Varios lectores han contribuido con espejos de esta página. Es
recomendable guardar las ligas por si mi computadora se vuelve
inaccesible (lo cual sucede con cierta frecuencia):
Además de los espejos mencionados arriba, se ha preparado un espacio para
exponer, discutir e integrar análisis cuantitativos que se han
realizado con los datos de las elecciones del 2 de julio del 2006 en
México.
-
Advertencia: Lo que sigue no debe tomarse como un estudio
científico concluido, aunque sí podría considerarse como la parte
inicial de uno. Tiene algo de datos duros verificables obtenidos de
fuentes reconocidas, descripciones fenomenológicas de los mismos e
hipótesis sugeridas por los datos las cuales implican consecuencias
adicionales que podrían y deberían ser exploradas. Estas podrían formar el
inicio de investigaciones posteriores para confirmar o
desechar las hipótesis. Además, hay especulaciones, hilos sueltos, preguntas y
opiniones... y errores. Todos éstos son
elementos de toda investigación en la vida real, aunque la mayor parte
de ellos debería destilarse o eliminarse antes de producir una
publicación científica. La página está en evolución y las conclusiones
y evidencias inobjetables de una versión pueden desinflarse y
convertirse en una curiosidad anecdótica en la siguiente.
-
Disculpa: Esta página ha crecido sin control ni orden, lo
cual ha vuelto difícil su lectura. He incorporado material en orden
casi-cronológico, el cual no coincide con el orden lógico, excepto
cuando aparecen resultados fuertemente ligados a resultados previos,
en cuyo caso he intentado colocarlos juntos. Considero que no
debo eliminar material ni renumerar figuras, pues es importante que lectores
con copias correspondientes a distintas actualizaciones puedan
entenderse mutuamente cuando discutan esta página. Ello ha requerido
una numeración de figuras un poco barroca. Cuando he detectado
errores he añadido descripciones de los mismos en lugar de removerlos. Eso
requiere cierto cuidado por parte de los lectores. Este es el peligro de
dar a conocer trabajos en proceso. Espero poder reescribir esta página
de manera coherente en un futuro cercano, o al menos, escribir una
guía para su lectura, o...
-
Para facillitar las comparacines de una versión con otra, tengo ahora el
estudio archivado en el formato RCS, de
donde podrán obtener cualquier versión anterior mediante el comando
co (presente en cualquier distribución de Linux). Para
enterarse de las últimas modificaciones, puede leer la bitácora de cambios (preparada con
rlog).
-
Nota: Para los que quieran/puedan hacer otros estudios, al
final hay ligas a información y datos adicionales,
incluyendo el PREP completo, casilla por casilla, y los datos del
CONTEO DISTRITAL.
-
En otro tema... Parece fuera de lugar, pero no puedo dejar
de aprovechar la oportunidad de felicitar a Gerardo García Naumis y a
José Luis Aragón por su artículo, el cual
fue reseñado
en la primera plana de Nature News. Quizás
no se imaginan el enorme honor que significa para ellos, para la UNAM
y para la comunidad científica mexicana. ¡Felicidades!
- Tampoco viene aquí... pero el jueves 10 de agosto, a las
20:30 canta Muna Zul
en el Estudio Teatro que Danza, Tenayuca 55-A,
Col. Vértiz-Narvarte. ¡Se las recomiendo!
La certeza es la clara, segura y firme convicción de la verdad; la
ausencia de duda sobre un hecho o cosa, de acuerdo con el Diccionario
Enciclopédico de Derecho Usual, de Guillermo Cabanellas, (Editorial
Heliasta, Tomo II, Argentina, 2003, páginas 130 y 131).
Tener certeza sobre la totalidad de los votos emitidos y el sentido de
ellos adquiere relevancia en las elecciones democráticas para
determinar al candidato electo, porque tanto los partidos
contendientes como la sociedad en su conjunto, tienen mayor interés
sobre la certidumbre de que el cómputo de los votos se llevó a cabo
adecuadamente, y que en verdad la decisión mayoritaria es la que se
advierte en un primer momento o si las posibilidades de error en el
cómputo de varias casillas pudieran llevar, luego de una verificación
o recuento, en los términos previstos en la ley, a un resultado
diferente.
(Sentencias SUP-JIN-212-2006-Inc2 y otras emitidas por el TEPJF
el día 5 de agosto del 2006.
)
Acaba (3/vii/06) de concluir la votación presidencial en México y el programa
de resultados electorales preliminares (PREP) puso a disposición del
público en general los datos parciales conforme eran
procesados. Durante la noche de la elección hice un pequeño programa
de cómputo
para capturar dicha información cada cinco minutos (más el tiempo
necesario para que el servidor me contestara). Aquí y aquí guardo copias de todas las páginas
capturadas. De ellas es de donde extraje la información que presento
abajo, aunque contienen mucha más información que podría serles
útil.
Un amigo (Guillermo Barrios del Valle, ¡gracias!) me hizo el favor de
organizar los primeros correos recibidos respecto al contenido de esta
página. Los puede consultar organizados como
cronológicamente
o como
hilos de discusión.
Asimismo, organizó un blog.
Nota:Alfonso Baqueiro (su correo está aquí y su blog aquí) escribió un programa muy
similar al
mío. Afortunadamente inició más temprano y concluyó más tarde su
captura sistemática de datos. Muy amablemente, me los hizo llegar, por
lo cual rehice las gráficas que contenía mi página original. Para
quienes estén interesados, junto a las nuevas gráficas añadí ligas a
las viejas gráficas y a los nuevos y viejos datos. ¡Gracias Alfonso!
Gracias también a otros lectores de esta página que me han mandado
datos. Desafortunadamente, no he tenido tiempo para incluirlos.
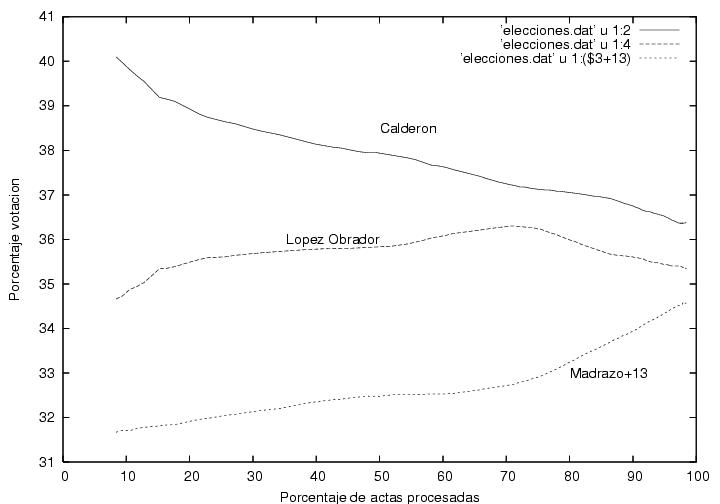
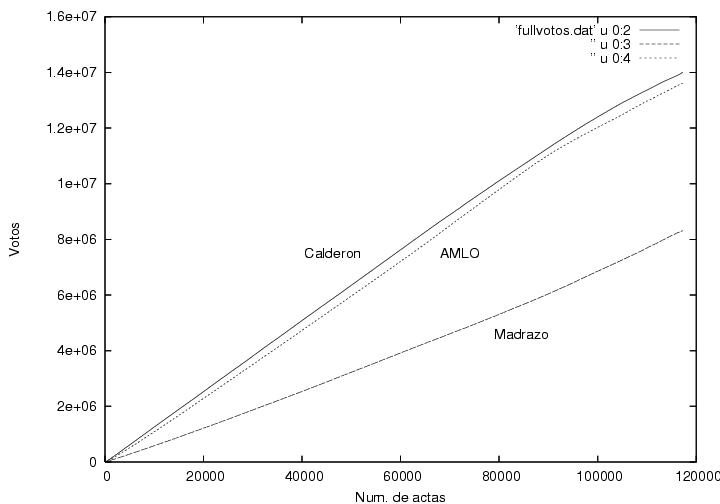
En la figura 1 se muestra a el porcentaje total de
la votación
logrado por Calderón y por AMLO como función del porcentaje de actas
procesadas. Empecé a capturar los datos pues me llamó la atención que
cuando apenas se había computado el 1% de las actas, Calderón iba
arriba por alrededor de 7% (según recuerdo) y gradual pero sistemáticamente su
porcentaje iba disminuyendo mientras el porcentaje de AMLO iba
aumentando. (las encuestas pre-electorales predecían un empate
técnico). Yo hubiera esperado un resultado muy fluctuante que
rápidamente se estabilizaría alrededor de los valores finales hacia el
final del conteo. Este resultado muestra que las primeras casillas
contabilizadas tuvieron resultados aparentemente atípicos y que le dieron a
Calderón una ventaja porcentual considerable que disminuyó conforme
avanzaba el conteo. Desgraciadamente no pude capturar los datos desde el
principio, pero el comportamiento de esta gráfica se puede extrapolar
cualitativamente hasta el momento en que se habían computado el primer
por ciento de actas. La pregunta es ¿por qué el inicio de las
actas computadas (quizás poco más de 1000 actas) tuvo un comportamiento
tan aparentemente atípico? (ver abajo).
Otra característica que me llamó la atención de esta figura es la
ausencia de fluctuaciones, aunque creo que eso es normal (ver abajo).
Finalmente, es curioso que la tendencia al alza de AMLO que se había
mantenido constante durante el 70% del conteo se revierte rápidamente
al llegar al 70%+ de las actas procesadas. Sin embargo, esto podría
explicarse si fuera que el voto rural, quizás mayoritariamente pro
PRI, hubiera empezado a llegar y a computarse cerca de las 2AM. Otra
posible explicación es la llegada de los resultados del
noroeste, retrasada debido a las diferencias de huso horario.
Advertencia:Modifiqué la curva correspondiente a Madrazo
añadiéndole 13% para poder mostrarla en la misma gráfica. Por lo
tanto, el lector deberá restar 13% del valor que lea en el eje vertical.
Figura 1
Gráfica previa
Datos
(Datos previos)
Indice
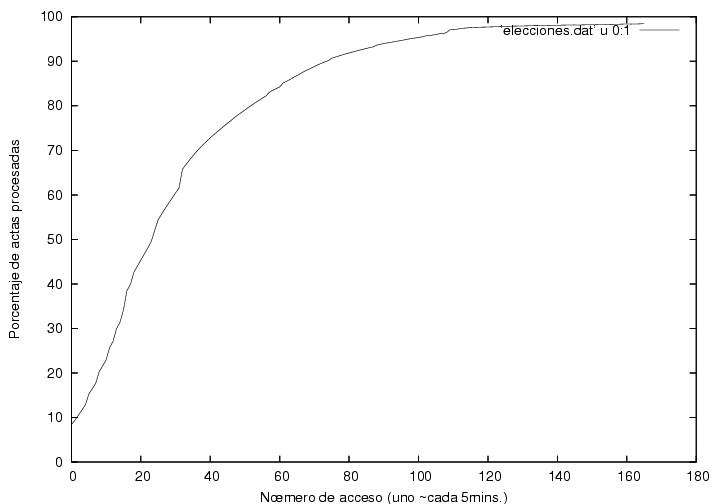
La figura 2 indica la velocidad de recepción y
proceso de actas. El
eje horizontal corresponde a el número de accesos de el programa,
diseñado para tomar una fotografía de la página del PREP cada 5
minutos, aunque dada la saturación del sistema, el tiempo de acceso
osciló entre 5 y 10 minutos. El eje vertical muestra el porcentaje de
actas procesadas. Claramente, hubo una desaceleración notable en la
velocidad de recepción y proceso, lo cual podría explicarse con el
arribo tardío del voto rural (ver arriba). Cerca del 31-avo dato
(correspondiente al 42-avo acceso (los números difieren pues descarté
datos repetidos, i.e., datos capturados antes de que se actualizara la
página del PREP))),
alrededor de la 1:01AM, hay un pequeño salto. Este se debe a que el
PREP no actualizó su página en poco más de 20 minutos. A
partir de ahí el ritmo de captura empieza a disminuir.
