuentes reconocidas, descripciones fenomenológicas de los mismos e
hipótesis sugeridas por los datos las cuales implican consecuencias
adicionales que podrían y deberían ser exploradas. Estas podrían formar el
inicio de investigaciones posteriores para confirmar o
desechar las hipótesis. Además, hay especulaciones, hilos sueltos, preguntas y
opiniones... y errores. Todos éstos son
elementos de toda investigación en la vida real, aunque la mayor parte
de ellos debería destilarse o eliminarse antes de producir una
publicación científica. La página está en evolución y las conclusiones
y evidencias inobjetables de una versión pueden desinflarse y
convertirse en una curiosidad anecdótica en la siguiente.
-
Para facillitar las comparacines de una versión con otra, tengo ahora el
estudio archivado en el formato RCS, de
donde podrán obtener cualquier versión anterior mediante el comando
co (presente en cualquier distribución de Linux). Para
enterarse de las últimas modificaciones, puede leer la bitácora de cambios (preparada con
rlog).
-
Nota: Para los que quieran/puedan hacer otros estudios, al
final hay ligas a información y datos adicionales,
incluyendo el PREP completo, casilla por casilla, y los datos del
CONTEO DISTRITAL.
-
En otro tema... Parece fuera de lugar, pero no puedo dejar
de aprovechar la oportunidad de felicitar a Gerardo García Naumis y a
José Luis Aragón por su artículo, el cual
fue reseñado
en la primera plana de Nature News. Quizás
no se imaginan el enorme honor que significa para ellos, para la UNAM
y para la comunidad científica mexicana. ¡Felicidades!
Acaba de concluir la votación presidencial en México y el programa
de resultados electorales preliminares (PREP) puso a disposición del
público en general los datos parciales conforme eran
procesados. Durante la noche de la elección hice un pequeño programa
de cómputo
para capturar dicha información cada cinco minutos (más el tiempo
necesario para que el servidor me contestara). Aquí y aquí guardo copias de todas las páginas
capturadas. De ellas es de donde extraje la información que presento
abajo, aunque contienen mucha más información que podría serles
útil.
Un amigo (Guillermo Barrios del Valle, ¡gracias!) me hizo el favor de
organizar los primeros correos recibidos respecto al contenido de esta
página. Los puede consultar organizados como
cronológicamente
o como
hilos de discusión.
Asimismo, organizó un blog.
Nota:Alfonso Baqueiro (su correo está aquí y su blog aquí) escribió un programa muy
similar al
mío. Afortunadamente inició más temprano y concluyó más tarde su
captura sistemática de datos. Muy amablemente, me los hizo llegar, por
lo cual rehice las gráficas que contenía mi página original. Para
quienes estén interesados, junto a las nuevas gráficas añadí ligas a
las viejas gráficas y a los nuevos y viejos datos. ¡Gracias Alfonso!
Gracias también a otros lectores de esta página que me han mandado
datos. Desafortunadamente, no he tenido tiempo para incluirlos.
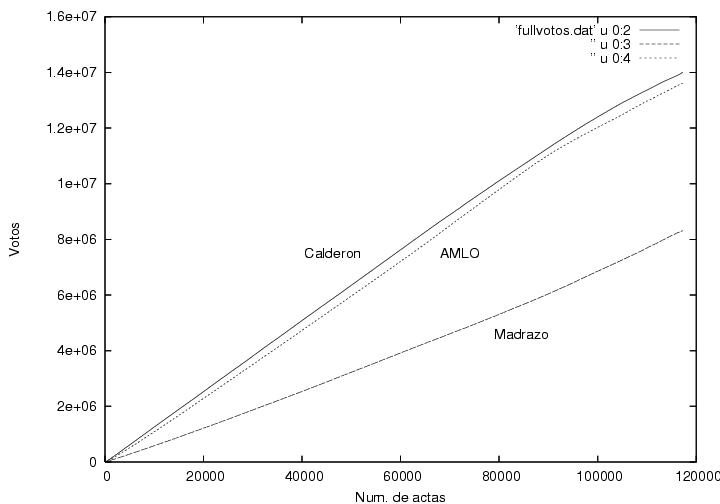
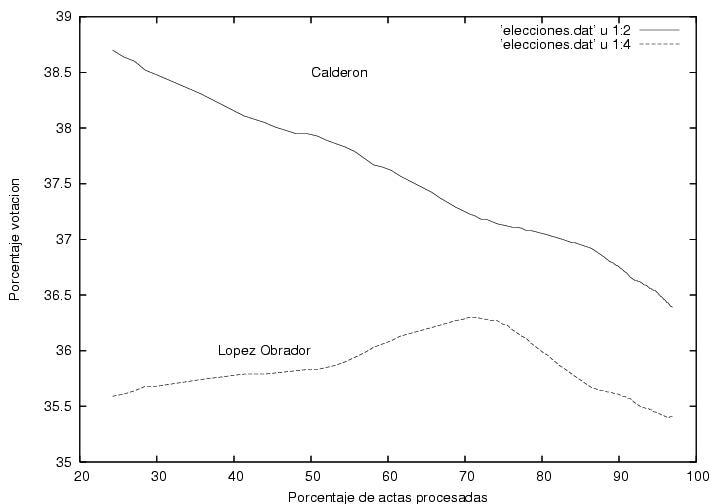
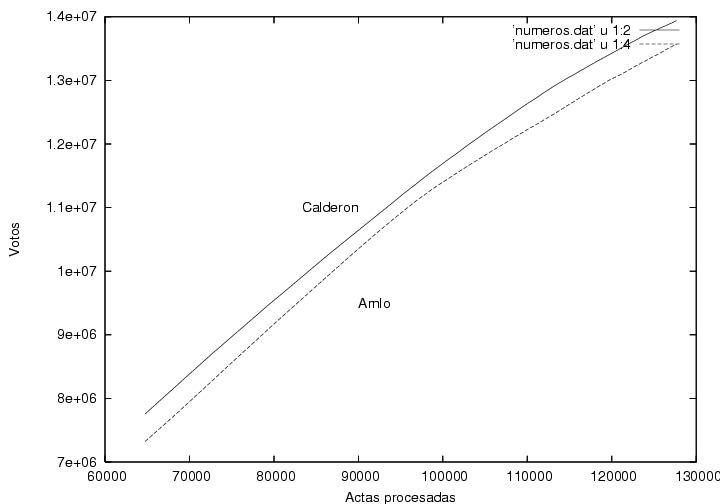
En la figura 1 se muestra a el porcentaje total de
la votación
logrado por Calderón y por AMLO como función del porcentaje de actas
procesadas. Empecé a capturar los datos pues me llamó la atención que
cuando apenas se había computado el 1% de las actas, Calderón iba
arriba por alrededor de 7% (según recuerdo) y gradual pero sistemáticamente su
porcentaje iba disminuyendo mientras el porcentaje de AMLO iba
aumentando. (las encuestas pre-electorales predecían un empate
técnico). Yo hubiera esperado un resultado muy fluctuante que
rápidamente se estabilizaría alrededor de los valores finales hacia el
final del conteo. Este resultado muestra que las primeras casillas
contabilizadas tuvieron resultados aparentemente atípicos y que le dieron a
Calderón una ventaja porcentual considerable que disminuyó conforme
avanzaba el conteo. Desgraciadamente no pude capturar los datos desde el
principio, pero el comportamiento de esta gráfica se puede extrapolar
cualitativamente hasta el momento en que se habían computado el primer
por ciento de actas. La pregunta es ¿por qué el inicio de las
actas computadas (quizás poco más de 1000 actas) tuvo un comportamiento
tan aparentemente atípico? (ver abajo).
Otra característica que me llamó la atención de esta figura es la
ausencia de fluctuaciones, aunque creo que eso es normal (ver abajo).
Finalmente, es curioso que la tendencia al alza de AMLO que se había
mantenido constante durante el 70% del conteo se revierte rápidamente
al llegar al 70%+ de las actas procesadas. Sin embargo, esto podría
explicarse si fuera que el voto rural, quizás mayoritariamente pro
PRI, hubiera empezado a llegar y a computarse cerca de las 2AM. Otra
posible explicación es la llegada de los resultados del
noroeste, retrasada debido a las diferencias de huso horario.
Advertencia:Modifiqué la curva correspondiente a Madrazo
añadiéndole 13% para poder mostrarla en la misma gráfica. Por lo
tanto, el lector deberá restar 13% del valor que lea en el eje vertical.
Figura 1
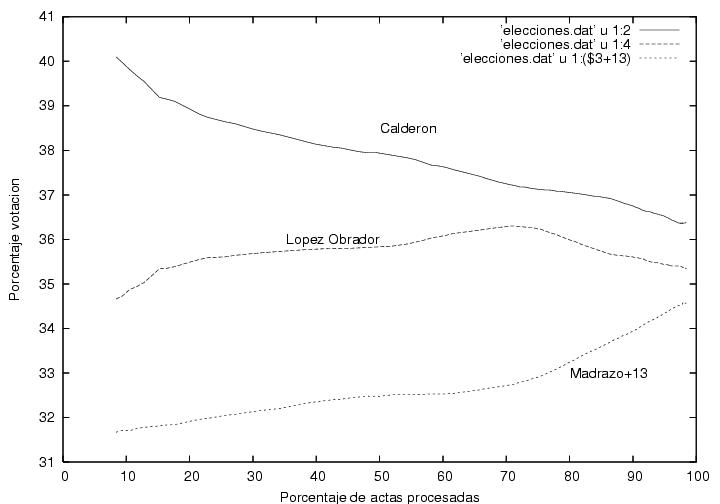
Gráfica previa
Datos
(Datos previos)
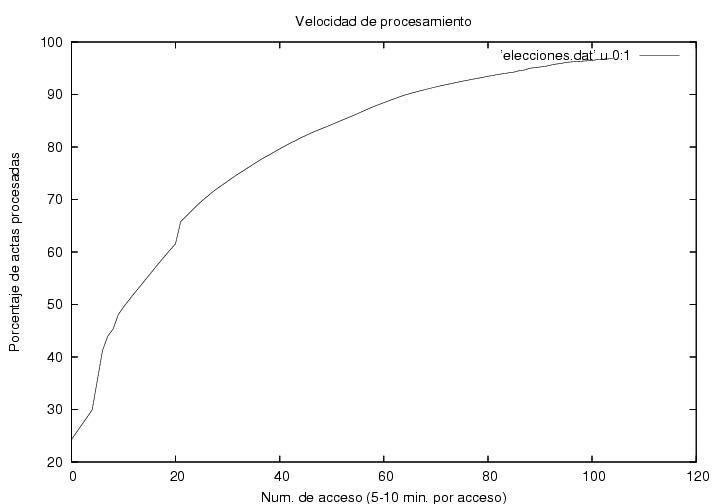
La figura 2 indica la velocidad de recepción y
proceso de actas. El
eje horizontal corresponde a el número de accesos de el programa,
diseñado para tomar una fotografía de la página del PREP cada 5
minutos, aunque dada la saturación del sistema, el tiempo de acceso
osciló entre 5 y 10 minutos. El eje vertical muestra el porcentaje de
actas procesadas. Claramente, hubo una desaceleración notable en la
velocidad de recepción y proceso, lo cual podría explicarse con el
arribo tardío del voto rural (ver arriba). Cerca del 31-avo dato
(correspondiente al 42-avo acceso (los números difieren pues descarté
datos repetidos, i.e., datos capturados antes de que se actualizara la
página del PREP))),
alrededor de la 1:01AM, hay un pequeño salto. Este se debe a que el
PREP no actualizó su página en poco más de 20 minutos. A
partir de ahí el ritmo de captura empieza a disminuir.
Poco después los datos de AMLO en la figura de arriba muestran un máximo e
inician un descenso. Antes del pequeño salto el comportamiento es
aproximadamente lineal, mientras que después decrece gradualmente. Una
explicación tentativa es que al principio del conteo las actas
arribaron a una velocidad mayor a la capacidad de proceso del PREP,
por lo cual se formó una cola. Hasta la 1AM el PREP estaría trabajando
a su máxima capacidad, que podemos estimar como la pendiente de la
región recta. De las páginas del PREP se
infiere que de las 21:30 a la 1:01 se procesaron cerca de 70,000
actas, por lo que la capacidad de proceso del sistema es de
aproximadamente 330 actas por minuto. Como hubo 300 distritos, esto da
un ritmo de un acta por minuto en cada oficina. Habiendo disminuido el ritmo de
llegada de las actas, las actas se procesarían inmediatamente conforme
fueran llegando y la velocidad de proceso aparente en la figura sería
simplemente la velocidad promedio de arribo.