Poco después los datos de AMLO en la figura de arriba muestran un máximo e
inician un descenso. Antes del pequeño salto el comportamiento es
aproximadamente lineal, mientras que después decrece gradualmente. Una
explicación tentativa es que al principio del conteo las actas
arribaron a una velocidad mayor a la capacidad de proceso del PREP,
por lo cual se formó una cola. Hasta la 1AM el PREP estaría trabajando
a su máxima capacidad, que podemos estimar como la pendiente de la
región recta. De las páginas del PREP se
infiere que de las 21:30 a la 1:01 se procesaron cerca de 70,000
actas, por lo que la capacidad de proceso del sistema es de
aproximadamente 330 actas por minuto. Como hubo 300 distritos, esto da
un ritmo de un acta por minuto en cada oficina. Habiendo disminuido el ritmo de
llegada de las actas, las actas se procesarían inmediatamente conforme
fueran llegando y la velocidad de proceso aparente en la figura sería
simplemente la velocidad promedio de arribo.
Figura 2
Gráfica previa
Datos (los mismos que para la figura 1)
(Datos previos)
Indice
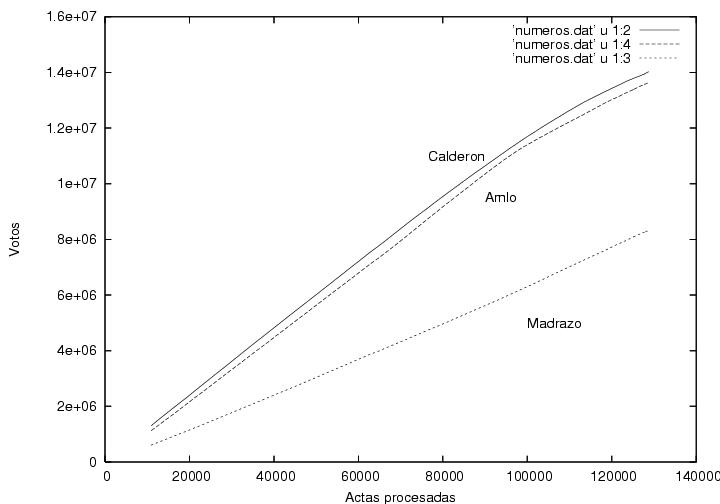
En la figura 3 se muestra el número total de votos obtenidos por los
tres candidatos como función del número de actas procesadas. Curiosamente,
Calderón y AMLO incrementan su número de votos aproximadamente con la
misma velocidad. Calderón y AMLO recibieron aproximadamente el mismo
número de votos por casilla computada. Es por ello que me pareció
atípico que en las primeras casillas computadas (no mostradas)
Calderón estableciera una fuerte diferencia que no se modificó
prácticamente en las demás casillas. Esta gráfica indica que la
distancia entre los porcentajes de la votación obtenidos por
Calderón y por
AMLO disminuyó al transcurrir el tiempo sobre todo por el aumento del número
total de votos computados y no por que hubiera disminuido la
diferencia de votos entre ellos (ver figura 6).
Figura 3
Gráfica previa
Datos
(Datos previos)
Indice
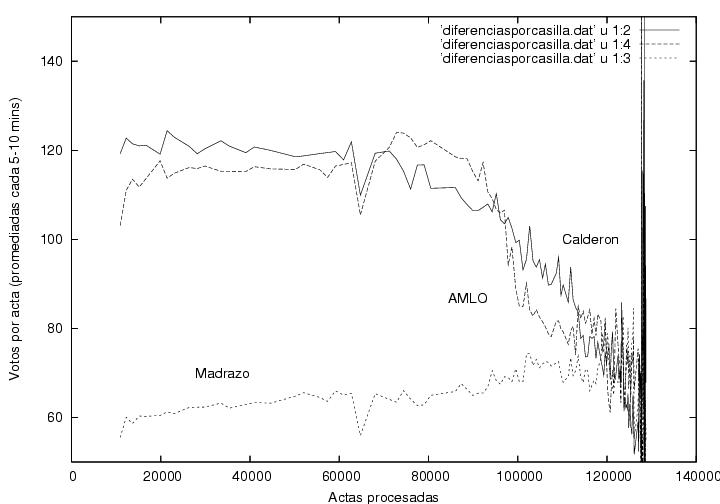
En esta figura muestro los votos obtenidos por
Calderón, AMLO y
Madrazo en
cada casilla, promediados sobre todas las actas que se procesaron en
los 5-10 minutos en que el programa obtenía una nueva radiografía del
proceso. Esta gráfica muestra fluctuaciones aparentemente normales
(ver arriba) y resultados muy similares para los candidatos durante el
tiempo que el programa estuvo capturando datos. Hacia el
final, el número de votos disminuye y las fluctuaciones aumentan, pero
podría ser consecuencia de la llegada de votos rurales, de comunidades
aisladas, cada vez más espaciados en el tiempo, mientras que los
tiempos de muestreo fueron uniformes. Hay sin embargo una anomalía
curiosa alrededor de las 61000-62000 actas procesadas, en que aparecen
estructuras similares correlacionadas en las curvas correspondientes a
los tres candidatos.
Una anomalía que definitivamente requiere
explicación corresponde a los datos hacia el final del conteo, donde se
ven fluctuaciones tan grandes que se salen de la gráfica. En esta
región se llegan a detectar más de 6000 votos por casilla. Creo que
ninguna casilla debía haber recibido más de 750-760 votos. Peor aún,
algunos datos indican un número de votos por casilla
negativos. Estudié con detalle algunas de éstas anomalías a través de las
páginas del PREP:
- Incluyo aquí un fragmento de la tabla donde detecté las
anomalías. Añadí un campo con la hora del corte correspondiente a
esos datos y una liga a mi copia de la página del PREP
correspondiente.
| Votos promedio por
casilla |
| # actas procesadas |
Calderón | Madrazo | AMLO | Hora/liga |
| 127710 | 50 | 48 | 47 |
12:27 |
| 127713 | 1825 | 6657 | 1216 |
13:50 |
| 127724 | 115 | 60 | 115 |
13:57 |
| 127732 | -605 | -2416 | -501 |
12:33 |
| 127752 | 378 | 1032 | 328 |
14:03 |
| 127772 | -167 | -875 | -219 |
12:39 |
- Noten que los cortes ordenados por número de actas procesadas no
coinciden con los cortes ordenados cronológicamente.
- A las 12:27 del 3 de julio
se habían procesado 127,710 actas.
- El número aumentó gradualmente y a las 12:33 creció a 127,732.
- A las 12:39 creció a 127,772.
- A las 13:17 el número
llegó a 127,936.
- A las 13:50 ¡el número
total de actas disminuyó a 127,713!, es decir,
desaparecieron 223 actas del reporte.
- Los resultados de las 13:50 son inconsistentes
con los de las 12:27. Por
ello, el segundo renglón de mi tabla arriba muestra números tan
absurdos como 6,657 votos por acta para Madrazo, 1,825 para Calderón y
1,216 para AMLO.
- A las 13:57 el número
había aumentado a 127,724. Sin embargo, los resultados eran
inconsistentes con los de las 12:33, por lo cual la tabla vuelve
a mostrar números ridículos de más de 2,400 votos negativos por acta.
- A las 14:03 el número se situaba en
127,752. De nueva cuenta, el reporte correspondiente es
inconsistenta con los reportes de las 12:33 y de las 12:39, por lo cual vuelven a
aparecer resultados absurdos como más de mil votos por casilla o más
de 800 votos negativos por casilla.
- Durante mi
reducción de datos ordené los registros de acuerdo al número de actas
procesadas. Si las hubiera ordenado cronológicamente, ya sea por la
hora de captura del registro o por la hora de corte estampada por el
PREP, las inconsistencias descritas arriba hubieran sido mucho más
grandes.
Este es un error que sólo
podría ser explicado por personal del PREP. (Rici Lake ha dado una explicación tentativa de lo que pudo
haber sucedido dentro del IFE durante este intervalo de tiempo.)
En el Informe Final del Comité Técnico Asesor del PREP (COTAPREP)
entregado al IFE el 31 de agosto del 2006 se menciona el
incidente de la omisión de la publicación durante 30 minutos
de los resultados correpondientes a los votos en el extranjero. No hallé
una explicación de dicha omisión.
Figura 4
Gráfica previa
Datos
(Datos previos)
Indice
La figura 5 muestra la diferencia entre los votos
atribuidos a Calderón y a AMLO como función del número de actas
procesadas. La curva muestra claramente tres regiones: una subida
seguida de una caída, otra subida y finalmente algunas
fluctuaciones. Las primeras tres regiones muestran pendientes bastante
constantes y las transiciones de una a otra son bastante
abruptas. El origen de dichas transiciones debe ser explicado.
Quité de esta gráfica las barras de error que mostraba mi
figura previa pues un colega me hizo ver que mi estimación de la
dispersión esperada era incorrecta. Aún no hago un análisis de las
fluctuaciones de estos datos para checar si son o no anómalos.
Figura 5
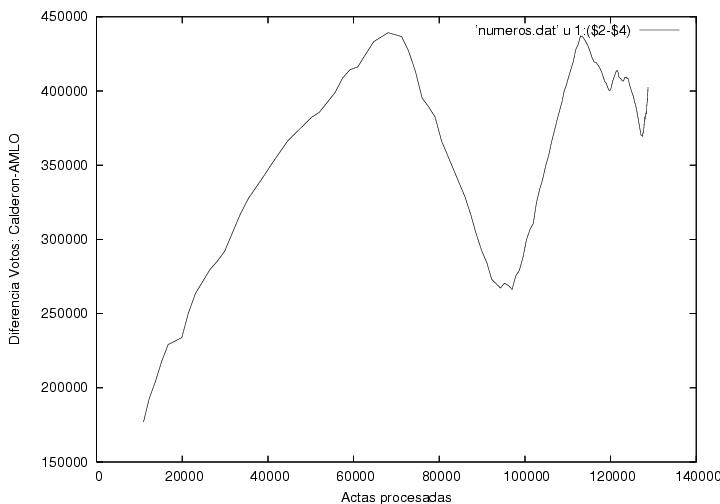
Gráfica previa
Datos (los mismos que para la figura 3)
(Datos previos)
Indice
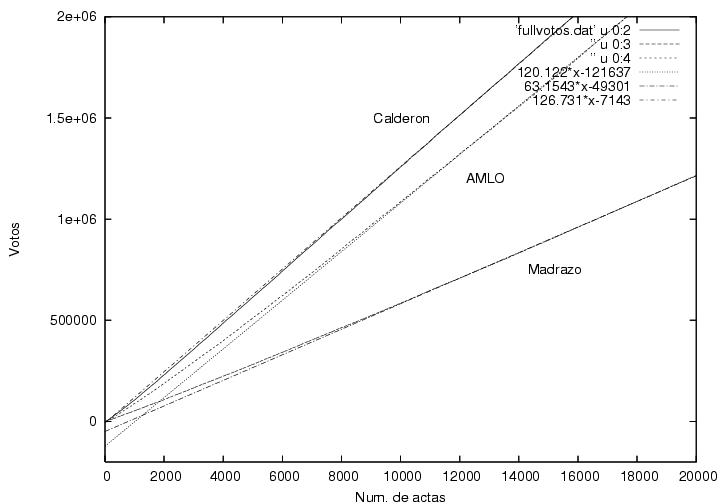
En esta figura muestro los datos iniciales de la
figura 3,
correspondientes a las primeras 20,000 actas capturadas. Con una línea
vertical he marcado desde donde tengo datos capturados
sistemáticamente (con 10943 actas procesadas). De ahí a la derecha se
muestran los datos capturados
para los tres candidatos. Los tres candidatos muestran una tendencia
lineal sin fluctuaciones aparentes, quizás por haberse acumulado ya un
número grande de votos, del orden de un millón. Del lado izquierdo de
la línea vertical muestro tres líneas rectas (no rotuladas) que parten
del origen y terminan en el primer dato capturado para cada
candidato. Extrapolé dichas líneas hacia el lado derecho de la gráfica
para compararlas con los datos iniciales de los candidatos. En el caso
de Calderón, los datos del PREP y la línea recta que parte del origen
son prácticamente indistinguibles. En el caso de Madrazo hay una
ligera diferencia, lo cual refleja que la votación por acta hacia
Madrazo iba aumentando gradualmente, lo cual es consistente con la
figura 4. Sin embargo, la línea recta correspondiente a AMLO se aleja
bastante más rápidamente de los datos obtenidos del PREP. Eso hace
suponer que en las primeras 10,000 casillas la votación por AMLO fue
significativamente menor que en las subsiguientes. La pendiente
inicial correspondiente a la curva de AMLO tuvo que ser notablemente
menor que la pendiente subsiguiente, pues obviamente los datos
deberían pasar por el origen. Es sin embargo interesante hacer
una extrapolación de los datos de AMLO. Empleando los datos del
intervalo [10,000:20,000] hice una extrapolación lineal. La ordenada
al origen es -126,000. Curiosamente, dicho número es muy cercano a
(menos) el número total de casillas. La figura que le sigue (figura 7)
es la misma que la figura 6 pero extendida hasta 70,000
actas. Me llama la atención que el ajuste lineal a los datos iniciales
de AMLO, empleando para el mismo sólo los datos entre 10,000 y
20,000, es prácticamente indistinguible de los
resultados correspondientes del PREP sobre todo el rango. ¿Por qué la
extrapolación hacia el lado derecho de la gráfica es tan buena,
mientras que la extrapolación hacia el lado izquierdo es tan mala?
En un escenario de mucha especulación sobre conspiraciones, estos datos
podrían interpretarse de la siguiente manera:
Pareciera haberse restado un voto a favor de AMLO por cada una de las 130,000
casillas durante la acumulación de los resultados.
Seguramente, se podrían encontrar otras explicaciones. Será interesante
saber por qué el voto de las primeras 10,000 casillas fue tan distinto
al de las 60,000 casillas subsiguientes, el cual habíamos visto en la
figura 5 que es muy distinto al de los que siguieron.
Urge procesar los datos correspondientes a las primeras 10,000
casillas. Un lector de esta página acumuló datos manualmente desde las
8:00PM. Están disponibles aquí.
En cuanto tenga tiempo intentaré añadir esos datos a la figura 6.
Figura 6
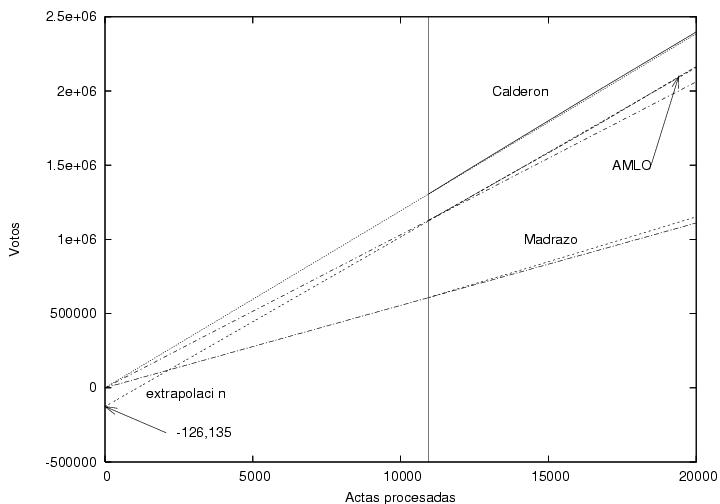
Datos (los mismos que para la figura 3)
Figura 7
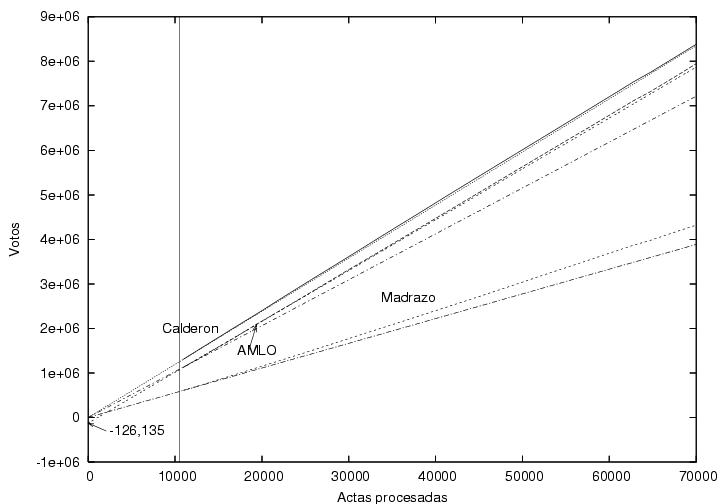
Datos (los mismos que para la figura 3)
Indice
Datos de la base de datos por casilla
Empecé (7/VII/06) a procesar la base
de datos del PREP y me encontré con algunas dificultades.
- El número de registros que contiene es 117,287. Como no he tenido
tiempo de seguir las noticias no estoy seguro en cual de las cuentas
entrarían los 13,200 registros faltantes necesarios para completar las
130,488 reportado en las páginas del
PREP durante el conteo.
- Ya conseguí también las bases de datos de senadores y diputados. Contienen 120,032 y 120,091
registros respectivamente. ¿Por qué difieren en alrededor de 2700
registros de la base para presidente?
- Además de los registros faltantes, hay otros 22,538 que tienen un
asterisco ('*') en alguno de los campos numéricos. El problema me
saltó a la vista al tratar de checar la consistencia de los datos
numéricos. Aquí guardé la base de
datos correspondiente a estos registros incompletos.
- Eliminando los registros con asteriscos, hay 27,073 registros que
considero inconsistentes, pues la suma de los campos
PAN, ALIANZA_POR_MEXICO, POR_EL_BIEN_DE_TODOS, NUEVA_ALIANZA,
ALTERNATIVA_SOCIAL_DEMOCRATA, NO_REGISTRADOS y NULOS no es igual al
número de BOLETAS_DEPOSITADAS. Aquí guardé la base de datos
correspondiente.
- El NUMERO_VOTANTES siempre es
consistente con la suma de PAN+ALIANZA_... Habiendo tantos errores en
otros campos es sorprendente que en este campo no haya un solo error
en más de 117,000 registros. El NUMERO_VOTANTES fue uno de los campos que
llenaron los funcionarios de casilla al llenar las actas.
Por lo tanto, la ausencia de errores no sólo es sorprendente sino
imposible. Lo que sucedió es que este
campo no se tomó de las actas, sino que fue calculado por las
computadores del IFE, definiéndolo como la suma de votos por
partidos mas no registrados mas nulos.
-
El propósito
de llenar este campo en las actas es el siguiente
La comparación de todos esos elementos sirve de control o candado para
verificar la correspondencia del número de votos
(tomado de las sentencias SUP-JIN-212-2006-Inc2 y otras emitidas el 5
de agosto del 2006). Al omitir dicho campo de las bases de datos, se
vuelve imposible para los ciudadanos el aplicar dicho control o
candado, i.e., su ausencia es contraria al propósito de hacer
pública de manera electrónica la información sobre los resultados
electorales.
- Verifiqué que el NUMERO_VOTANTES se conserva consistente aún si
reemplazo todos los asteriscos por ceros en lugar de eliminarlos. Por
lo tanto, en los análisis subsiguientes realizo dicha modificación.
- Reemplazando los asteriscos por ceros, obtengo que la suma de
las BOLETAS_DEPOSITADAS es 35,876,783 y la de
los NUMERO_VOTANTES es 38,516,730, por lo cual parece haber 2,639,947 más votos
que boletas depositadas en las urnas. Por otro lado, si elimino los
registros con asteriscos, obtengo 31,279,149 boletas depositadas y
31,504,772 votantes, es decir 225,623 más votantes en la elección
presidencial que el número de boletas depositadas en las urnas.
- Nota: Los últimos tres números contenían un pequeño error que
fue corregido el 8/viii/06 El número de votos sobrantes es mayor
que el previamente reportado de 223,688.
- El exceso de votos se puede desglozar de la siguiente manera:
En 9,311 registros el número de boletas depositadas en las urnas supera al
número de votantes. El exceso de boletas en estos registros es de
228,165. Por otro lado, hay 17,763 registros en los cuales el número
de votos supera al número de boletas depositadas. El exceso de votos
en estos registros es de 453,788. La diferencia de 453,788 y 228,165
da el exceso de 225,623 votos sobre boletas. Sin embargo, el número
total de votos involucrados en este error es la suma 681,953.
- El comportamiento temporal de estos errores se describe por la
figura 23.4.
- En las bases de datos de los Cómputos Distritales se omitió el
campo que reporta el número de boletas depositadas en las urnas. Por
lo tanto, se eliminó de las bases de datos otro candado que hubiera
permitido a la ciudadanía verificar la presencia o ausencia de errores
en las bases de datos.
- Por lo tanto, es imposible averiguar si estos errores fueron
corregidos en las fases subsiguientes de la elección.
- El IFE ha preparado una respuesta
a algunos de los puntos mencionados arriba, en otras partes de esta
página y en una nota enviada al
Dr. Woldenberg.
- En dicha respuesta el IFE aclara
las discrepancias entre el número de actas para presidente, diputados
y senadores.
- También aclara que el campo NUMERO_VOTANTES es en efecto un número
calculado. En otras bases de datos se incluye un nuevo campo
llamado TOTAL_CIUDADANOS_VOTARON que refleja el número de votantes que
fue asentado en actas. Comparando ambos campos en esas bases de datos
se menciona que
En realidad la cantidad de actas en donde difiere la cantidad de
ciudadanos que vota on contra el total de votos,incluyendo las actas
inconsistentes es de 64,123 de 128,471 actas procesadas
es decir, en la mitad de las actas dichos campos son
inconsistentes.
- Más adelante se aclara también que:
El dato referente a que la suma de las BOLETAS_DEPOSITADAS es
35,876,783 y la de los NUMERO_VOTANTES es 38,516,730, por lo cual parece
haber 2,639,947 más votos que boletas depositadas es correcto. El primero
de estos dos campos es un dato que se captura directamente del acta, por
lo que los errores de cálculo provienen de un mal llenado de las
actas. Es importante mencionar que en un número importante de
actas, dichos campos (ciudadanos que votaron, boletas depositadas en la
Urna, etc.) no son siempre llenados correctamente o simplemente son
dejados en blanco, por lo que estas cifras nunca cuadran con el total de
votos.
Espero que el IFE no haya ofendido a Juanita la de la frutería ni
Panchito el de la panadería... (Si soy sarcastico es porque la
propaganda me enferma; me recuerda otros continentes en otras épocas).
Si según el IFE las actas están mal llenadas y los datos no cuadran,
¿qué procede?
- Gerardo Horvilleur realizó un análisis en
que compara el número de
boletas recibidas, boletas extraidas y boletas sobrentes. Como se ha
afirmado que dichos datos podrían no cuadrar pues se pudieron haber
depositado boletas de una casilla básica en una contigua o viceversa,
Gerardo hizo el análisis sección por sección. Sus resultados
muestran que agregando las boletas por sección hay 819,067 sobrantes y hay 2,979,598 boletas
faltantes. Aunque las boletas faltantes podrían trivializarse
en términos de los coleccionistas de boletas, ¿cómo explicar las
boletas sobrantes? Aquí está un
archivo con los datos (estado, distrito, seccion, casilla,
lista_nominal, boletas_recibidas, boletas_extraidas,
boletas_sobrantes) de las 57,657 casillas en 36,081 secciones
donde los números no cuadran.
- El 27 de agosto escribí un artículillo titulado
Incertidumbre y errores en las elecciones de julio del 2006
en el que se profundiza en el análisis mencionado arriba
para estimar la magnitud de los errores esperados durante la
cuenta de los votos y se concluye que es mucho mayor que la diferencia
entre FC y AMLO. En resumen,
- De las 51,538 secciones verificables (en algunas faltan datos para aplicar
la prueba), en 16% el número de boletas depositadas en las urnas es
mayor a la
diferencia entre las boletas recibidas y las sobrantes (632,682
boletas de más) y en el 37% es menor (580,875)
En total, hay 27,416 secciones (53%) con este tipo de
inconsistencia, la cual involucra 1,213,557 boletas.
- De 42,093 secciones, en 27% el total de votos contabilizados es
mayor que el número de ciudadanos que se presentaron a votar (517,866
votos de más) y en otro 27% es menor (761,954). En total, hay
22,498 secciones (53%) con este tipo de inconsistencia, la cual
involucra 1,279,820 votos.