Figura 2
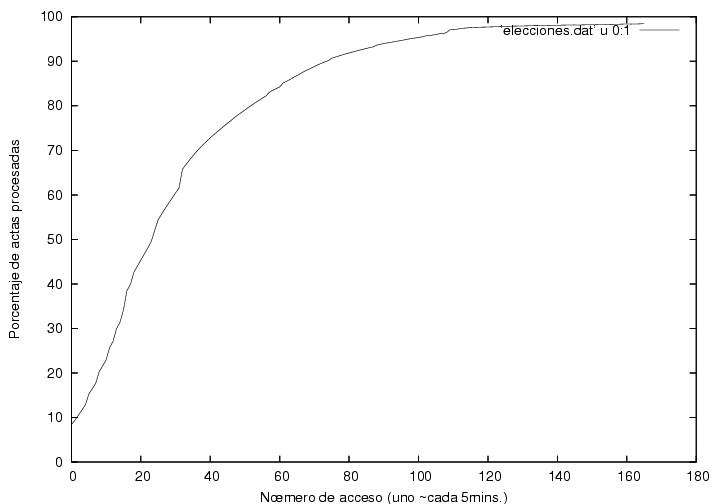
Gráfica previa
Datos (los mismos que para la figura 1)
(Datos previos)
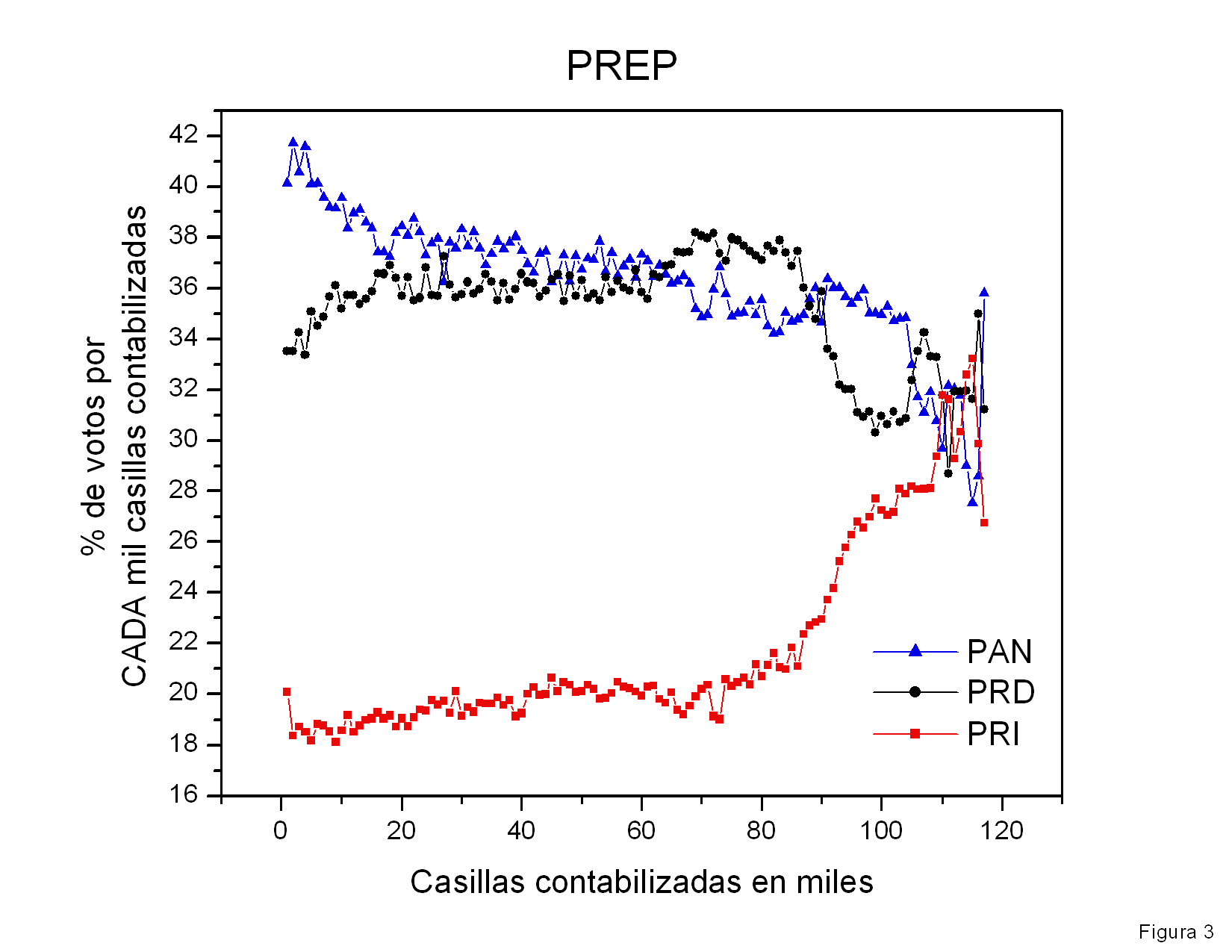
En la figura 3 se muestra el número total de votos obtenidos por los
tres candidatos como función del número de actas procesadas. Curiosamente,
Calderón y AMLO incrementan su número de votos aproximadamente con la
misma velocidad. Calderón y AMLO recibieron aproximadamente el mismo
número de votos por casilla computada. Es por ello que me pareció
atípico que en las primeras casillas computadas (no mostradas)
Calderón estableciera una fuerte diferencia que no se modificó
prácticamente en las demás casillas. Esta gráfica indica que el
acercamiento entre los porcentajes de la votación obtenidos por
Calderón y por
AMLO disminuyó al transcurrir el tiempo sobre todo por el aumento del número
total de votos computados y no por que hubiera disminuido la
diferencia de votos entre ellos (ver figura 6).
Figura 3
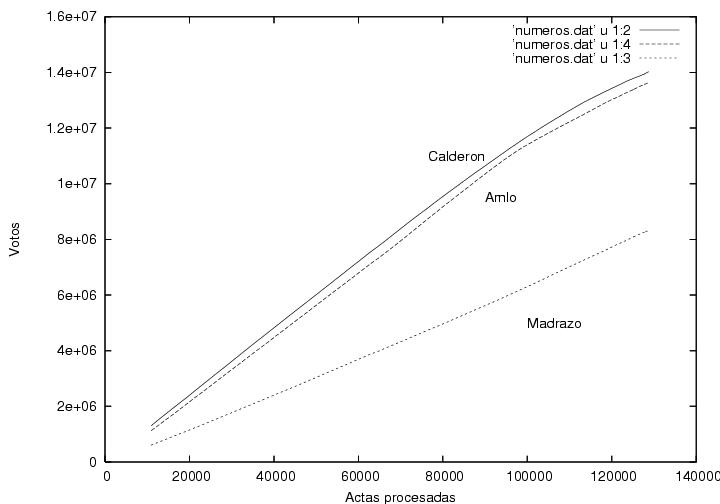
Gráfica previa
Datos
(Datos previos)
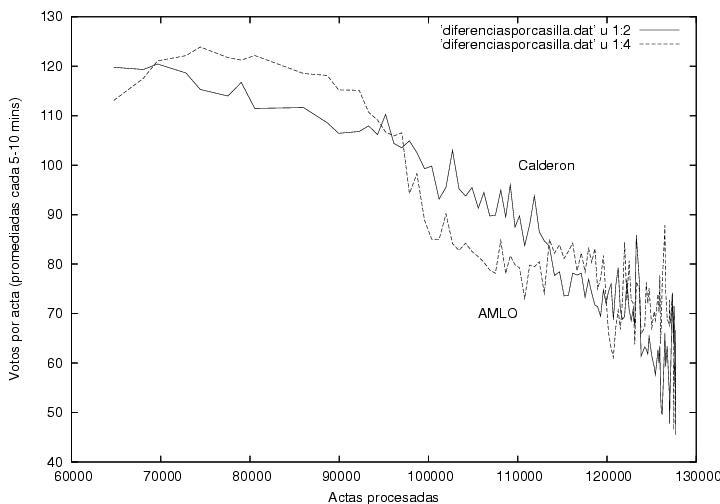
En esta figura muestro los votos obtenidos por
Calderón, AMLO y
Madrazo en
cada casilla, promediados sobre todas las actas que se procesaron en
los 5-10 minutos en que el programa obtenía una nueva radiografía del
proceso. Esta gráfica muestra fluctuaciones aparentemente normales
(ver arriba) y resultados muy similares para los candidatos durante el
tiempo que el programa estuvo capturando datos. Hacia el
final, el número de votos disminuye y las fluctuaciones aumentan, pero
podría ser consecuencia de la llegada de votos rurales, de comunidades
aisladas, cada vez más espaciados en el tiempo, mientras que los
tiempos de muestreo fueron uniformes. Hay sin embargo una anomalía
curiosa alrededor de las 61000-62000 actas procesadas, en que aparecen
estructuras similares correlacionadas en las curvas correspondientes a
los tres candidatos. Una anomalía que definitivamente requiere
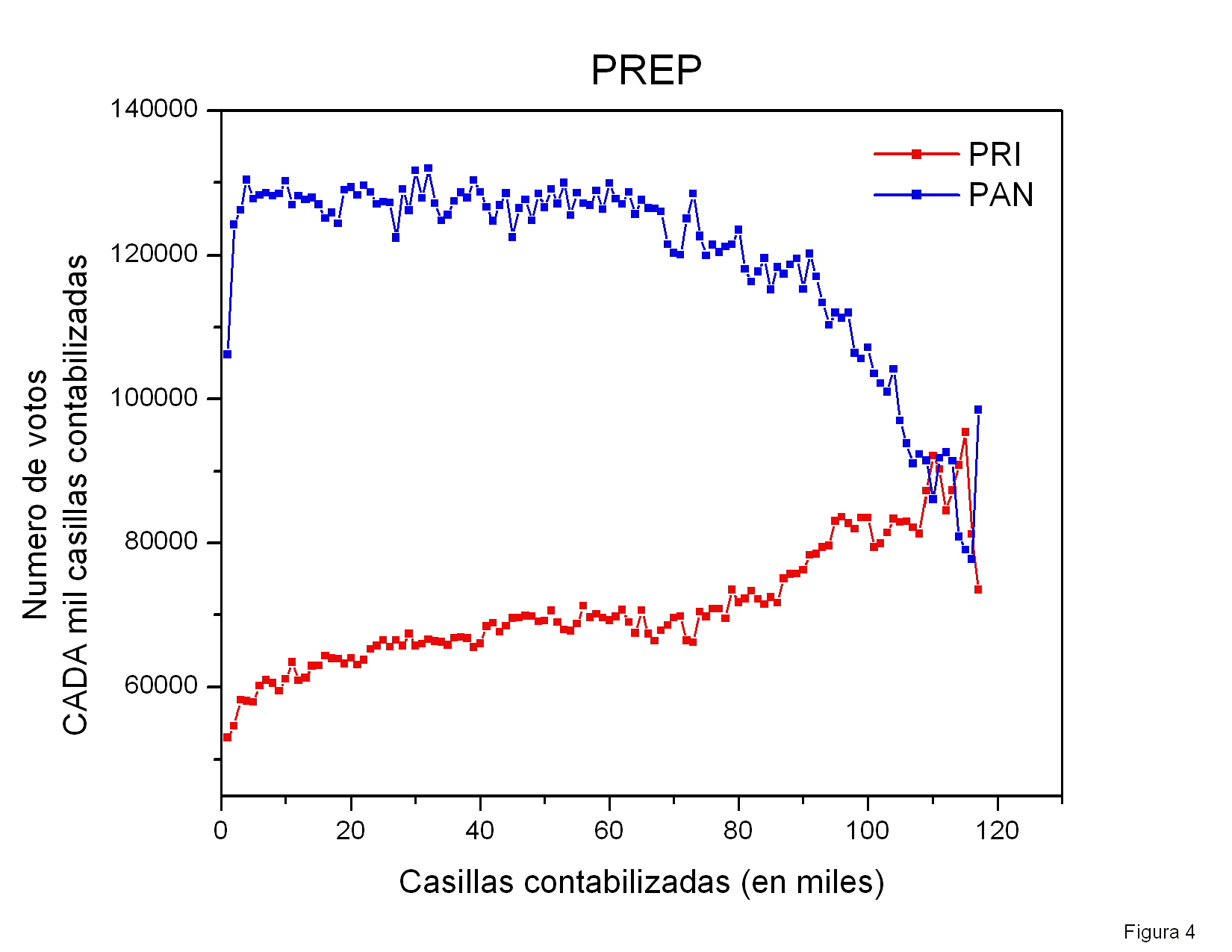
explicación corresponde a los datos hacia el final del conteo, donde se
ven fluctuaciones tan grandes que se salen de la gráfica. En esta
región se llegan a detectar más de 1200 votos por casilla. Creo que
ninguna casilla debía haber recibido más de 750 votos. Peor aún,
algunos datos indican un número de votos por casilla
negativos. Estudiando con detalle una de éstas anomalías a través de las
páginas del PREP, encontré que el número de
actas procesadas a las 12:39 era de 127772, mientras que hora y media
después, a las 14:03, el número disminuyó abruptamente, situándose en
127752, por debajo de su valor a las 12:39. Durante mi
reducción de datos ordené los registros de acuerdo al número de actas
procesadas. Si las hubiera ordenado cronológicamente, ya sea por la
hora de captura del registro o por la hora de corte estampada por el
PREP, las inconsistencias descritas arriba hubieran sido mucho más
grandes.