- De 50,035 secciones, en 19% el
número de boletas depositadas en la urna es mayor al número de
ciudadanos que se presentaron a votar (685,298 boletas de más) y en
32% es menor
(1,213,921). En total, hay 25,150 secciones (50%)
con este tipo de inconsistencia, la cual involucra 1,899,219
boletas.
- De 40,057 secciones, en 28% el número total de votos contabilizados
es mayor al número de boletas depositadas en las urnas (345,112 votos
de más) y en 14% es menor (156,094). En total, hay 16,547 secciones
(41%) que muestran este tipo de inconsistencia, la cual involucra
501,206 votos.
Las mismas cuentas pero realizadas casilla por casilla en vez de
sección por sección arrojan aún más inconsistencias.
En resumen, en cerca de la mitad de las secciones hay inconsistencias que
involucran del orden de un millón de votos. Con incertidumbres de
ese tamaño,
¿cómo podemos definir un triunfo certero con una ventaja de
poco más de doscientos mil votos?
- Aquí hay una (mala) traducción al
inglés.
Indice
La figura 8 muestra el porcentaje de la votación
obtenida por cada candidato como función del tiempo. El tiempo está
medido en minutos transcurridos desde el inicio del conteo, el cual
tomé como la hora de recepción de la primera acta (18:35). Esta
gráfica es similar a la figura 1, pero graficada
como función del tiempo en lugar del número de actas
procesadas. Además, está figura fue construida con los datos detallados del prep, casilla por
casilla, y no con los que capturamos via la red, por lo cual se puede
mostrar el conteo completo. Inicialmente, había una fuerte ventaja
para Madrazo, seguido de Calderón y finalmente de AMLO. Durante la
primera hora hay fuertes fluctuaciones, lo cual era de esperar, y las
curvas se cruzan algunas veces. Los
datos se estabilizan gradualmente hasta que pasadas dos horas y media
las fluctuaciones se vuelven marginales. Me imagino que el PREP no
reportó los datos iniciales sino que esperó a que estos se hubiesen
estabilizado.
Figura 8

Datos
Indice
La figura 9 es similar a la figura
8, pero graficada como función del número de actas
computadas. Como muy al inicio las actas llegaron muy espaciadas, en
esta gráfica no se aprecia la región fluctuante que es muy
claramente visible en la figura 9; queda
comprimida en el extremo izquierdo. Para poder mostrar más claramente
la estructura de las distintas curvas, reduje el rango de la gráfica
(perdiendo algunos de los primeros puntos) y le añadí 13% a Madrazo,
que el lector debe restar, como en la figura
1. Los datos parecen concordar con los de la figura
1, pero muestran un nivel mayor de fluctuaciones. El máximo en el
porcentaje de votos para Calderón se da cuando
ya había 4500 actas computadas y casi un millón de votos.
Figura 9
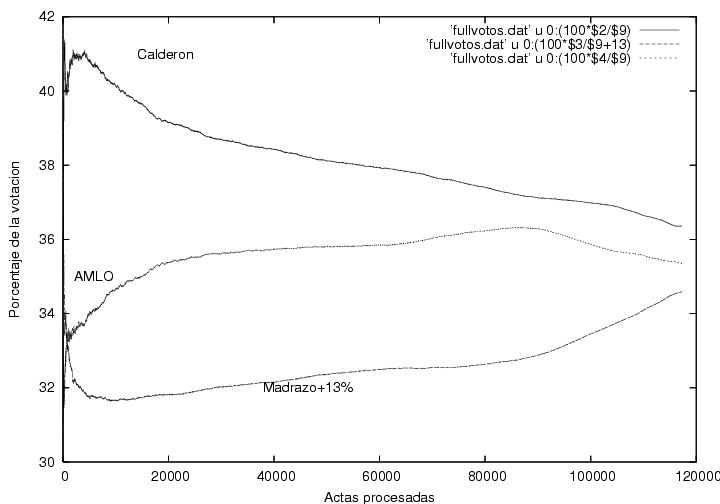
Datos (como en la figura 8).
Indice
Esta figura es análoga a la figura 2 pero como función del tiempo y no como
función de mi número de acceso (similar al tiempo). Las conclusiones
que se pueden derivar de ella son esencialmente las mismas. La
capacidad del PREP es de aproximadamente un acta por distrito cada
minuto. Esta gráfica es mucho más suave que la figura
2 y, como empieza mucho antes, muestra cómo la velocidad de arribo
de la información se incrementó gradualmente durante los primeros 200
mins. del conteo. Para poder observar esta región, multipliqué en ella
los datos por un factor de 1000. Las oscilaciones en la parte lineal de la figura 2 están aquí ausentes, y en particular, no se
ve el brinco de alrededor de la 1:00AM que previamente me había llamado la
atención. Quizás podría deberse a que el momento para realizar cada
actualización de la página del PREP estaba bajo control humano, no de
un código de computadora, y el encargado se fue a tomar un café
mientras el sistema seguía capturando datos de manera uniforme.
Figura 10

Datos (como en la figura 8).
Indice
La figura 11 muestra los votos obtenidos por cada
uno de los candidatos como función del tiempo de
conteo. Cualitativamente, la figura sigue las tendencias del número
total de votos.
Figura 11

Datos (como en la figura 8).
Indice
Esta figura muestra los votos como función del
número de actas procesadas. A diferencia de la figura
11, y de manera similar a la figura 3, en ésta el comportamiento
es básicamente lineal para los tres candidatos durante la mayor parte
del rango, con ligeras modificaciones visibles al principio y al final.
Figura 12
Datos (como en la figura 8).
Indice
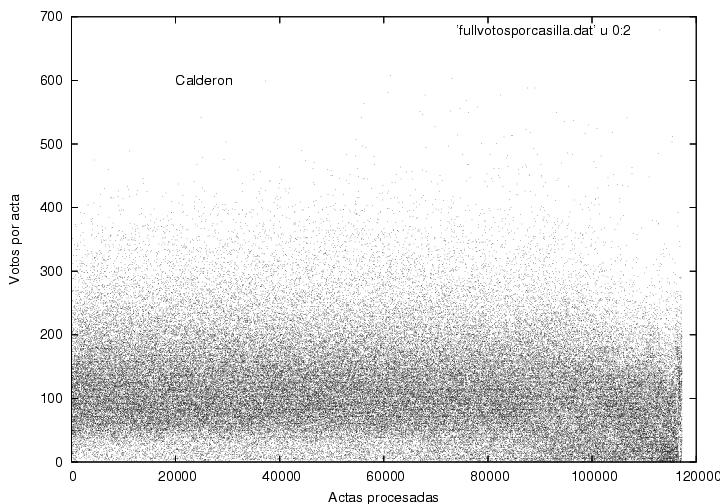
Las figuras 13, 14 y 15 muestran el voto obtenido en cada acta como
función del número de proceso de dicha acta para Calderón, Madrazo y
AMLO respectivamente. Cada punto en la gráfica corresponde a un
acta. Las regiones obscuras corresponden a resultados frecuentes y
deben ser cercanas a las votaciones promedio (como las
mostradas previamente en la figura 4. El ancho de
dichas regiones corresponde a las
dispersiones alrededor de los valores promedio. Qué tanto difieran dichas
regiones de ser franjas horizontales es una medida de las variaciones
de las preferencias electorales entre el electorado que fue contado
antes vs. después. Debe ser interesante (y fácil) rehacer este diagrama
para observar los promedios y variaciones de la preferencias de
acuerdo a la zona geográfica. Cuidado: Estas figuras pueden
mostrar una textura interesante pero que puede no ser
significativa. El voto en cada casilla es un número entero y puede
aparecer un batimiento entre las posiciones ocupadas por los puntos
que representan los datos y los pixeles de la pantalla de su computadora.
Es interesante notar que las figuras correspondientes al PAN muestra
una franja relativamente ancha, mientras que la del PRI es una franja
muy angosta. ¿Representará esto el llamado voto duro del PRI?
Por otro lado, la figura correspondiente al PRD muestra una franja
angosta pero con muchos puntos que caen arriba de dicha franja. Para
AMLO la distribución parece ser mucho más asimétrica que para sus
contendientes. Las
franjas claras en la parte baja de las gráficas de Madrazo y de AMLO
muestran que en casi todas las casillas obtuvieron al menos una o dos
decenas de votos. Por otro lado, la franja clara correspondiente a
Calderón está muy tenuemente marcada y parece desaparecer después de
la 90,000-ava casilla, lo cual implicaría que en un número significativo de
casillas recibió pocos o nulos votos. La franja clara correspondiente
a AMLO no desaparece, pero se adelgaza visiblemente en dicha
zona. Pareciera ser que entre las últimas actas recibidas, muchas
provinieron de regiones muy polarizadas en las que barría ya fuera uno
o el otro de los dos contendientes principales.
¿Por qué son tan distintos los
diagramas para cada candidato? ¿Por qué cambia el comportamiento de
los datos de Calderón y de AMLO después del acta 90,000?
Figura 13
Datos.
Figura 14
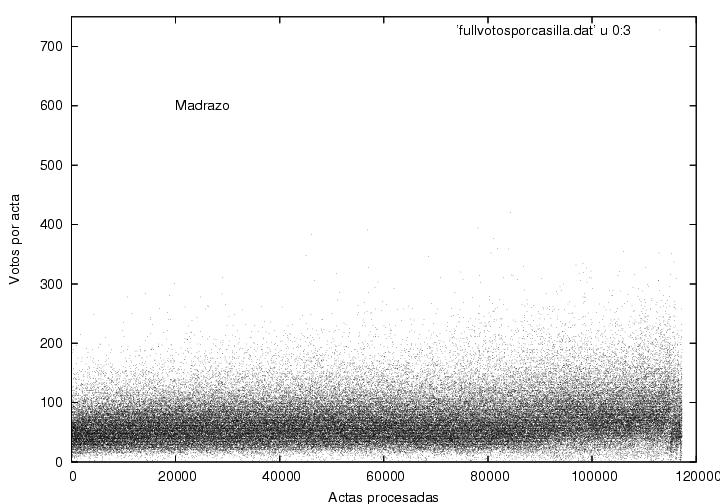
Datos.
Figura 15

Datos.
Indice
Para visualizar la distribución de votos de los candidatos principales
de manera más clara, en las figuras 16, 17 y 18
muestro los histogramas correspondientes a los datos de las figuras
13, 14 y 15. Cada punto en esta gráfica está determinado
por dos números: uno (el que leemos en el eje horizontal debajo de él)
representa un posible número de votos; el otro (el que leemos en el
eje vertical a su izquierda) representa en cuantas actas se reportó
ese número de votos.
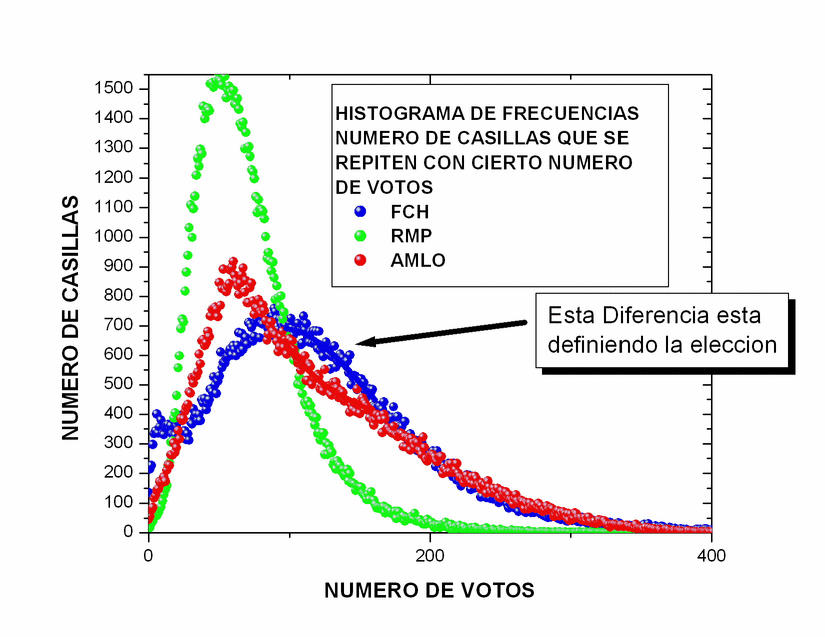
La figura 16,
correspondiente a Madrazo, muestra un comportamiento muy común en
procesos con cierta aleatoriedad. Tiene un máximo que resulta estar
en 53 votos con una altura de 1603 actas, i.e., obtuvo 53 votos
en 1603 de las cerca de 117000 actas.
A ambos lados del máximo, el número de actas
disminuye gradualmente con algunas fluctuaciones. Como el número
máximo de votos que podría haber obtenido es mucho mayor que 55 (del
orden de 700), mientras que el número mínimo de votos que pudo haber
sacado (0) es relativamente cercano a 55, el decaimiento hacia la
derecha es más lento que el decaimiento hacia la izquierda, i.e., su
distribución es unimodal (tiene un pico), y corresponde a
una curva suave ligeramente asimétrica. Se ve cualitativamente como la famosa
campana de Gauss pero deformada. Apenas obtuvo cero votos en un
manojo de actas.
Figura 16
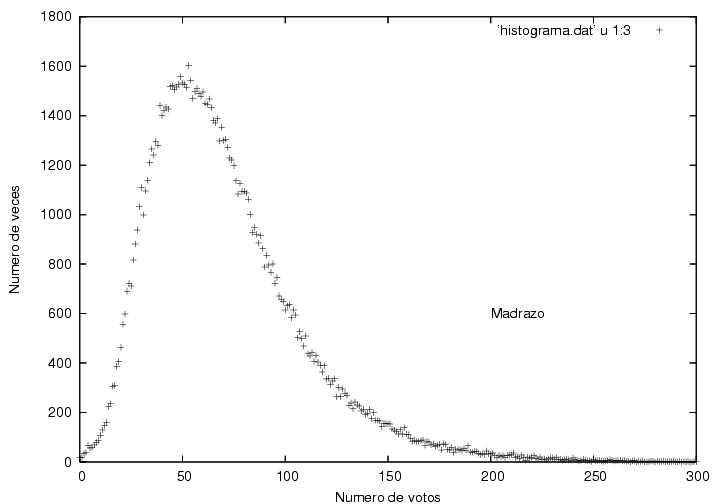
Datos.
Los datos correspondiente a AMLO se ven
bastante peculiares. Tienen un
máximo en una posición cercana al máximo de Madrazo, aunque con una
altura menor. A la derecha del máximo muestra
un decaimiento suave mucho más extendido que el de Madrazo pero
cualitativamente similar. Lo que me llama mucho la atención es que el
decaimiento hacia la izquierda del máximo no parece ser una curva
suave sino más bien podría describirse muy bien por una burda línea
recta, cuya ordenada al origen estaría entre 25 y 50 actas donde
habría obtenido 0 votos. De hecho, obtuvo 0 votos en 45 casillas.
A diferencia de la curva típica de Madrazo, la de
AMLO tiene un quiebre abrupto en el máximo. Las curvas usuales suelen
empezar con curvatura positiva, la cual cambia de signo antes de llegar al
máximo y vuelve a cambiar de signo a medio descenso. Esta curva podría
describirse como una curva típica a la que se le cortó una parte.
Figura 17
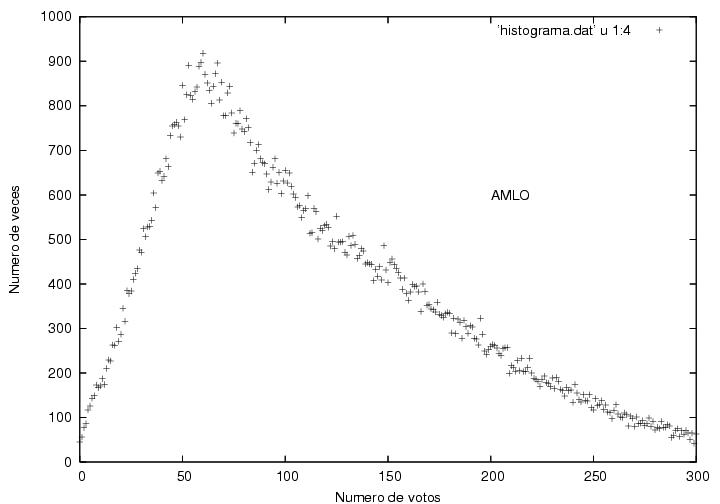
Datos.
Los datos correspondientes a Calderón son más
curiosos aún. Tienen un
máximo muy ancho cercano a los 80 votos por acta con una altura
cercana a 700 actas. Hacia la derecha tiene un decaimiento extendido y
suave cualitativamente similar al de AMLO. Hacia la izquierda, el
decaimiento comienza de una manera normal, con la misma forma que el
de Madrazo, pero cambia su
comportamiento pues aparece un segundo pico con un máximo cerca de 15
votos. La mayor parte de la contribución a este segundo pico se
debe a las actas que más tarde llegaron al IFE. Para ilustrar esta
afirmación, en la figura 19 se muestra el
histograma de la votación de Calderón correspondiente a las últimas
30,000 actas procesadas. Es sorprendente que la diferencia con la figura 18 sea tan grande. Era de esperar una curva
similar aunque con una altura menor y con
fluctuaciones más visibles por tener menos datos. En lugar de eso,
vemos que la parte derecha de la curva ha sido muy abatida, mientras
que la parte izquierda apenas empieza a cambiar su tamaño.
Estos datos tienen la forma típica que corresponde a
la suma de dos distribuciones distintas, cada una con sus propias
características. En este caso una describe la banda gris
horizontal previamente discutida y que se extiende a todo lo ancho
de la figura 13. La segunda distribución
corresponde a la región anómala que muestra la figura 13 sobretodo a partir del acta número
90,000. Las dos distribuciones parecen cruzarse alrededor de los 30
votos. Podemos eliminar la subjetividad en esta estimación, usando el
mínimo de la distribución, el cual está en 29 votos.
Consideremos un punto tomado de la figura 18,
correspondiente a H actas con N votos cada una. Ese
punto contribuye HxN votos en total. Sumando dichos
productos sobre todos los puntos desde que N es igual a cero y
hasta que sea igual a 29, donde se cortan las dos distribuciones,
podemos estimar el número total de votos que obtuvo Calderón a partir
de sumar la segunda distribución anómala: el número de actas en
que Calderón
obtuvo 29 o menos votos fue de 9,914; el número total de votos
contenidos en dichas actas fue de 149,329. Repitiendo el cálculo
sobre las últimas 30,000 actas procesadas obtenemos 4,788 actas con
70,678 votos, i.e., la mitad de los resultados correspondientes al
conteo total.
Una forma más cuantitativamente aceptable de hacer el cálculo previo
es mediante un ajuste en que se proponga cierto número de curvas
tomadas de una familia tal y como la familia de curvas Lorentzianas,
se optimizan los parámetros de cada una de las curvas de manera que su
suma sea la mejor aproximación posible a los datos, y finalmente se
integran las funciones analíticas resultantes para obtener el
número de actas y el número de votos contribuidos por cada una de las
distribuciones. Este trabajo está en curso con la colaboración de un
colega.
Figura 18

Datos.
Figura 19
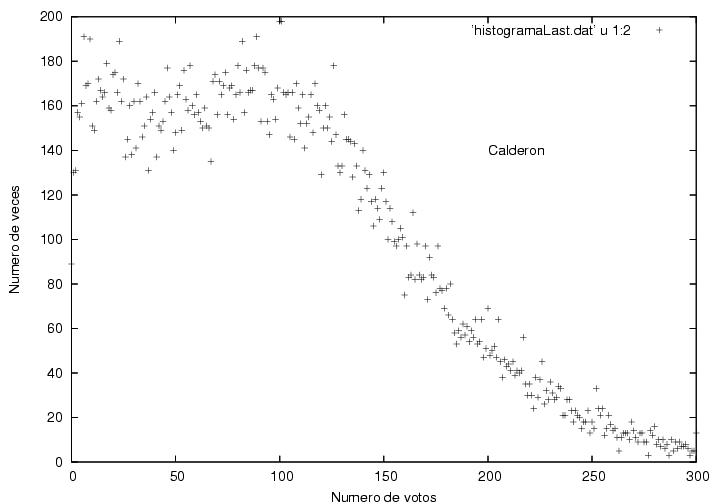
Datos.
Para que el lector lo pueda comparar, a continuación muestro los
histogramas correspondientes a Madrazo y a AMLO calculados con las últimas 30,000 actas. En
ambos casos, la forma del histograma
es igual a las correspondientes a los datos completos, 16 y 17, solo que escaladas
por contener menos datos.
Figura 20

Datos.
Figura 21
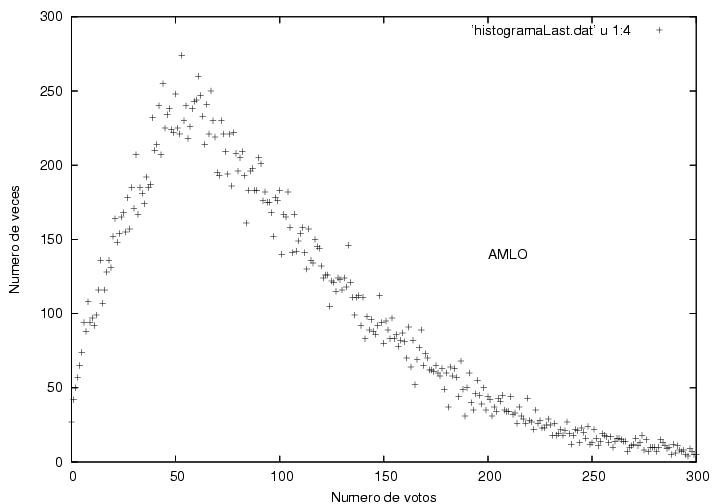
Datos.
Indice
Las
puede consultar aquí y aquí.
Un amigo (Jaime Ruiz) me mandó esta y esta gráfica, preparadas con mis mismos
datos, pero sobre un rango más grande. La primera muestra que Campa tiene una distribución
ordinaria y que en la payor parte de las casillas sacó menos de 10
votos. Por otro lado, la distribución de Patricia Mercado parace ser
una suma de dos distribuciones ordinarias, una que apenas se extiende
hasta 5 votos y otra hasta 30 votos.
Más importante me parece las curvas
corresondientes a Calderón, Madrazo y AMLO en la figura 21.2. Estas son las mismas que
mis figuras 16, 17 y 18, pero superpuestas y graficadas en un rango
mayor. En la figura se ve claramente que las curvas corresondientes a
Calderón y a AMLO son my cercanas entre sí y siguen un comportamiento
normal en la región correspondiente a actas con más de 180 votos cada
una. Sin embargo, cerca de 180 votos, la curva corerspondiente a AMLO
cambia abruptamente de pendiente situandose a la izquierda de
este punto por debajo de Calderón. No he podido encontrar una
explicación para este cambio abrupto. La parte superior de la curva de
Calderón se ve muy plana y ancha comparada con la de los otros dos
candidatos. Finalmente, es donde se vuelven a encontrar las dos
distribbuciones donde aparece la anomalía inferior de la curva de
Calderón, la cual tiene un cambio abrupto de pendiente volviéndose
horizontal en el extremo izquierdo. Note que el detalle en el extremo izquierdo de la curva
correspondiente a Patricia Mercado en la figura 21.1 se puede interpretar mediante la suma de dos
curvas suaves, mientras que el detalle a la izquierda de la curva de
Calderón aparece de un manera abrupta y poco natural.