Este es un error que sólo
podría ser explicado por personal del PREP.
Figura 4
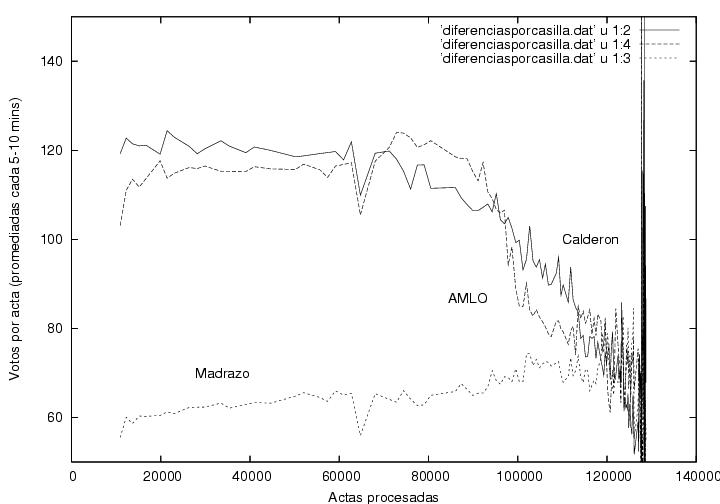
Gráfica previa
Datos
(Datos previos)
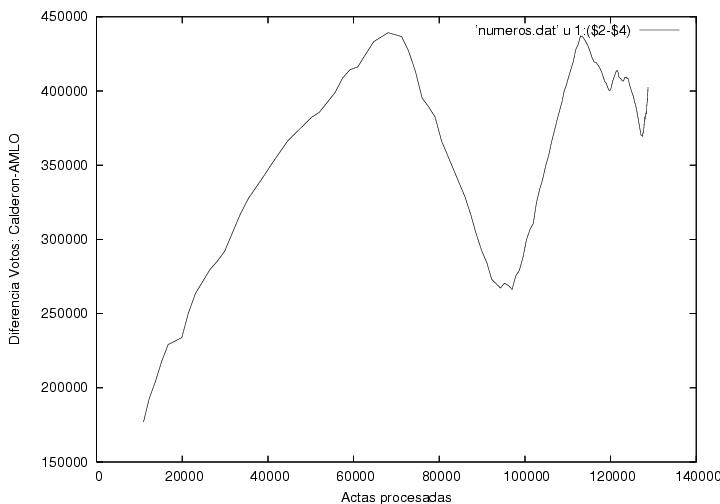
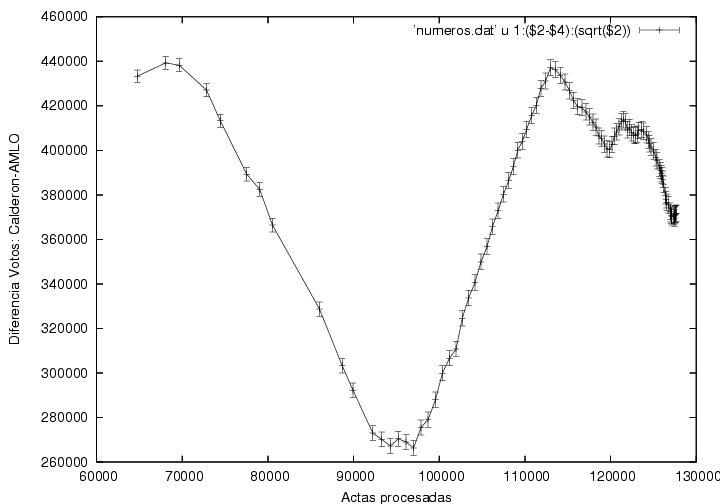
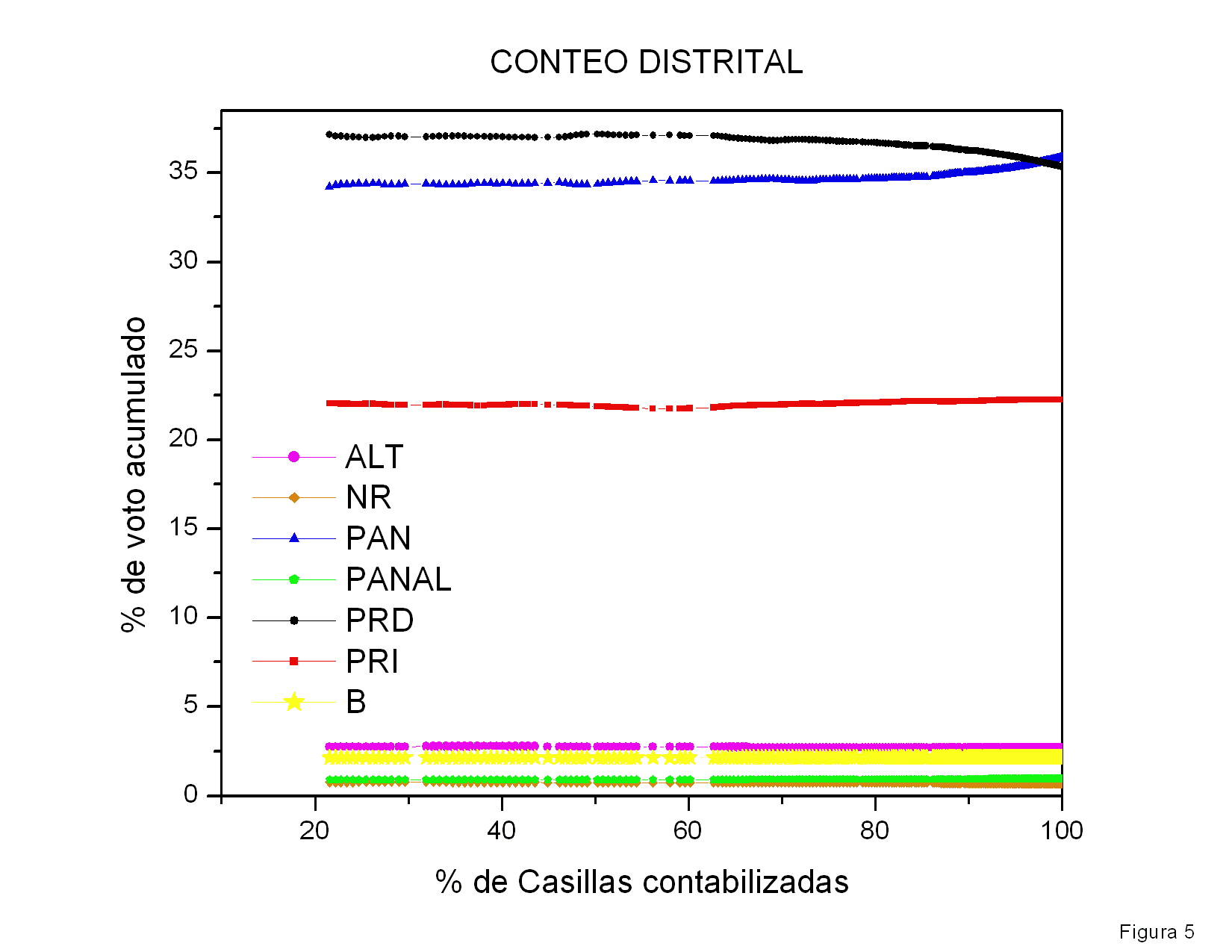
La figura 5 muestra la diferencia entre los votos
atribuidos a Calderón y a AMLO como función del número de actas
procesadas. La curva muestra claramente tres regiones: una subida
seguida de una caída, otra subida y finalmente algunas
fluctuaciones. Las primeras tres regiones muestran pendientes bastante
constantes y las transiciones de una a otra son bastante
abruptas. El origen de dichas transiciones debe ser explicado.
Quité de esta gráfica las barras de error que mostraba mi
figura previa pues un colega me hizo ver que mi estimación de la
dispersión esperada era incorrecta. Aún no hago un análisis de las
fluctuaciones de estos datos para checar si son o no anómalos.
Figura 5
Gráfica previa
Datos (los mismos que para la figura 3)
(Datos previos)
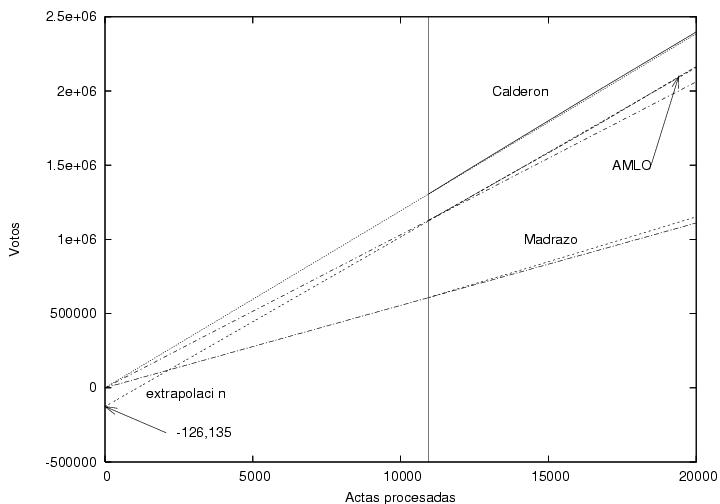
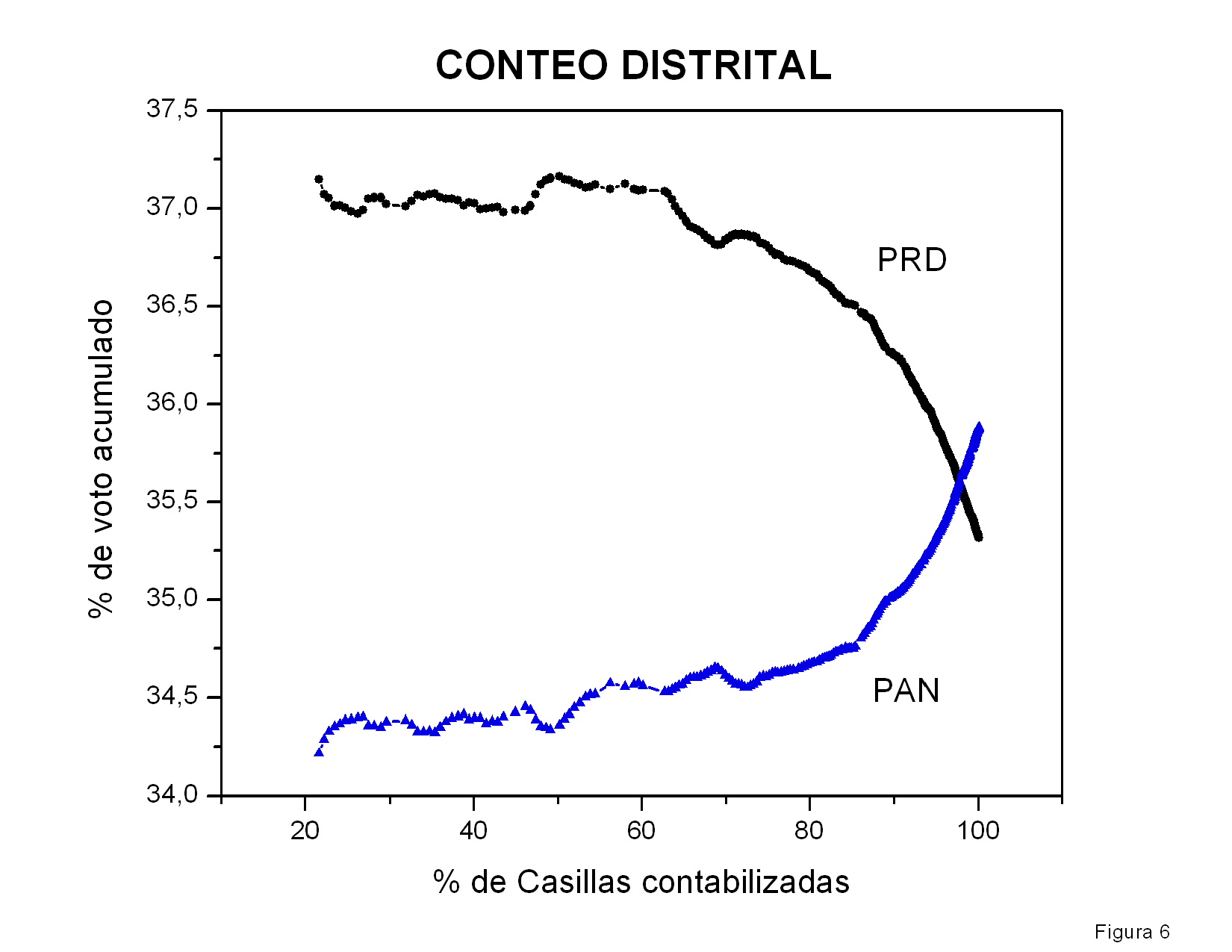
En esta figura muestro los datos iniciales de la
figura 3,
correspondientes a las primeras 20,000 actas capturadas. Con una línea
vertical he marcado desde donde tengo datos capturados
sistemáticamente (con 10943 actas procesadas). De ahí a la derecha se
muestran los datos capturados
para los tres candidatos. Los tres candidatos muestran una tendencia
lineal sin fluctuaciones aparentes, quizás por haberse acumulado ya un
número grande de votos, del orden de un millón. Del lado izquierdo de
la línea vertical muestro tres líneas rectas (no rotuladas) que parten
del origen y terminan en el primer dato capturado para cada
candidato. Extrapolé dichas líneas hacia el lado derecho de la gráfica
para compararlas con los datos iniciales de los candidatos. En el caso
de Calderón, los datos del PREP y la línea recta que parte del origen
son prácticamente indistinguibles. En el caso de Madrazo hay una
ligera diferencia, lo cual refleja que la votación por acta hacia
Madrazo iba aumentando gradualmente, lo cual es consistente con la
figura 4. Sin embargo, la línea recta correspondiente a AMLO se aleja
bastante más rápidamente de los datos obtenidos del PREP. Eso hace
suponer que en las primeras 10,000 casillas la votación por AMLO fue
significativamente menor que en las subsiguientes. La pendiente
inicial correspondiente a la curva de AMLO tuvo que ser notablemente
menor que la pendiente subsiguiente, pues obviamente los datos
deberían pasar por el origen. Es sin embargo interesante hacer
una extrapolación de los datos de AMLO. Empleando los datos del
intervalo [10,000:20,000] hice una extrapolación lineal. La ordenada
al origen es -126,000. Curiosamente, dicho número es muy cercano a
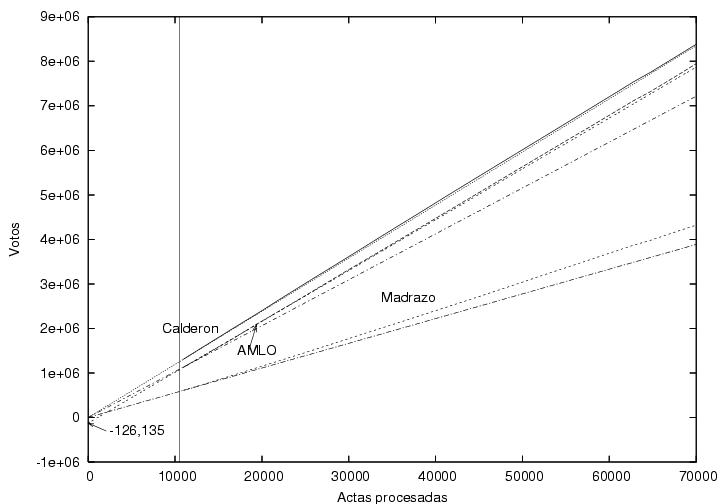
(menos) el número total de casillas. La figura que le sigue (figura 7)
es la misma que la figura 6 pero extendida hasta 70,000
actas. Me llama la atención que el ajuste lineal a los datos iniciales
de AMLO, empleando para el mismo sólo los datos entre 10,000 y
20,000, es prácticamente indistinguible de los
resultados correspondientes del PREP sobre todo el rango. ¿Por qué la
extrapolación hacia el lado derecho de la gráfica es tan buena,
mientras que la extrapolación hacia el lado izquierdo es tan mala?