Figura 21.1
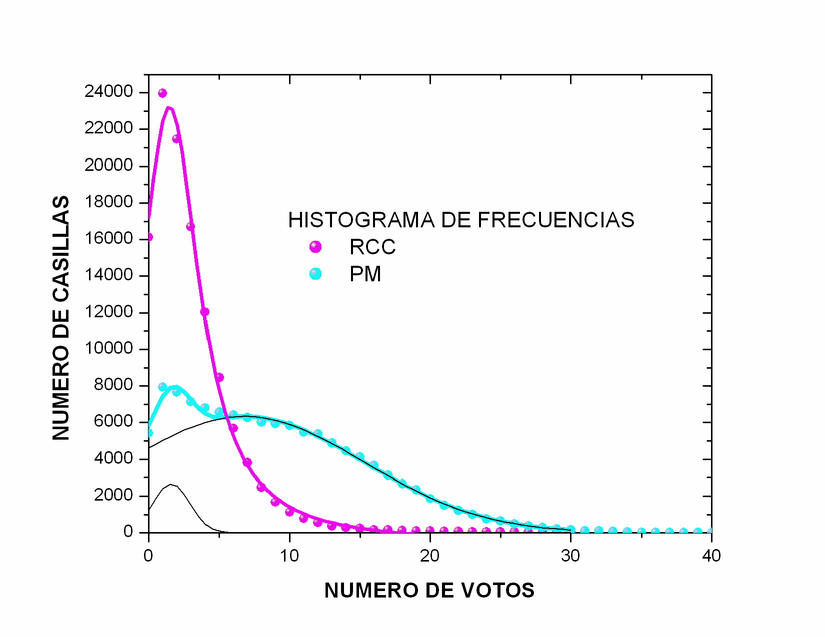
Datos.
Figura 21.2
Datos.
Indice
Es importante conocer las estadísticas de la diferencia de votos entre
Calderón y AMLO para poder entender la estructura de las figuras
17, 18 y 21.2. En la figura 21.5
muestro un histograma de esta diferencia. A lo largo del eje
horizontal se hallan la ventaja que Calderón podría haberle llevado a
López Obrador en alguna casilla. El eje vertical indica el número de
casillas en los que obtuvo precisamente esa diferencia. Si la
diferencia es negativa, simplemente significa que en las casillas
correspondientes López Obrador obtuvo más votos que Calderón.
A pesar de lo extrañas que son las curvas mostradas en la figura 21.2, el histograma de
las diferencias de votos tiene aparentemente una forma simple y
común. Es muy poco probable que las diferencias sean demasiado grandes
y conforme se hacen pequeñas dicha probabilidad aumenta gradualmente,
mostrando un máximo cercano a 0 votos de diferencia. Cualitativamente,
la curva parece una gaussiana normal. Sin embargo, los resultados
cerca de dicho máximo tienen un comportamiento muy distinto al de una
curva normal. Para guiar el ojo, hice un ajuste Gaussiano a todos los
datos que se hallan debajo de de la marca de las 250 actas. El ajuste
fue de la forma N=A exp(-B(V-C)^2), donde N representa el numero de
veces que Calderón le llevo V votos de ventaja a AMLO y A= 432.819+/-
4.352, B = 4.15445x10^{-05} +/- 3.944x10^{-07} y C = 0.126841+/-
0.3256 son los
parámetros del ajuste. Notamos que el ajuste es bueno
(no excelente) en la parte baja de la distribución, pero que
es pésimo en la parte alta. Intenté hacer un ajuste a todos los datos
en vez de emplear aquellos con N<250, pero la distorsión para N>250
es tan grande que el ajuste no fue bueno en ninguna parte. Regresando
al ajuste de las colas, de los
parámetros de la distribución notamos que su centroide está desplazado
una distancia muy pequeña hacia la derecha, es decir, que en promedio
Calderón le hubiera ganado a AMLO en 0.1 votos por casilla si
la distribución hubiese sido la gaussiana ajustada arriba, i.e.,
hubiera ganado la elección por 10,000+/- 30,000 votos aproximadamente. Sin
embargo, su ventaja fue mucho mayor gracias a la deformación en la
cima de la distribución. La distribución tiene un cambio discontinuo
de pendiente cerca de V=-100. ¿Por qué la distribución es
aproximadamente gaussiana en la mayor parte del intervalo? ¿Por qué la
distorsión en la parte alta de dicha distribución? ¿Por qué el cambio
de pendiente es abrupto al llegar a dicha distorsión?
Figura 21.5

Datos.
Indice
Parece ser que la distorsión en la parte alta de la distribución
mostrada arriba es la responsable del aparente
triunfo de Calderón. Para cuantificar su contribución, en la figura 21.6 muestro la diferencia entre los datos
del PREP y la curva ajustada. Para diferencias de votos menores a -100
y mayores a 100 o 150, el resultado es el esperado, i.e., los puntos
se distribuyen más o menos simétricamente alrededor de cero (línea
horizontal). Sin embargo, en la región entre -100 y 0 los datos están
sistemáticamente desplazados hacia abajo y entre 0 y 100 están
sistemáticamente desplazados hacia arriba, con un mínimo cerca de -50
y un máximo cercano a 80. Es decir, hay menos casillas en las que AMLO
gano por poco que las que seguirían de la distribución
normal, y hay más casillas donde Calderón ganó por pocos votos que las
que predice la distribución normal. Como si los datos de las actas con
poca diferencia migrado hacia la derecha. El número de actas
anómalas se puede estimar de integrar la figura en los
intervalos de -100 a 0 o de 0 a 100, resultando entre 2,000 y 4,000
actas. La contribución de la región entre -100 y 100 se puede estimar
de multiplicar el tamaño de la anomalía por el número de votos
involucrado y sumar dentro de la misma región, y conduce a una ventaja
de 357,000 a favor de Calderón por encima de AMLO.
¿Cual es el origen
de la bajada y subida en esta figura?
Figura 21.6

Datos.
Indice
La figura 22 es similar a la figura 6 pero elaborada con la base de datos
detallada. Se muestran tres curvas que corresponden a las votaciones
obtenidas por los tres candidatos principales en el intervalo
[0:20000], i.e., completando los datos que en la figura 6 sólo
podíamos adivinar. Desde luego, las tres curvas pasan por el
origen. Se muestran otras tres curvas que fueron obtenidas de un
ajuste lineal a los datos del rango [10000:20000]. Los parámetros de
dicho ajuste se pueden leer en la llave de la figura (disculpas por no
haberlas puesto en el orden previo): las pendientes son 126.731,
63.1543 y 120.122 y las ordenadas al origen son -7143, -49301 y
-121637 para Calderón, Madrazo y AMLO respectivamente. La calidad del
ajuste se puede apreciar al extrapolarlo hacia
toda la gráfica aquí.
Figura 22
Datos.
Figura 23
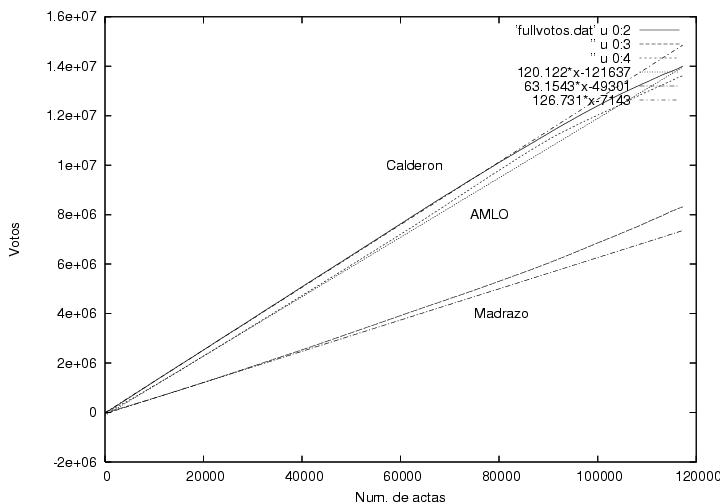
Datos.
Indice
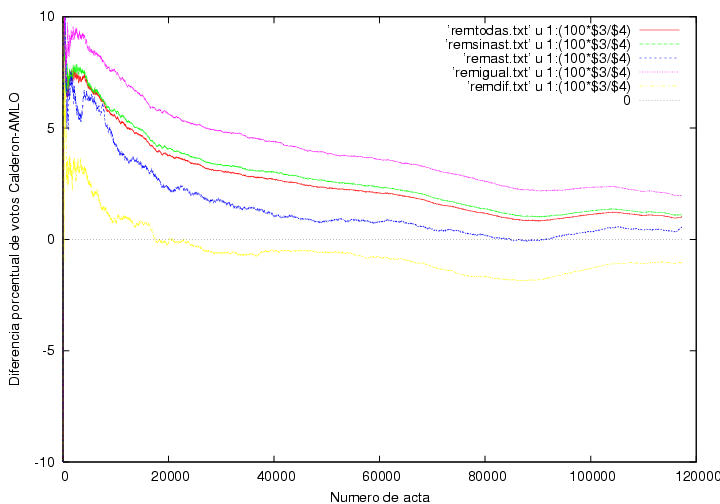
La figura 23.1 es equivalente a la figura 5, pero elaborada con todos los datos de la bases de datos del PREP, casilla por
casilla. Se muestran varias curvas correspondientes a:
- Todos los
registros de la base de datos (cambiando asteriscos por ceros donde era
necesario): remtodas.txt.
- Todos los registros completos, i.e., sin asteriscos:
remsinast.txt.
- Unicamente los registros incompletos, i.e., con asteriscos:
remast.txt.
- Todos los registros completos y consistentes, i.e., sin
asteriscos y con el mismo número de votantes que de boletas
depositadas: remigual.txt.
- Todos los registros completos pero inconsistentes, i.e., sin
asteriscos pero con número de votantes distinto al número de boletas
depositadas: remdif.txt.
Notamos que la curva obtenida con todos los datos es cualitativamente
similar a la obtenida de la captura de datos la
noche de la elección. La
diferencia final de votos es ligeramente inferior a 400,000. Por algún
motivo no es idéntico al resultado
final del PREP, 402708, aunque la diferencia es pequeña.
Al eliminar los registros 22,538 registros incompletos, la diferencia de votos
disminuye ligeramente. Esto parece consistente con la premisa de que
los asteriscos corresponden a errores azarosos sin correlación alguna
con las preferencias electorales. Sin embargo, esto no es del todo
correcto. Las actas con asteriscos representan el 18% del total y su
contribución a la ventaja de Calderón es mucho menor. Es curioso que
entre las 60,000 y las 100,000 actas, donde la ventaja de Calderón
disminuye y vuelve a aumentar, la contribución del número de actas con
asteriscos disminuye hasta llegar a cero.
Si adicionalmente, eliminamos los 27,073 registros con inconsistencias
la ventaja de Calderón aumenta en lugar de disminuir en la
proporción de registros eliminados. Consistentemente con esta
peculiaridad, observamos que AMLO domina fuertemente la votación sobre
estos registros inconsistentes.
La figura 23.2 muestra los mismos resultados
que la 23.1, pero expresados en términos del
porcentaje de dichos datos. Así, podemos ver que de entre el universo
de actas con inconsistencias, la preferencia por AMLO es de poco más del 1%.
¿Por qué se correlacionan los errores y las inconsistencias
con la preferencia hacia AMLO?
El IFE ha preparado una respuesta
a algunos de los puntos mencionados arriba, en otras partes de esta
página y en una nota enviada al
Dr. Woldenberg. En ella, afirma que
Respuesta (ii):Las actas qu presentan inconsistencias no se
relacionan directamente con la votación a favor de la Coalición por el Bién de Todos (elección presidencial).
Sin embargo, más adelante se aclara el significado de esta frase: el
valor de la correlación de Pearson entre el porcentaje de actas
inconsistentes en un estado tiene y el porcentaje de votación que obtiene la
coalición PBT en dichas actas es pequeño (0.231). Mi pregunta arriba
es más sencilla. ¿Por qué los resultados de las actas con
inconsistencias son distintos al resultado global de la elección? ¿Por
qué tiene que ver (ergo, están correlacionados) el hecho de haber
cometido errores en ciertas casillas con el resultado de la elección
en dichas casillas?
Por otro lado, el análisis que sigue en la respuesta se refiere a las actas que se
omitieron inicialmente del PREP, no a las actas inconsistentes dentro
del PREP original.
Figura 23.1
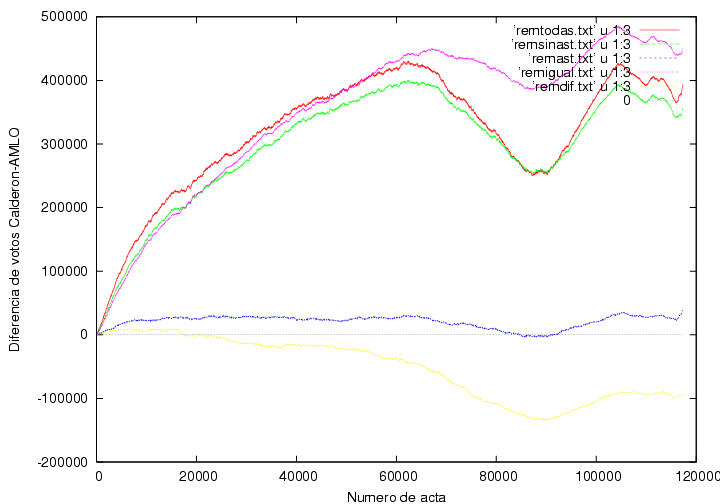
Datos.
Figura 23.2
Datos.
Indice
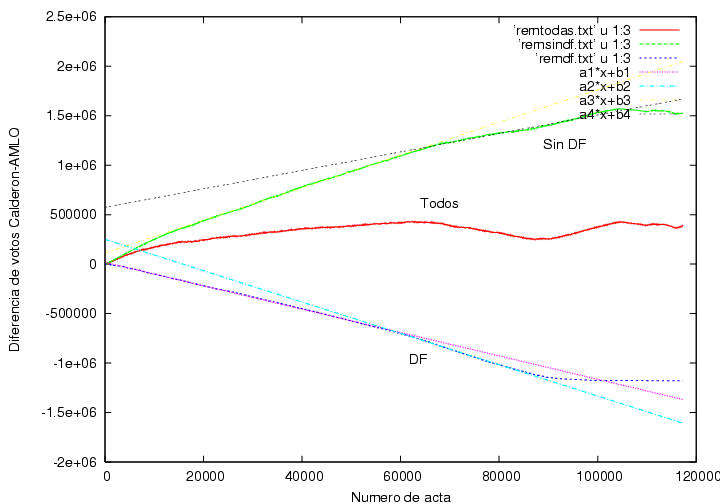
En un intento más de entender los cambios abruptos de pendiente que
muestran las gráficas 5 y 23.1, en la figura 23.3 grafico la contribución de todas las actas
que contiene el PREP (remtodas.txt) a la diferencia de votos acumulada
entre Calderón y AMLO, la contribución a ésta del DF (remdf.txt) y los
resultados que se hubieran obtenido si
elimináramos al DF (remsindf.txt). Es curioso que el DF muestra por sí
solo un cambio bastante grande de
pendiente. Por ejemplo, la región antes de la llegada del acta número
60,000 está muy bien descrita por una recta de pendiente -11.82
mientras que la región entre 60,000 y 90,000 queda bien descrita por
una recta de pendiente -15.83. Este
resultado muestra que una contribución importante al cambio de pendiente
en la curva completa proviene de zonas urbanas exclusivamente, i.e.,
no es cierto que la diferencia provenga del agotamiento del voto urbano
y de la llegada súbita del voto rural, como se ha repetido varias
veces en la prensa. Un ejercicio curioso consiste en extrapolar la
región entre 60,000 a 90,000 votos hacia el origen. La ordenada al
origen resultante es de 250,132 votos. Sin embargo, el cambio de
pendiente no se puede atribuir exclusivamente a la población urbana
del DF, pues la curva correspondiente a todos los estados restantes
también muestra un cambio abrupto de pendiente y también sucede este
cambio alrededor cerca (ligeramente después) de las 60,000 actas
procesadas. La pendiente antes de 60,000 es de 16.50 y la pendiente
después de 65,000 es de 9.33. Si extrapolamos la región entre 65,000 y
100,000 hasta el origen obtenemos una ordenada al origen de 574,218
votos. ¿Acaso se sincronizaron varios estados y el DF para procesar actas con
resultados notablemente distintos a partir del acta número 60,000-65,000?
¿Qué mecanismo pudo haberlos coordinado?
Otro argumento contra la explicación del comportamiento de las figuras 5 y 23.1, se halla en esta gráfica preparada por Victor
Romero, la cual muestra la velocidad de llegada de las casillas
urbanas y rurales. Dicha velocidad no tiene ninguna estructura abrupta
correspondiente al comportamiento de las figs. 5 y 23.1.
Figura 23.3
Datos.
Indice
Las figuras 23.1 y 23.2
muestran que las casillas con errores arrojan resultados muy distintos
a las casillas sin inconsistencias entre el número de votantes y el
número de boletas depositadas. Por otro lado, la dependencia temporal
de dichas figuras se ha atribuido repetidamente a las diferencias
entre el comportamiento del voto rural con respecto al voto
urbano. Por ello me pareció que podría ser interesante ver si la
presencia misma de inconsistencias tiene un orden temporal,
presuntamente correlacionado con la preferencia electoral y con el
origen del acta. En la figura 23.4 muestro el
exceso de votos por encima del número de boletas como función del
número de actas procesadas en el PREP. Una de las curvas corresponde
únicamente a las casillas en las que el número de votos supera al
número de boletas. Otra corresponde a las casillas donde el número de
boletas supera al número de votos. Finalmente, la curva de enmedio
toma en cuenta todas las inconsistencias. Curiosamente, la figura 23.1 muestra que los errores están correlacionados
con las preferencias electorales y que las preferencias electorales
están correlacionadas con el tiempo de arribo de las actas. A pesar de
ello, de acuerdo a la figura 23.4 los errores de
todo tipo se acumulan de manera lineal en el tiempo, i.e., ¡los
errores no dependen del tiempo!
Figura 23.4

Indice
El IFE ha preparado una respuesta
a algunos de los puntos mencionados arriba, en otras partes de esta
página y en una nota enviada al
Dr. Woldenberg.
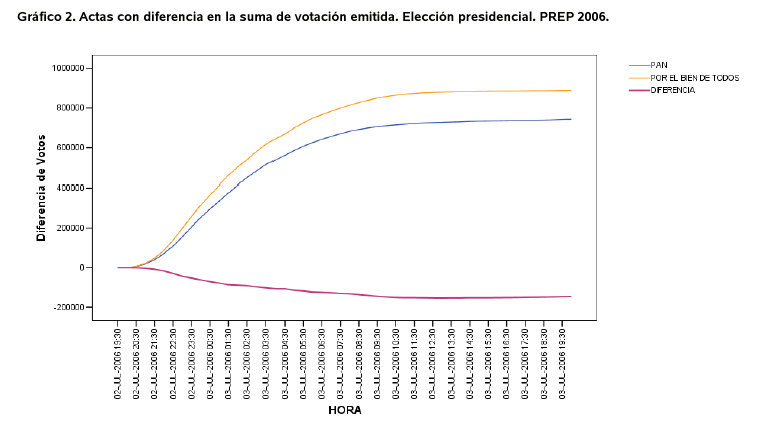
En parte de dicha respuesta el IFE preparó una gráfica muy
interesante. En la figura 23.4B se muestra el
número de votos que obtuvo el PAN, la coalición PBT y su diferencia
como función del tiempo. Comparando dicha figura con la figura 10 vemos la curva que describe los votos acumulados
sobre estas actas para cada candidato tienen la misma forma que la
curva que describe el número total de votos como función del
tiempo. Más aún, la curva que describe la diferencia de votos entre
PAN y PBT también tiene la misma forma que la que describe la llegada
total de votos.
Citando textualmente la respuesta del IFE (página 6),
Dicho diferencial muestra una trayectoria consistente con los
resultados del Programa de Resultados Electorales Preeliminares. Es
decir, la contribución de votos contenidos en las actas con
inconsistencias no muestra baches ni estancamientos en su trayectoria,
y por lo tanto no hay ningún indicio de una supuesta manipulación de
las actas para perjudicar a algún partido o coalición en particular.
Dicho comportamiento es lo que uno esperaría en una votación en la que
los votos llegan prácticamente al azar de diversos tipos de
poblaciones distribuidas geográficamente por todo el país.
Sin embargo, la figura 23.1 muestra que la
diferencia de votos entre el PAN y la coalición PBT calculada sobre
todas las actas contabilizaqdas en el PREP no sigue las tendencias del
número total de votos y sí muestra baches y estancamientos. De acuerdo
a la frase citada arriba, ¿no es razonable suponer que pudo haber una
manipulación de las actas para perjudicar a algún partido o coalición
en particular?
Figura 23.4B
Indice
Una explicación tentativa para las aparentes anomalías en la
dependencia temporal de los datos del PREP radica en el orden en que
fueron llegando y siendo procesadas las actas. Para visualizar este
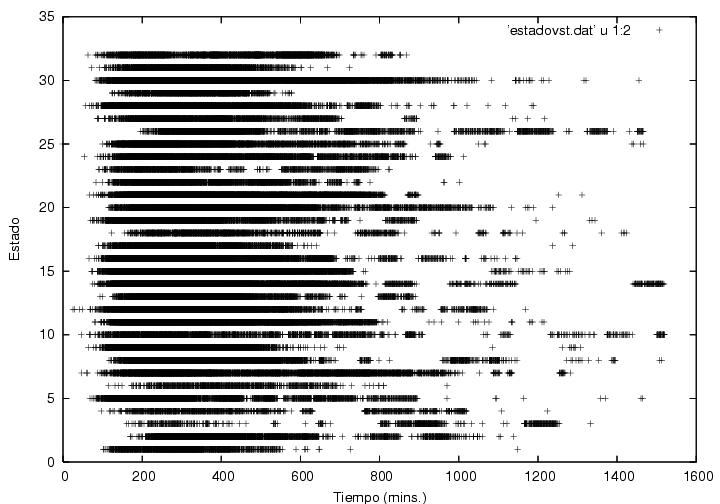
orden, las gráficas (figuras 23.5 y 23.6 muestran el orden de proceso de las actas
separadas por estado. El eje horizontal representa el tiempo en
minutos a partir de las 6:35 del 2 de julio o bien el número de acta
procesada. El eje vertical es un número entre 1 y 32 que corresponde
alfabéticamente al nombre de algún estado (ver listas tras las
figuras). Cada punto en la gráfica representa el proceso de un acta
individual. Con ayuda de la tabla de datos vemos que la primera acta
en llegar fue de Sinaloa, la segunda, tercera y cuarta de Guerrero, la
quinta de Durango, al igual que las últimas 2, etc. Como podría
haberse esperado, las actas que más tardaron en empezar a llegar
fueron las de Baja California, Baja California Sur y Sonora (huso
horario) así como Colima y Nayarit. En algunas entidades como Baja California
Sur, las actas se concentran en varios grupos, lo cual quizás
corresponda a las distancias que había que recorrer para llegar de
diversas ciudades a las oficinas distritales correspondientes. Otras
entidades tienen colas que se extienden hacia tiempos largos,
quizás por dificultades geográficas de acceso a lugares
remotos. Otras como Tlaxcala tienen distribuciones que se cortan
abruptamente. Al hacer la gráfica como función del número de acta, las
distribucinoes aparecen más extendidas y podemos distinguir un poco la
densidad de actas procesadas en cada entidad. De un análisis
somero de la figura 23.6 no alcanzo a
ver ningún cambio significativo alrededor de las 70,000 actas
procesadas, donde AMLO comienza a remontar la diferencia de votos con
Calderón de acuerdo a la figura 5. Quizás lo más
notable es que en ese punto Quintanta Roo ha disminuido su
contribución y Colima, que había estado muy retrasada, aumenta su
flujo de información. Tampoco veo nada espectacular entre 90,000 y
100,000, donde se revierte la tendencia y AMLO empieza a perder de
nuevo. Sin embargo, al llegar a 100,000 actas procesadas se agotan las
actas de Aguascalientes, DF, Morelos, Tlaxcala y Yucatán, y aumenta
abruptamente el
número de actas recibidas de Quintanta Roo, y menos dramáticamente, de
Colima. De manera que no veo claramente la correlación entre la
entrada y la salida de las diversas entidades con el comportamiento de
la diferencia de votos entre los candidatos. Quizás la subida de
Calderón vs. AMLO después de contabilizar 100,000 actas se deba al
final del proceso en el DF. El comportamiento de
Quintana Roo es curioso, pues envía actas a procesar al principio y al
final, pero tiene un hueco en medio. Los primeros 100 minutos del PREP
fueron curiosos (figura 8), pues al principio el
voto fue fuertemente priista y después se volvió fuertemente
panista. A los primeros 50 minutos contribuyeron Guerrero (con 4
actas), Chiapas (1), Durango (1), Sinaloa (1) mientras que de los 50 a
los 100 minutos contribuyeron todos los estados menos Aguascalientes,
Baja California, Baja California Sur, Campeche, Colima, Chiapas,
Nayarit, Oaxaca, Sinaloa, Sonora y Tlaxcala. (Figura 23.7)
Figura 23.5
Datos.