En un escenario de mucha especulación sobre conspiraciones, estos datos
podrían interpretarse de la siguiente manera:
Pareciera haberse restado un voto a favor de AMLO por cada una de las 130,000
casillas durante la acumulación de los resultados.
Seguramente, se podrían encontrar otras explicaciones. Será interesante
saber por qué el voto de las primeras 10,000 casillas fue tan distinto
al de las 60,000 casillas subsiguientes, el cual habíamos visto en la
figura 5 que es muy distinto al de los que siguieron.
Urge procesar los datos correspondientes a las primeras 10,000
casillas. Un lector de esta página acumuló datos manualmente desde las
8:00PM. Están disponibles aquí.
En cuanto tenga tiempo intentaré añadir esos datos a la figura 6.
Figura 6
Datos (los mismos que para la figura 3)
Figura 7
Datos (los mismos que para la figura 3)
Datos de la base de datos por casilla
Empecé (7/VII/06) a procesar la base
de datos del PREP y me encontré con algunas dificultades.
- El número de registros que contiene es 117,287. Como no he tenido
tiempo de seguir las noticias no estoy seguro en cual de las cuentas
entrarían los 13,200 registros faltantes necesarios para completar las
130,488 reportado en las páginas del
PREP durante el conteo.
- Ya conseguí también las bases de datos de senadores y diputados. Contienen 120,032 y 120,091
registros respectivamente. ¿Por qué difieren en alrededor de 2700
registros de la base para presidente?
- Además de los registros faltantes, hay otros 22,538 que tienen un
asterisco ('*') en alguno de los campos numéricos. El problema me
saltó a la vista al tratar de checar la consistencia de los datos
numéricos. Aquí guardé la base de
datos correspondiente a estos registros incompletos.
- Eliminando los registros con asteriscos, hay 27,073 registros que
considero inconsistentes, pues la suma de los campos
PAN, ALIANZA_POR_MEXICO, POR_EL_BIEN_DE_TODOS, NUEVA_ALIANZA,
ALTERNATIVA_SOCIAL_DEMOCRATA, NO_REGISTRADOS y NULOS no es igual al
número de BOLETAS_DEPOSITADAS. Aquí guardé la base de datos
correspondiente.
- El NUMERO_VOTANTES siempre es
consistente con la suma de PAN+ALIANZA_...(tal vez porque así se
defina).
Verifiqué que el NUMERO_VOTANTES se conserva consistente aún si
reemplazo todos los asteriscos por ceros en lugar de eliminarlos. Por
lo tanto, en los análisis subsiguientes realizo dicha modificación.
- Reemplazando los asteriscos por ceros, obtengo que la suma de
las BOLETAS_DEPOSITADAS es 35,876,783 y la de
los NUMERO_VOTANTES es 38,516,730, por lo cual parece haber 2,639,947 más votos
que boletas depositadas en las urnas. Por otro lado, si elimino los
registros con asteriscos, obtengo 35,876,783 boletas depositadas y
36,100,471 votantes, 223,688 más votantes que boletas depositadas.
La figura 8 muestra el porcentaje de la votación
obtenida por cada candidato como función del tiempo. El tiempo está
medido en minutos transcurridos desde el inicio del conteo, el cual
tomé como la hora de recepción de la primera acta (18:35). Esta
gráfica es similar a la figura 1, pero graficada
como función del tiempo en lugar del número de actas
procesadas. Además, está figura fue construida con los datos detallados del prep, casilla por
casilla, y no con los que capturamos via la red, por lo cual se puede
mostrar el conteo completo. Inicialmente, había una fuerte ventaja
para Madrazo, seguido de Calderón y finalmente de AMLO. Durante la
primera hora hay fuertes fluctuaciones, lo cual era de esperar, y las
curvas se cruzan algunas veces. Los
datos se estabilizan gradualmente hasta que pasadas dos horas y media
las fluctuaciones se vuelven marginales. Me imagino que el PREP no
reportó los datos iniciales sino que esperó a que estos se hubiesen
estabilizado.
Figura 8

Datos
La figura 9 es similar a la figura
8, pero graficada como función del número de actas
computadas. Como muy al inicio las actas llegaron muy espaciadas, en
esta gráfica no se aprecia la región fluctuante que es muy
claramente visible en la figura 9; queda
comprimida en el extremo izquierdo. Para poder mostrar más claramente
la estructura de las distintas curvas, reduje el rango de la gráfica
(perdiendo algunos de los primeros puntos) y le añadí 13% a Madrazo,
que el lector debe restar, como en la figura
1. Los datos parecen concordar con los de la figura
1, pero muestran un nivel mayor de fluctuaciones. El máximo en el
porcentaje de votos para Calderón se da cuando
ya había 4500 actas computadas y casi un millón de votos.
Figura 9
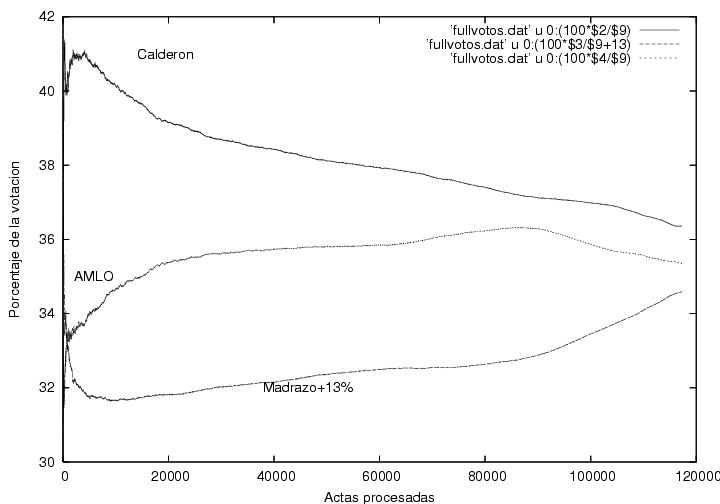
Datos (como en la figura 8).
Esta figura es análoga a la figura 2 pero como función del tiempo y no como
función de mi número de acceso (similar al tiempo). Las conclusiones
que se pueden derivar de ella son esencialmente las mismas. La
capacidad del PREP es de aproximadamente un acta por distrito cada
minuto. Esta gráfica es mucho más suave que la figura
2 y, como empieza mucho antes, muestra cómo la velocidad de arribo
de la información se incrementó gradualmente durante los primeros 200
mins. del conteo. Para poder observar esta región, multipliqué en ella
los datos por un factor de 1000. Las oscilaciones en la parte lineal de la figura 2 están aquí ausentes, y en particular, no se
ve el brinco de alrededor de la 1:00AM que previamente me había llamado la
atención. Quizás podría deberse a que el momento para realizar cada
actualización de la página del PREP estaba bajo control humano, no de
un código de computadora, y el encargado se fue a tomar un café
mientras el sistema seguía capturando datos de manera uniforme.
Figura 10

Datos (como en la figura 8).
La figura 11 muestra los votos obtenidos por cada
uno de los candidatos como función del tiempo de
conteo. Cualitativamente, la figura sigue las tendencias del número
total de votos.
Figura 11

Datos (como en la figura 8).
Esta figura muestra los votos como función del
número de actas procesadas. A diferencia de la figura
11, y de manera similar a la figura 3, en ésta el comportamiento
es básicamente lineal para los tres candidatos durante la mayor parte
del rango, con ligeras modificaciones visibles al principio y al final.
Figura 12
Datos (como en la figura 8).
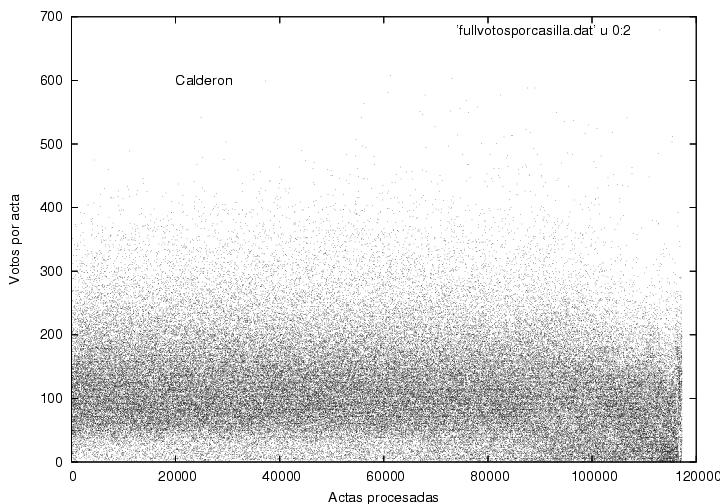
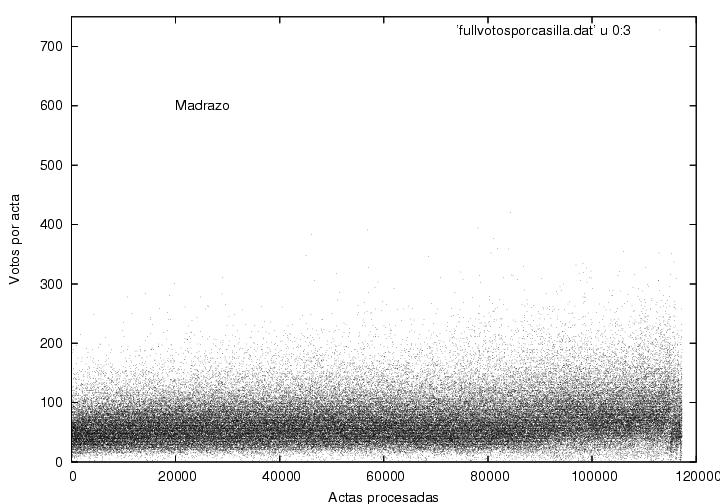
Las figuras 13, 14 y 15 muestran el voto obtenido en cada acta como
función del número de proceso de dicha acta para Calderón, Madrazo y
AMLO respectivamente. Cada punto en la gráfica corresponde a un
acta. Las regiones obscuras corresponden a resultados frecuentes y
deben ser cercanas a las votaciones promedio (como las
mostradas previamente en la figura 4. El ancho de
dichas regiones corresponde a las
dispersiones alrededor de los valores promedio. Qué tanto difieran dichas
regiones de ser franjas horizontales es una medida de las variaciones
de las preferencias electorales entre el electorado que fue contado
antes vs. después. Debe ser interesante (y fácil) rehacer este diagrama
para observar los promedios y variaciones de la preferencias de
acuerdo a la zona geográfica. Cuidado: Estas figuras pueden
mostrar una textura interesante pero que puede no ser
significativa. El voto en cada casilla es un número entero y puede
aparecer un batimiento entre las posiciones ocupadas por los puntos
que representan los datos y los pixeles de la pantalla de su computadora.
Es interesante notar que las figuras correspondientes al PAN muestra
una franja relativamente ancha, mientras que la del PRI es una franja
muy angosta. ¿Representará esto el llamado voto duro del PRI?
Por otro lado, la figura correspondiente al PRD muestra una franja
angosta pero con muchos puntos que caen arriba de dicha franja. Para
AMLO la distribución parece ser mucho más asimétrica que para sus
contendientes. Las
franjas claras en la parte baja de las gráficas de Madrazo y de AMLO
muestran que en casi todas las casillas obtuvieron al menos una o dos
decenas de votos. Por otro lado, la franja clara correspondiente a
Calderón está muy tenuemente marcada y parece desaparecer después de
la 90,000-ava casilla, lo cual implicaría que en un número significativo de
casillas recibió pocos o nulos votos. La franja clara correspondiente
a AMLO no desaparece, pero se adelgaza visiblemente en dicha
zona. Pareciera ser que entre las últimas actas recibidas, muchas
provinieron de regiones muy polarizadas en las que barría ya fuera uno
o el otro de los dos contendientes principales.
¿Por qué son tan distintos los
diagramas para cada candidato? ¿Por qué cambia el comportamiento de
los datos de Calderón y de AMLO después del acta 90,000?
Figura 13
Datos.
Figura 14
Datos.
Figura 15

Datos.
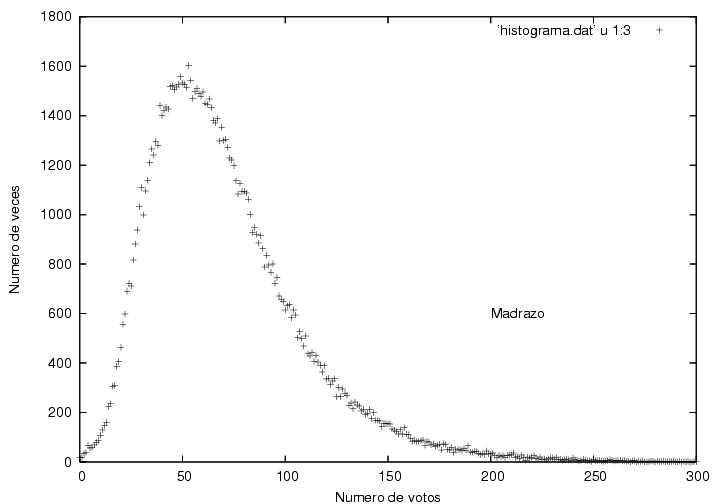
Para visualizar la distribución de votos de los candidatos principales
de manera más clara, en las figuras 16, 17 y 18
muestro los histogramas correspondientes a los datos de las figuras
13, 14 y 15. Cada punto en esta gráfica está determinado
por dos números: uno (el que leemos en el eje horizontal debajo de él)
representa un posible número de votos; el otro (el que leemos en el
eje vertical a su izquierda) representa en cuantas actas se reportó
ese número de votos.
La figura 16,
correspondiente a Madrazo, muestra un comportamiento muy común en
procesos con cierta aleatoriedad. Tiene un máximo que resulta estar
en 53 votos con una altura de 1603 actas, i.e., obtuvo 53 votos
en 1603 de las cerca de 117000 actas.
A ambos lados del máximo, el número de actas
disminuye gradualmente con algunas fluctuaciones. Como el número
máximo de votos que podría haber obtenido es mucho mayor que 55 (del
orden de 700), mientras que el número mínimo de votos que pudo haber
sacado (0) es relativamente cercano a 55, el decaimiento hacia la
derecha es más lento que el decaimiento hacia la izquierda, i.e., su
distribución es unimodal (tiene un pico), y corresponde a
una curva suave ligeramente asimétrica. Se ve cualitativamente como la famosa
campana de Gauss pero deformada. Apenas obtuvo cero votos en un
manojo de actas.
Figura 16
Datos.
Los datos correspondiente a AMLO se ven
bastante peculiares. Tienen un
máximo en una posición cercana al máximo de Madrazo, aunque con una
altura menor. A la derecha del máximo muestra
un decaimiento suave mucho más extendido que el de Madrazo pero
cualitativamente similar. Lo que me llama mucho la atención es que el
decaimiento hacia la izquierda del máximo no parece ser una curva
suave sino más bien podría describirse muy bien por una burda línea
recta, cuya ordenada al origen estaría entre 25 y 50 actas donde
habría obtenido 0 votos. De hecho, obtuvo 0 votos en 45 casillas.
A diferencia de la curva típica de Madrazo, la de
AMLO tiene un quiebre abrupto en el máximo. Las curvas usuales suelen
empezar con curvatura positiva, la cual cambia de signo antes de llegar al
máximo y vuelve a cambiar de signo a medio descenso. Esta curva podría
describirse como una curva típica a la que se le cortó una parte.
Figura 17
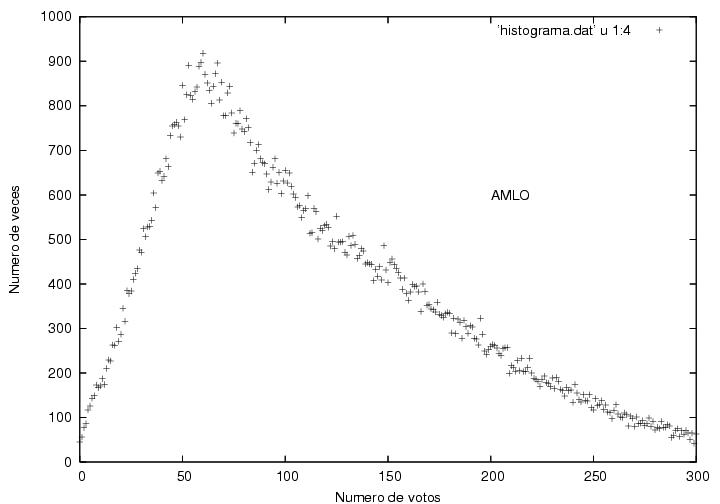
Datos.
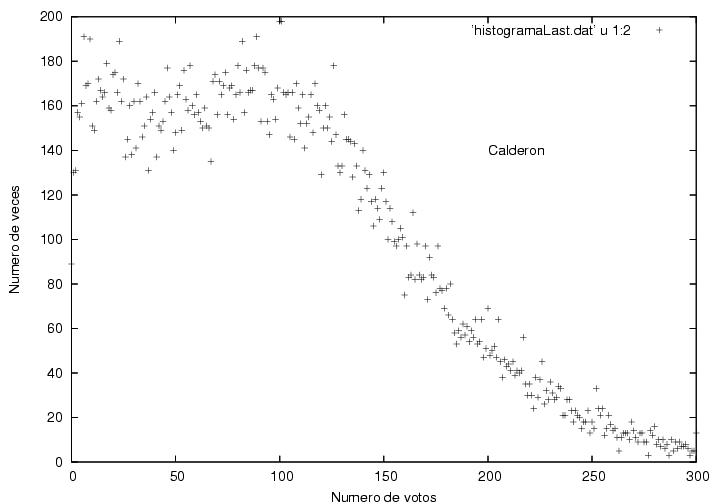
Los datos correspondientes a Calderón son más
curiosos aún. Tienen un
máximo muy ancho cercano a los 80 votos por acta con una altura
cercana a 700 actas. Hacia la derecha tiene un decaimiento extendido y
suave cualitativamente similar al de AMLO. Hacia la izquierda, el
decaimiento comienza de una manera normal, con la misma forma que el
de Madrazo, pero cambia su
comportamiento pues aparece un segundo pico con un máximo cerca de 15
votos. La mayor parte de la contribución a este segundo pico se
debe a las actas que más tarde llegaron al IFE. Para ilustrar esta
afirmación, en la figura 19 se muestra el
histograma de la votación de Calderón correspondiente a las últimas
30,000 actas procesadas. Es sorprendente que la diferencia con la figura 18 sea tan grande. Era de esperar una curva
similar aunque con una altura menor y con
fluctuaciones más visibles por tener menos datos. En lugar de eso,
vemos que la parte derecha de la curva ha sido muy abatida, mientras
que la parte izquierda apenas empieza a cambiar su tamaño.
Estos datos tienen la forma típica que corresponde a
la suma de dos distribuciones distintas, cada una con sus propias
características. En este caso una describe la banda gris
horizontal previamente discutida y que se extiende a todo lo ancho
de la figura 13. La segunda distribución
corresponde a la región anómala que muestra la figura 13 sobretodo a partir del acta número
90,000. Las dos distribuciones parecen cruzarse alrededor de los 30
votos. Podemos eliminar la subjetividad en esta estimación, usando el
mínimo de la distribución, el cual está en 29 votos.
Consideremos un punto tomado de la figura 18,
correspondiente a H actas con N votos cada una. Ese
punto contribuye HxN votos en total. Sumando dichos
productos sobre todos los puntos desde que N es igual a cero y
hasta que sea igual a 29, donde se cortan las dos distribuciones,
podemos estimar el número total de votos que obtuvo Calderón a partir
de sumar la segunda distribución anómala: el número de actas en
que Calderón
obtuvo 29 o menos votos fue de 9914; el número total de votos
contenidos en dichas actas fue de 149,329.
Una forma más cuantitativamente aceptable de hacer el cálculo previo
es mediante un ajuste en que se proponga cierto número de curvas
tomadas de una familia tal y como la familia de curvas Lorentzianas,
se optimizan los parámetros de cada una de las curvas de manera que su
suma sea la mejor aproximación posible a los datos, y finalmente se
integran las funciones analíticas resultantes para obtener el
número de actas y el número de votos contribuidos por cada una de las
distribuciones. Este trabajo está en curso con la colaboración de un
colega.
Figura 18

Datos.
Figura 19
Datos.
Para que el lector lo pueda comparar, a continuación muestro los
histogramas correspondientes a Madrazo y a AMLO calculados con las últimas 30,000 actas. En
ambos casos, la forma del histograma
es igual a las correspondientes a los datos completos, 16 y 17, solo que escaladas
por contener menos datos.
Figura 20

Datos.
Figura 21
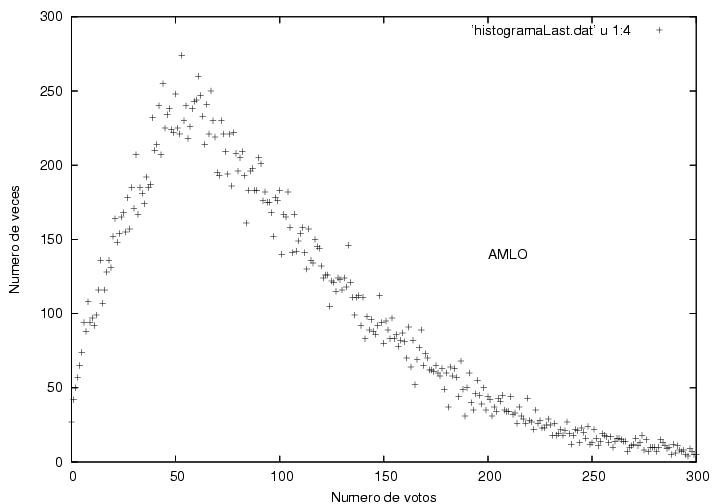
Datos.
Las
puede consultar aquí y aquí.
Un amigo (Jaime Ruiz) me mandó esta y esta gráfica, preparadas con mis mismos
datos, pero sobre un rango más grande. La primera muestra que Campa tiene una distribución
ordinaria y que en la payor parte de las casillas sacó menos de 10
votos. Por otro lado, la distribución de Patricia Mercado parace ser
una suma de dos distribuciones ordinarias, una que apenas se extiende
hasta 5 votos y otra hasta 30 votos.
Más importante me parece las curvas
corresondientes a Calderón, Madrazo y AMLO en la figura 21.2. Estas son las mismas que
mis figuras 16, 17 y 18, pero superpuestas y graficadas en un rango
mayor. En la figura se ve claramente que las curvas corresondientes a
Calderón y a AMLO son my cercanas entre sí y siguen un comportamiento
normal en la región correspondiente a actas con más de 180 votos cada
una. Sin embargo, cerca de 180 votos, la curva corerspondiente a AMLO
cambia abruptamente de pendiente situandose a la izquierda de
este punto por debajo de Calderón. No he podido encontrar una
explicación para este cambio abrupto. La parte superior de la curva de
Calderón se ve muy plana y ancha comparada con la de los otros dos
candidatos. Finalmente, es donde se vuelven a encontrar las dos
distribbuciones donde aparece la anomalía inferior de la curva de
Calderón, la cual tiene un cambio abrupto de pendiente volviéndose
horizontal en el extremo izquierdo. Note que el detalle en el extremo izquierdo de la curva
correspondiente a Patricia Mercado en la figura 21.1 se puede interpretar mediante la suma de dos
curvas suaves, mientras que el detalle a la izquierda de la curva de
Calderón aparece de un manera abrupta y poco natural.
Figura 21.1
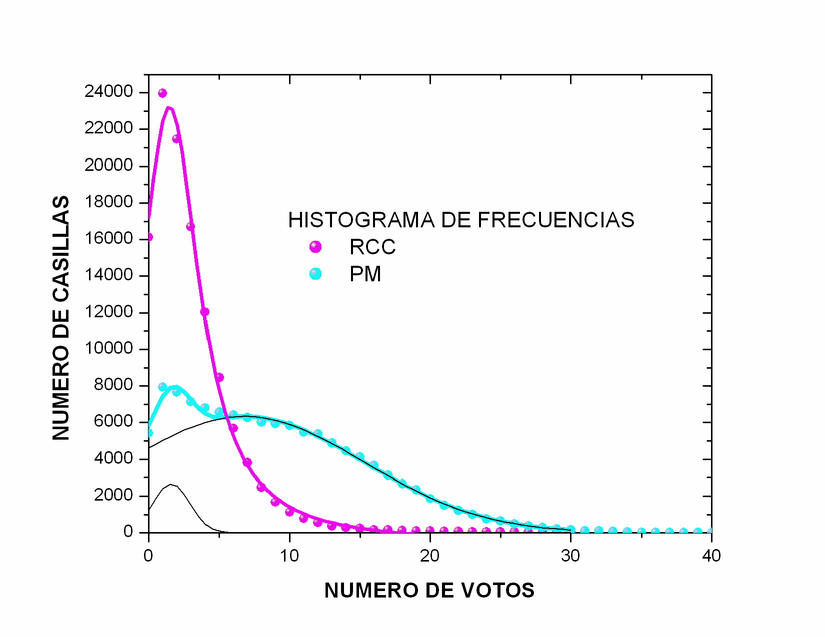
Datos.
Figura 21.2
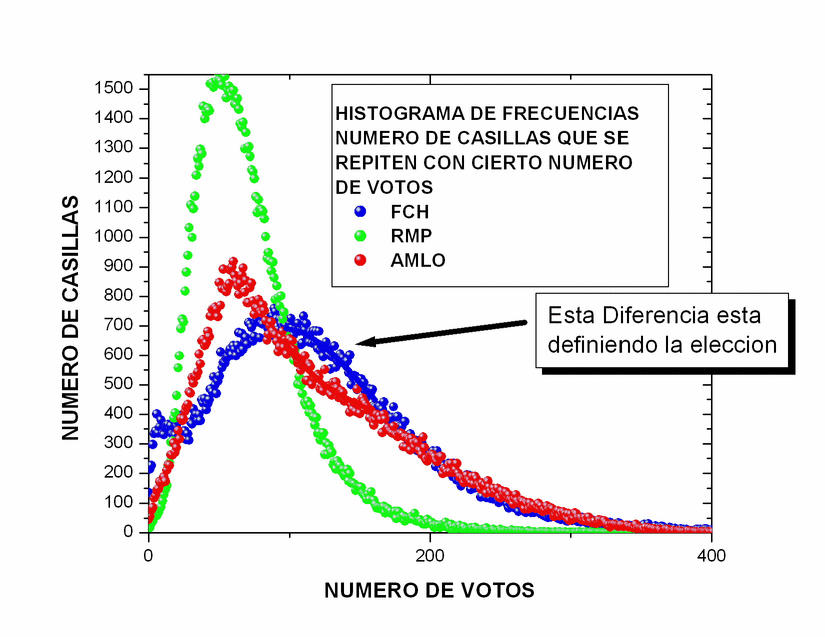
Datos.
Es importante conocer las estadísticas de la diferencia de votos entre
Calderón y AMLO para poder entender la estructura de las figuras
17, 18 y 21.2. En la figura 21.5
muestro un histograma de esta diferencia. A lo largo del eje
horizontal se hallan la ventaja que Calderón podría haberle llevado a
López Obrador en alguna casilla. El eje vertical indica el número de
casillas en los que obtuvo precisamente esa diferencia. Si la
diferencia es negativa, simplemente significa que en las casillas
correspondientes López Obrador obtuvo más votos que Calderón.
A pesar de lo extrañas que son las curvas mostradas en la figura 21.2, el histograma de
las diferencias de votos tiene aparentemente una forma simple y
común. Es muy poco probable que las diferencias sean demasiado grandes
y conforme se hacen pequeñas dicha probabilidad aumenta gradualmente,
mostrando un máximo cercano a 0 votos de diferencia. Cualitativamente,
la curva parece una gaussiana normal. Sin embargo, los resultados
cerca de dicho máximo tienen un comportamiento muy distinto al de una
curva normal. Para guiar el ojo, hice un ajuste Gaussiano a todos los
datos que se hallan debajo de de la marca de las 250 actas. El ajuste
fue de la forma N=A exp(-B(V-C)^2), donde N representa el numero de
veces que Calderón le llevo V votos de ventaja a AMLO y A= 432.819+/-
4.352, B = 4.15445x10^{-05} +/- 3.944x10^{-07} y C = 0.126841+/-
0.3256 son los
parámetros del ajuste. Notamos que el ajuste es bueno
(no excelente) en la parte baja de la distribución, pero que
es pésimo en la parte alta. Intenté hacer un ajuste a todos los datos
en vez de emplear aquellos con N<250, pero la distorsión para N>250
es tan grande que el ajuste no fue resultó en ninguna parte. De los
parámetros de la distribución notamos que su centroide está desplazado
una distancia muy pequeña hacia la derecha, es decir, que en promedio
Calderón le hubiera ganado a AMLO en 0.1 votos por casilla si
la distribución hubiese sido la gaussiana ajustada arriba, i.e.,
hubiera ganado la elección por 10,000 votos aproximadamente. Sin
embargo, su ventaja fue mucho mayor gracias a la deformación en la
cima de la distribución. La distribución tiene un cambio discontinuo
de pendiente cerca de V=-100. ¿Por qué la distribución es
aproximadamente gaussiana en la mayor parte del intervalo? ¿Por qué la
distorsión en la parte alta de dicha distribución? ¿Por qué el cambio
de pendiente es abrupto al llegar a dicha distorsión?
Figura 21.5

Datos.
Parece ser que la distorsión en la parte alta de la distribución
mostrada arriba es la responsable del aparente
triunfo de Calderón. Para cuantificar su contribución, en la figura 21.6 muestro la diferencia entre los datos
del PREP y la curva ajustada. Para diferencias de votos menores a -100
y mayores a 100 o 150, el resultado es el esperado, i.e., los puntos
se distribuyen más o menos simétricamente alrededor de cero (línea
horizontal). Sin embargo, en la región entre -100 y 0 los datos están
sistemáticamente desplazados hacia abajo y entre 0 y 100 están
sistemáticamente desplazados hacia arriba, con un mínimo cerca de -50
y un máximo cercano a 80. Es decir, hay menos casillas en las que AMLO
gano por poco que las que seguirían de la distribución
normal, y hay más casillas donde Calderón ganó por pocos votos que las
que predice la distribución normal. Como si los datos de las actas con
poca diferencia migrado hacia la derecha. ¿Cual es el origen
de la bajada y
subida?
Figura 21.6

Datos.
La figura 22 es similar a la figura 6 pero elaborada con la base de datos
detallada. Se muestran tres curvas que corresponden a las votaciones
obtenidas por los tres candidatos principales en el intervalo
[0:20000], i.e., completando los datos que en la figura 6 sólo
podíamos adivinar. Desde luego, las tres curvas pasan por el
origen. Se muestran otras tres curvas que fueron obtenidas de un
ajuste lineal a los datos del rango [10000:20000]. Los parámetros de
dicho ajuste se pueden leer en la llave de la figura (disculpas por no
haberlas puesto en el orden previo): las pendientes son 126.731,
63.1543 y 120.122 y las ordenadas al origen son -7143, -49301 y
-121637 para Calderón, Madrazo y AMLO respectivamente. La calidad del
ajuste se puede apreciar al extrapolarlo hacia
toda la gráfica aquí.
Figura 22
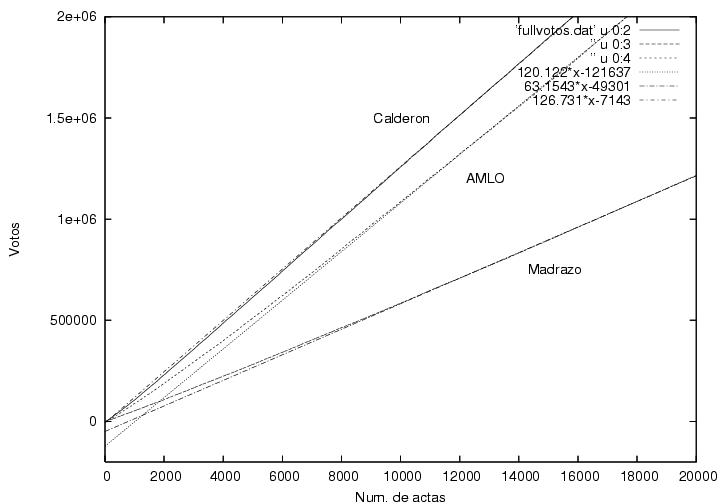
Datos.
Figura 23
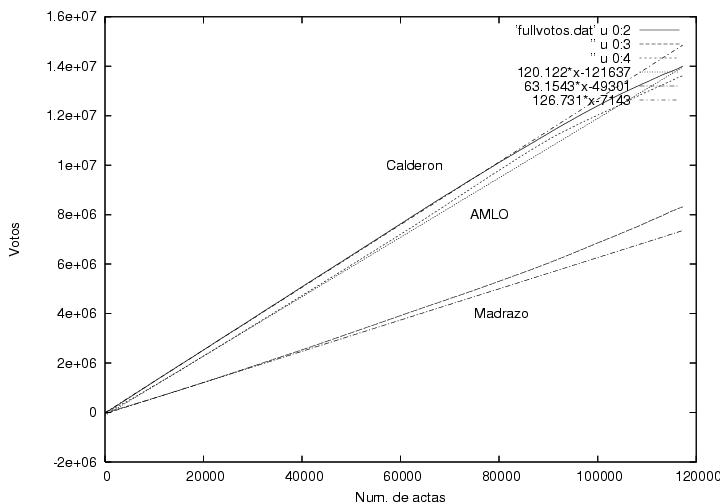
Datos.
Una forma de distinguir números enteros grandes obtenidos de un
proceso estocástico de números inventados tiene que ver con su
estadística. A continuación muestro un histograma del número de
veces que apareció cada digito entre el 0 y el 9 en la posición de las
unidades, i.e., no de las decenas, centenas, etc. La probabilidad de
obtener cierto dígito en la última posición debe ser la misma que para
cualquier otro dígito. Las figuras 24, 25 y 26 muestran que cada
dígito apareció más o menos el mismo número de veces para cada
candidato, alrededor de 11700 veces,
aunque la dispersión de los datos
para AMLO parece ser la mitad que para los otros dos. Curioso.
Figura 24
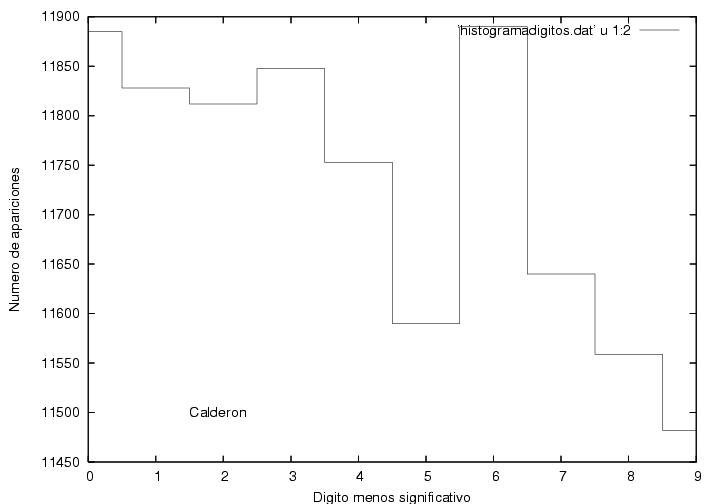
Datos.
Figura 25
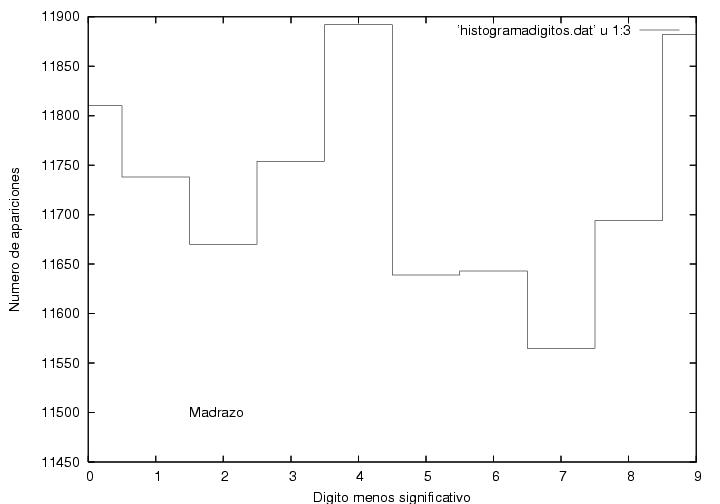
Datos.
Figura 26
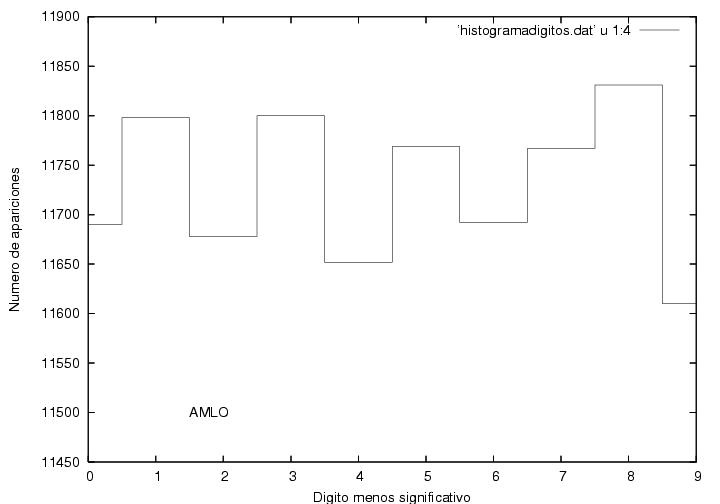
Datos.
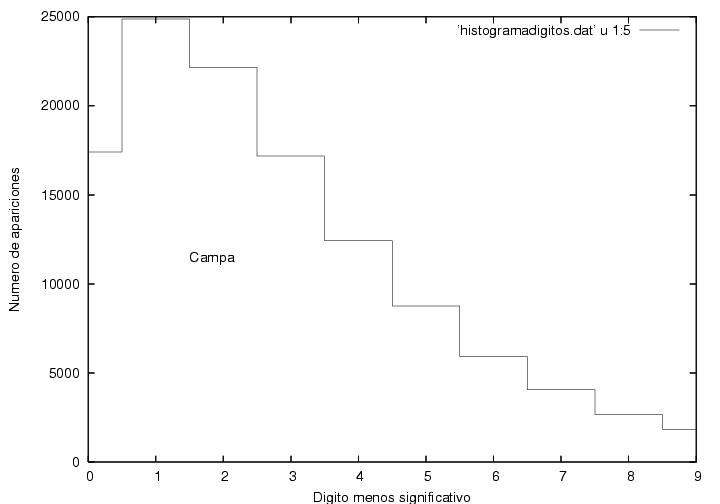
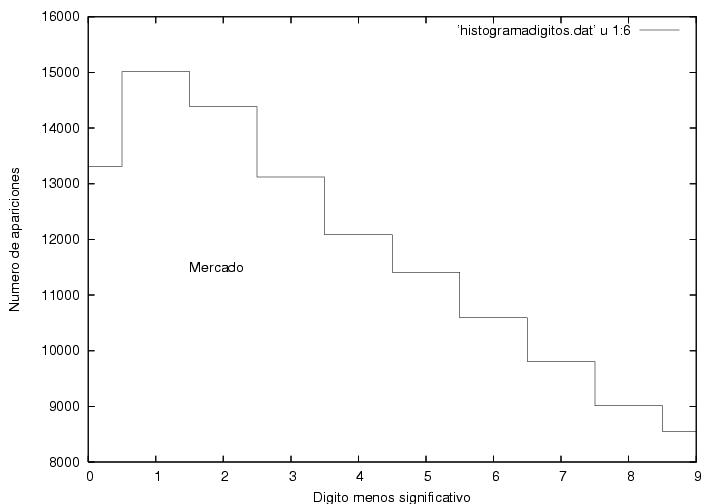
Intenté descartar el que el resultado previo fuese obra de la
casualidad e intenté hacer un programa que evaluara las dispersiones
en diversos rangos, etc., pero estoy muy cansado y no me salió. Así
que me puse a contemplar mi archivo de resultados y me encontré los
datos de Campa y de Mercado. Me ganó la curiosidad...
Figura A25
Datos.
Figura A26
Datos.
Noten la escala. Noten la estructura... pero no, no significa nada,
pues Campa y Mercado obtuvieron votaciones de un dígito, por lo cual
la distribución no tiene por qué ser azarosa.
En todo caso, los
valores de la variancia de las gráficas previas son:
Calderón 141.00
Madrazo 102.15
AMLO 69.88
Campa 7910.26
Mercado 2122.94
Como referencia, hay cerca de N=117000 votos, la probabilidad de obtener
un dígito cualquiera es p=0.1, el valor promedio del número de veces
que aparece un dígito es p*N=11700 y la raiz cuadrada de
p*(1-p)*N=102.61. ¿Es esta una buena estimación de la variancia para
estos datos? ¡El único dato típico es el de Madrazo! Las enormes
variancias de Campa y Mercado son por su extremadamente baja captación
de votos. ¿Son razonables las variancias de Calderón (40% más que la
esperada) y de AMLO (70% de la esperada)? Este análisis debe repetirse
sobre muchos subconjuntos antes de que pueda ser conclusivo.
Existe otra prueba estadística sobre la probabilidad de aparición de
dígitos en colecciones de números. Esta es la prueba de Benford. Yo no
sabía de ella hasta hoy (11/vii/06) en que leí el artículo que escribió al respecto
R. Mansilla. Resulta que desde 1881 se conoce la ley de probabilidad,
conocida ahora como Ley de Benford, que describe el histograma de
aparición del dígito más significativo de una colección de números
aleatorios. Está demostrado que esta distribución se debe cumplir en
una gran variedad de bases de datos donde hay algún elemento de azar
tan diversas como áreas de ríos, pesos atómicos de los elementos
químicos, números de las casa en una ciudad, etc. La aplicación actual
más importante de la ley de Benford es la detección de fraudes
fiscales.
¿Qué es la ley de Benford (LB)? El dígito
más significativo de una colección grande de números se distribuye de
la siguiente manera: la probabilidad de hallar el digito D es
log(1+1/d)/log(10). Por ejemplo, el dígito D=1 debería aparecer en la
primera posición con una probabilidad de log(2)/log(10)=0.301, i.e.,
aproximádamente el 30% de las veces, mientras que el dígito D=6
debería aparecer con la probabilidad log(1+1/6)/log(10)=0.067, i.e.,
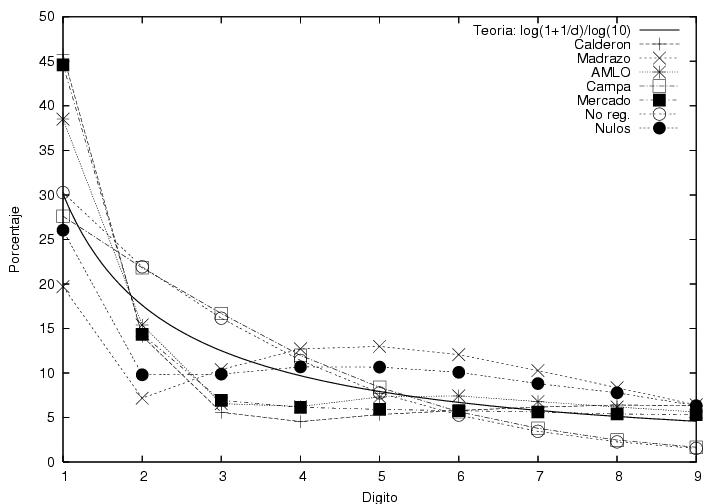
abajo de 7% de las veces. En la figura 27 muestro
la probabilidad de obtener cada uno de los dígitos 1..9 en la posición
más significativa, expresada como un porcentaje. Como referencia,
marqué también el valor predicho por la LB (línea
continua). Curiosamente ¡ninguno de los resultados del PREP es
consistente con la LB.
- Los datos de Calderón (+) parten de
45% en lugar de 30% y bajan rápidamente mostrando un mínimo para el
dígito 4, subiendo posteriormente hasta aproximarse a la ley de
Benford para digitos mayores.
- Los datos de Madrazo (X) empiezan por debajo de la ley de Benford,
tienen un mínimo en 2 y un máximo en 5, y sólo se aproximan a la ley
de Benford en 9.
- Los datos de AMLO (asteriscos) empiezan arriba de la ley de
Benford, tienen un mínimo en 3 y siguen la ley de Benford
aproximadamente a partir del 5-6.
- Los datos de Campa empiezan poco abajo de la LB y terminan un poco
arriba. Decaen de manera monótona. Sin embargo su decaimiento inicial
es muy lento comparado con el predicho por la LB.
- El comportamiento de Patricia Mercado sigue muy de cerca al de
Calderón.
- Los no registrados empiezan sobre la LB pero siguen muy de cerca
los resultados de Campa.
- Los votos nulos siguen cualitativamente el comportamiento de AMLO,
aunque con variaciones más pequeñas.
¿Será posible que las violaciones a la LB se deban a que los números
de nuestra muestra son muy chicos, todos ellos de 3 o menos dígitos?
¿Habrá efectos de tamaño finito? De ser esta la explicación de las
discrepancias, yo esperaría que candidatos con números totales de
votos similares siguieran curvas similares. Este no es el
caso. Los datos de AMLO y los de Calderón difieren notablemente,
a pesar de haber obtenido votaciones muy cercanas. Los datos de
Calderón y de Mercado se parecen, a pesar de haber obtenido votacioes
muy distintas.
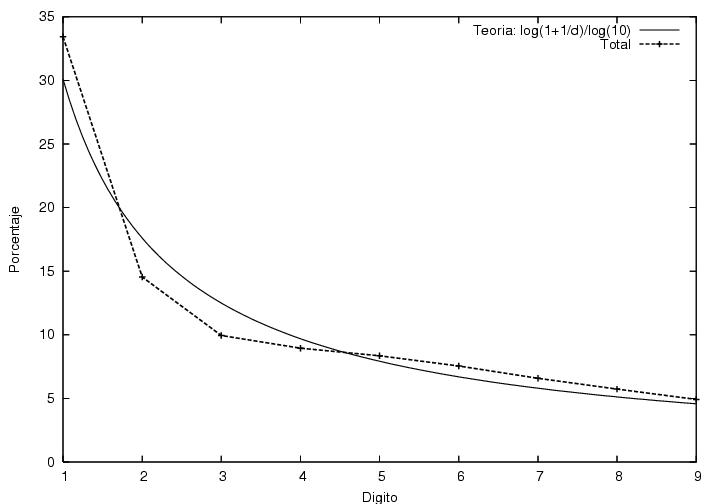
De manera que ningún candidato cumple con la ley de Benford. Sin
embargo, si vuelvo a hacer el cálculo sin distinguir los datos
correspondientes a un candidato de los de los otros candidatos,
es decir, si hago el histograma correspondiente a todos los votos
recibidos por todos los candidatos en todas las casillas, incluyendo
candidatos no registrados y votos nulos, ¡el resultado se vuelve
consistente con la ley de Benford! (figura
28) Esta casualidad... parece
milagrosa, aunque... ¡hay otra explicación! (sugerida por Hernán
Larralde) Es posible que la ley de
Benford no se aplique a nuestras distribuciones, las cuales no son
invariantes de escala. Como las distribuciones tienen un máximo (por
ejemplo, 53 en el caso de Madrazo), es factible que el dígito más
significativo del mismo (5 en el caso de Madrazo) aparezca con una
frecuencia mayor que el dígito anterior o que el posterior (4 o 6 para
Madrazo). Al agregar todos los datos en un mismo histograma, sumamos
candidatos con distintos números esperados de votos y creamos una
distribución más parecida a una distribución invariante de escala, con
lo cual mejoramos el ajuste a la ley de Benford.
Figura 27
Datos.
Figura 28
Datos.
A partir de un análisis de los datos que el PREP volvió públicos, he
encontrado, con ayuda de muchos colegas y de colaboradores que me son
aún desconocidos, una larguísima serie de resultados que, a mi
parecer, son anómalos y demandan una explicación detallada. Quizás
haya expertos en elecciones y expertos en estadística que puedan
ofrecer dicha explicación, o quizás sea necesario esperar el
desarrollo de investigaciones científicas detalladas sobre esta
elección; sin duda, investigaciones conclusivas de este tipo
requerirán mucho tiempo en llevarse a cabo. Quizás no haya problemas
con el PREP y
las anomalías que he señalado no lo sean en realidad. Sin embargo, mientras
no se realicen las investigaciones a que me he referido y no veamos
los resultados o hasta que nos aclare algún experto nuestras dudas de
manera convincente, y con base en la información que he logrado
recopilar y los análisis que he logrado realizar, considero que
es razonable sospechar que pudo haber habido una manipulación de los
resultados reportados por el PREP.
Se me ha dicho que el trabajo que he realizado es irrelevante pues a
fin de cuentas el PREP no tiene validez legal. Los datos importantes
son los del CONTEO distrital. Sin embargo, me resisto a creer que el
PREP haya puesto a nuestra disposición toda la información detallada
de la elección con el propósito de que nos entretengamos la noche de
la elección o que juguemos a las quinielas. El PREP surgió como un
mecanismo que permita a los ciudadanos monitorear y analizar el
desarrollo transparente de las elecciones, volviendo difícil o
imposible el que se
cometan irregularidades sin que sean detectadas. En este sentido,
considero que el PREP es un gran instrumento. Pero para que sea un
gran éxito, debe llevarse a sus últimas consecuencias. Si hay
irregularidades en el PREP, debe suponerse como factible que
haya irregularidades semejantes en el CONTEO.
Cuando en Ciencia tenemos dudas sobre un resultado, lo que procede es
repetir el experimento, repetir el cálculo, verificar, buscar las
fuentes de error, eliminarlas, etc. Cuando las dudas tienen una
trascendencia tanto mayor para la vida democrática de un país, no
debemos hacer menos.
Este trabajo ha sido apoyado, inadvertidamente e involuntariamente,
por el proyecto DGAPA-UNAM-IN111306. Deseo agradecer immensamente a
todos aquellos que han participado en este trabajo análisis enviandome
notas, datos, sugerencias o simplemente su apoyo y entusiasmo.
Si desea comentar esta página, por favor envíeme un mensaje aquí o, mejor aún, añada un
comentario al blog.
Puede consultar los mensajes recibidos con anterioridad, organizados como
cronológicamente
o como
hilos de discusión.
- Conclusiones del estudio
realizado por el Dr. Victor Romero, investigador del Instituto de
Física de la UNAM:
- Texto (pdf)
- Figura 1
- Figura 2
- Figura 3
- Figura 4
- Figura 5
- Figura 6
- Figura 7
- ...Tercero, decir que la
afirmación de que primero llegan las
actas de las zonas urbanas y luego las de la zona rural es
relativamente cierto; pero sólo relativamente. Es proceso es mucho más
complicado...Su trabajo es muy mesurado en sus conclusiones. Es, por
ello, que me parece que sea una lástima que esté siendo usado por
personas extremadamente acaloradas...
- ...Si uno hacia el seguimiento
del avance del PREP por estado, lo
siguiente resalta:...
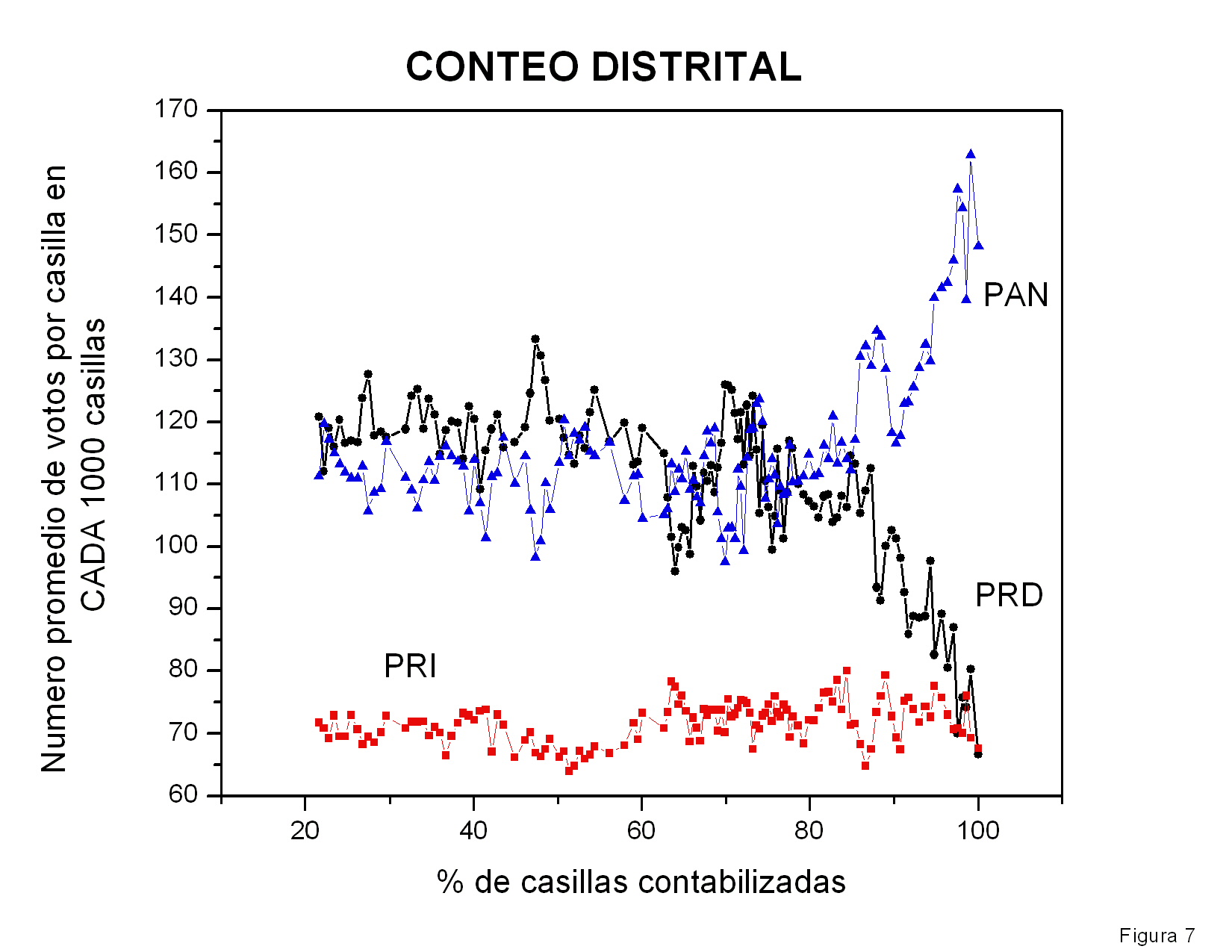
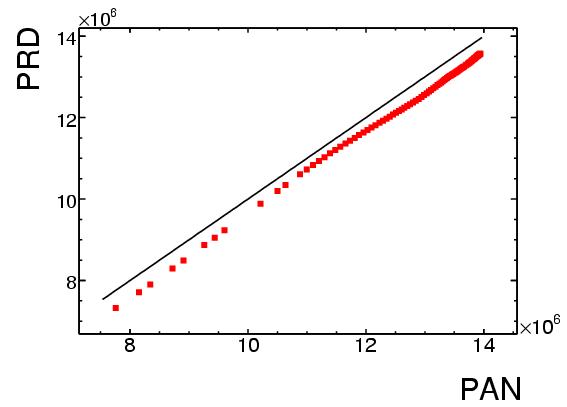
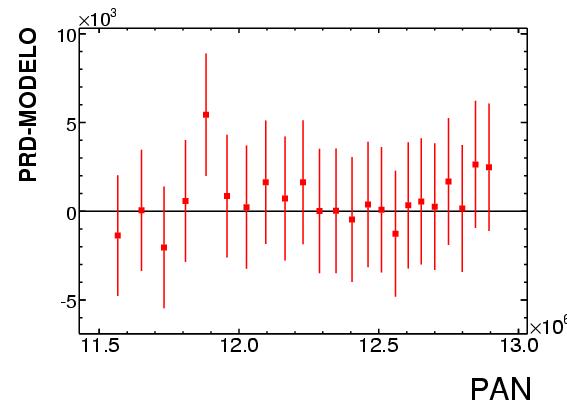
- Resumen: durante en conteo del prep, hay un intervalo durante el que
el numero de votos por el prd es una funcion lineal del numero de
votos por el pan, con una CHI CUADRADA DE 4 en un fit de VEINTE GRADOS
DE LIBERTAD (el valor esperado hubiera sido 20 en vez de 4). Este
comportamiento lineal:...lo cual es MUY INUSUAL al
ajustar datos reales INCLUSO EN CASOS DONDE SE SABE QUE HAY UNA
DEPENDENCIA LINEAL. En este caso, esto es aun mas improbable, pues EL
NUMERO DE VOTOS NO TIENE POR QUE SEGUIR UN COMPORTAMIENTO LINEAL Y
UNIFORME, menos durante un intervalo tan grande.
- Texto
- Imagen 1
- Imagen 2
- Imagen 3
- Imagen 4
- Análisis de los resultados
electorales a partir de la Ley de Benford, por R. Mansilla CEIICH,
UNAM. Conclusiones: Resulta muy difícil explicar el comportamiento de las distribuciones empíricas de los candidatos a la luz de los resultados teóricos antes expuestos. La ley de Benford es una regularidad bastante universal y toda divergencia de la misma debe ser observada con suspicacia.
- ...Mas aun, si sumas
los porcentajes de todos los partidos, nulos y candidatos no
registrados que proporciona el PREP nunca obtienes 100%.
- Mexico remains without an elected president. In the last few days
a number of problems have
surfaced in the election.
- Códigos empleados: Disculpas, pero como los elaboré a la carrera
son algo crípticos y no creo poder entenderlos en un par de días
más. Quizás estas versiones no sean las últimas y no funcionen; sólo
son las que me encontré regadas por mi computadora. Ilustran en todo
caso que Linux es mejor que Windows, pues tiene herramientas
poderosísimas gratis... (pero eso es otra batalla)
- Mi programa en perl para capturar
los datos del prep.
- Mi programa en bash para
extraer los totales de votos de una página web del prep.
- Mi programa en bash para
extraer los porcentajes de la votación de una página web del prep.
- Comando típico para emplear los programas previos que extraen datos de las
páginas web:
for i in index_contenido.html.* ; do ~/txt/papers/06/elecciones/extraenumerosh $i >>rem.dat; done
- Comando para formatear las tablas correspondientes a la figura
1:
perl -pe 's/\s*//; s/%//g;chomp; $_.=[" "," ", " ", "\n"]->[$i++%4]; ' rem1.dat
- Comando para formatear los datos correspondientes a la figura
3:
perl -pe 's/\s*//; s/,//g;chomp; $_.=[" "," ", " ", "\n"]->[$i++%4]; ' rem1.dat
- Comando para preparar los datos de la figura 4:
perl -nae 'BEGIN{@o=(0,0,0,0)} {@n=@F; print "$n[0]", join " ", (map {" ".($n[$_]-$o[$_])/($n[0]-$o[0])} (1,2,3)), "\n";@o=@n }' numeros.dat >diferenciasporcasilla.dat
-
Base de datos del PREP
-
Datos completos del PREP en la elección para presidente ¡por casilla!
(¡Gracias Mauricio!)
- La misma base (sin el encabezado
de e-mail de Mauricio).
- La misma base pero ordenada por
orden cronológico de sellado
- Una sección de la base
de datos, mostrando votos por casilla como función del tiempo sin
agregar. Los campos seleccionados son TIEMPO (en minutos transcurridos
a partir del inicio del conteo ¡a las 18:35!), datos del PAN,
ALIANZA_POR_MEXICO, POR_EL_BIEN_DE_TODOS, NUEVA_ALIANZA,
ALTERNATIVA_SOCIAL_DEMOCRATA, NO_REGISTRADOS, NULOS y
NUMERO_VOTANTES.
- Un pequeño iprograma en perl para extraer
campos seleccionados de la base de datos previas. El programa puede
ser fácilmente adaptado a otras bases de datos similares y para
hacer proceso sobre los datos obtenidos.
- Una sección de la base
de datos, mostrando votos acumulados como función del tiempo.
- Base de datos del PREP para la
elección de senadores, casilla por casilla.
- Base de datos del PREP para la
elección de diputados, casilla por casilla.
- Bases de datos del CONTEO DISTRITAL para la elección de presidente, diputados y senadores, casilla por casilla.
- Programa en PERL para extraer datos
específicos de las bases anteriores. Puede ser modificado fácilmente
para procesar dichos datos.
- Versiones comprimidas originales de las bases de datos del CONTEO
DISTRITAL para la elección de presidente, diputados y senadores, casilla por
casilla, obtenidas de aquí.
Nota: mis versiones '.txt' difieren de las contenidas en
estos archivos en los retornos de carro. El IFE comprimió esos
archivos en máquinas WINDOWS ¡¡Lo cual me horroriza!! Manejar
información delicada con sistemas operativos tán susceptibles a
ataques me parece una imprudencia. ¿Uds. han sabido de alguna máquina
infectada por virus? ¿Recuerda el nombre de su sistema operativo?
visitas desde 14, jul 18:15:04.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}