Lista de estados: 1 Aguascalientes, 2 Baja California, 3 Baja California Sur, 4
Campeche, 5 Coahuila, 6 Colima, 7 Chiapas, 8 Chihuahua, 9
Distrito Federal, 10 Durango, 11 Guanajuato, 12 Guerrero, 13 Hidalgo,
14 Jalisco, 15 Mexico, 16 Michoacan, 17 Morelos, 18 Nayarit, 19 Nuevo
Leon, 20 Oaxaca, 21 Puebla, 22 Queretaro, 23 Quintana Roo, 24 San
Luis, 25 Sinaloa, 26 Sonora, 27 Tabasco, 28 Tamaulipas, 29 Tlaxcala,
30 Veracruz, 31 Yucatan, 32 Zacatecas.
Figura 23.6
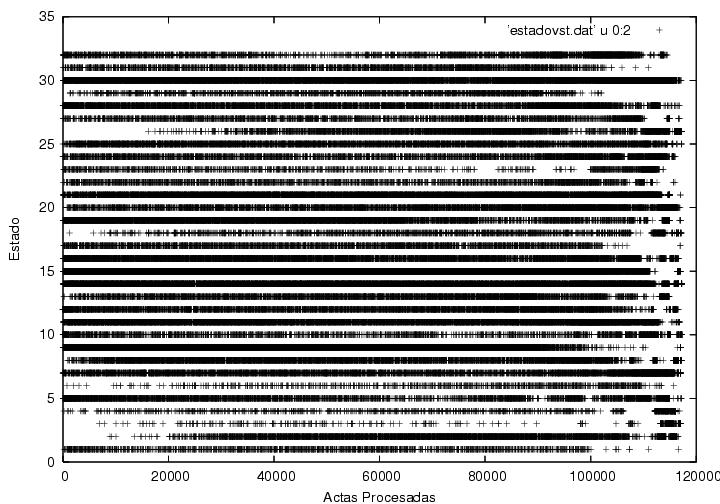
Datos.
Lista de estados: 1 Aguascalientes, 2 Baja California, 3 Baja California Sur, 4
Campeche, 5 Coahuila, 6 Colima, 7 Chiapas, 8 Chihuahua, 9
Distrito Federal, 10 Durango, 11 Guanajuato, 12 Guerrero, 13 Hidalgo,
14 Jalisco, 15 Mexico, 16 Michoacan, 17 Morelos, 18 Nayarit, 19 Nuevo
Leon, 20 Oaxaca, 21 Puebla, 22 Queretaro, 23 Quintana Roo, 24 San
Luis, 25 Sinaloa, 26 Sonora, 27 Tabasco, 28 Tamaulipas, 29 Tlaxcala,
30 Veracruz, 31 Yucatan, 32 Zacatecas.
Figura 23.7
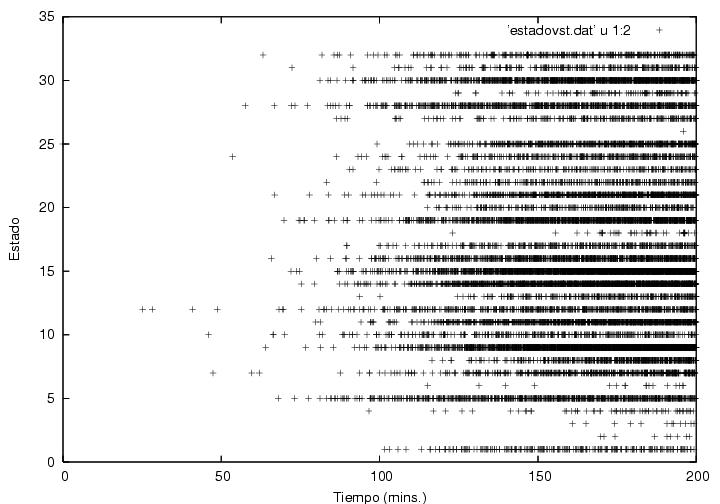
Datos.
Lista de estados: 1 Aguascalientes, 2 Baja California, 3 Baja California Sur, 4
Campeche, 5 Coahuila, 6 Colima, 7 Chiapas, 8 Chihuahua, 9
Distrito Federal, 10 Durango, 11 Guanajuato, 12 Guerrero, 13 Hidalgo,
14 Jalisco, 15 Mexico, 16 Michoacan, 17 Morelos, 18 Nayarit, 19 Nuevo
Leon, 20 Oaxaca, 21 Puebla, 22 Queretaro, 23 Quintana Roo, 24 San
Luis, 25 Sinaloa, 26 Sonora, 27 Tabasco, 28 Tamaulipas, 29 Tlaxcala,
30 Veracruz, 31 Yucatan, 32 Zacatecas.
Indice
El Dr. Markus Mueller y el Dr. Christian Rummel son expertos en la
búsqueda de correlaciones entre múltiples señales. Sus
investigaciones les han permitido identificar precursores a ataques
epilépticos a partir
de anomalías en las correlaciones entre las señales que producen
múltiples electrodos en el cerebro de pacientes epilépticos. Ellos han
aplicado recientemente sus técnicas de análisis al estudio de las
funciones de correlación de las votaciones recientes. La figura 23.8
muestra una de sus gráficas. El eje horizontal es el número de acta
procesada en el PREP y el eje vertical es la función de correlación
mutua Cfc,amlo entre los votos recibidos por FC y por
AMLO. La correlación mutua está definida como
Cfc,amlo=<vfc vamlo>, en donde
<X> denota el promedio de cualquier cantidad X, y
vj=(Vj-<Vj>)/σj
denota el número normalizado de votos recibido por el j-ésimo
candidato, donde Vj es el número de votos en una casilla,
<Vj> es el número promedio de votos obtenido por
casilla y σj es la desviación estandard de los votos
obtenidos, la cual es una medida de sus fluctuaciones. Para elaborar
la figura 23.8, los doctores Mueller y Rummel hicieron promedios sobre
una ventana de 1,000 casillas, la cual fueron deslizando hacia la
derecha acta por acta para generar cada punto de la curva. De
acuerdo a las definiciones empleadas, la correlación máxima posible es
1, correspondiente a una correlación perfecta. La correlación mínima
es -1, correspondiente a una anticorrelación perfecta. Si los datos
correspondientes a un candidato variaran de manera independiente de
los datos correspondientes al otro candidato, la correlación sería
cero.
Una gran ventaja de las correlaciones estudiadas por los Drs. Mueller
y Rummel estriba en que los promedios y las desviaciones estandard son
recalculadas para cada punto de la gráfica. Esto implica que
cualquier dependencia sistemática de dichas cantidades es
eliminada de los resultados. Por ejemplo, si fuera cierto que el
número promedio de votos obtenido por algún candidato variara
debido a
que el voto pasa de ser urbano a ser rural, o si las fluctuaciones en
dicho voto variaran por pasar de una región heterogénea a una región
homogénea, dichos cambios no se manifestarían en el resultado
final pues se ha restado el voto promedio y se ha dividido entre
la desviación estandard al definir las cantidades vj. Por
lo tanto, cualquier variación sistemática en figuras normalizadas tal
y como la figura 23.8 es necesariamente mucho
más sospechosa que una variación sistemática en figuras tales y como
la figura 23.1.
El resultado esperado en una votación con cinco candidatos sería
similar a la figura 23.8A, correspondiente a
la correlación entre
Patricia Mercado y Roberto Campa. Como el muestreo es finito
(promedios sobre 1,000 actas), se presentan grandes oscilaciones que
van desde casi -1 hasta casi 1. Como los votos que no recibe un
candidato los puede recibir cualquiera de los otros, las correlaciones
fluctuan alrededor de cero, i.e., los votos obtenidos por cada
candidato fluctuan de manera independiente de los obtenidos por otros
candidatos.
Como en esta elección hubo tres candidatos más fuertes que los demás,
uno podría esperar una ligera correlación entre ellos. Sin embargo, la
figura 23.8 muestra resultados muy distintos. Después de las primeras
5,000 actas procesadas, aparece una fuerte anticorrelación entre FC y
AMLO con fluctuaciones no estacionarias que gradualmente se van
incrementando pero que repetídamente regresan al valor mínimo
permitido. Sin embargo, pasando el acta número 60,000 la
anticorrelación se vuelve casi perfecta de una manera
espectacularmente abrupta y las fluctuaciones desaparecen casi del
todo. Más aún, cerca de las 85,000 actas procesadas la anticorrelación
perfecta cambia discontínuamente y se vuelve una correlación perfecta
con fluctuaciones que desaparecen casi del todo arriba de las 90,000
actas.
Un análisis detallado del cálculo de los Drs. Mueller y Rummel mostró
que ellos tomaron como variable Vj los porcentajes de la
votación acumulada por cada uno de los candidatos. Esto podría
explicar el por qué sus
correlaciones muestran variaciones tan abruptas justo donde las
figuras 5, 23.1 y 23.3. Ahora (8/viii/06) dichos cambios no me
parecen más extraños que los cambios de pendiente abruptos de las
figuras 5, 23.1 y 23.3.
En este directorio hallará todas las funciones
de correlación cruzadas, así como los eigenvalores de la matriz de
correlación en escala lineal y logarítmica. Las correlaciones que
involucran a Nueva Alianza se ven casi normales. Todas las demás
tienen regiones fuertemente anómalas.
En este otro hallará los resultados
análogos correspondientes a los Cómputos Distritales.
Figura 23.8
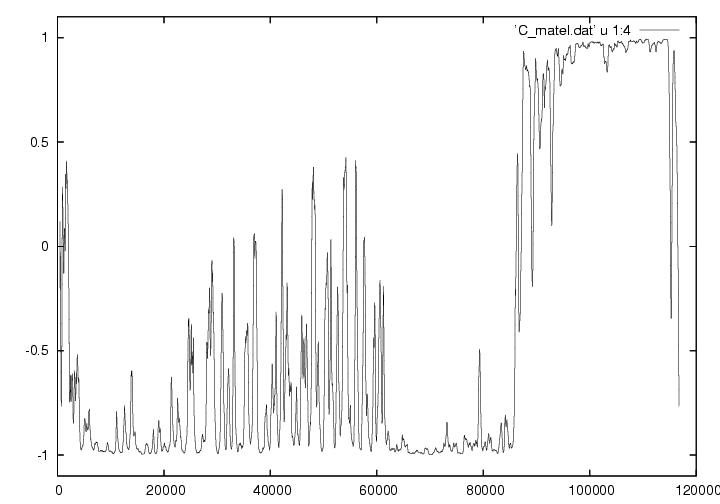
Figura 23.8A

Indice
La figura 23.8B muestra las funciones de
correlación mutuas entre distintos candidatos empleando los mismos
métodos que para las figuras 23.8 y 23.8A, pero empleando como variable Vj
el número de votos absolutos recibido por el j-ésimo candidato en cada
casilla. El resultado esperado es similar a la correlación entre el
PAN y la APM, i.e., la correlación es nula, excepto por pequeñas
fluctuaciones debidas a que los promedios se realizan sobre una
ventana movil que contiene 1000 actas. Si la ventana fuera más
pequeña, las fluctuaciones serían más grandes y si la ventana fuera
más grande las fluctuaciones serían más pequeñas. Sin embargo, vemos
que hay una anticorrelación entre la APM y la coalición PBT de
alrededor de -0.2, la cual empieza a disminuir a partir de las 60,000
actas y llega a una ligera correlación cercana a 0.1 después de pasar
las 90,000 actas. Por otro lado, el PAN y la PBT están aún más
anticorrelacionados (-0.4) al principio del PREP. Dicha
anticorrelación desaparece gradualmente conforme se contabilizan más
actas.
Una anticorrelación entre dos candidatos significa que si en
cierta acta un partido obtiene una votación superior a su promedio, es
más probable que el otro candidato obtenga una votación inferior a su
promedio. Si sólo hubiera dos candidatos y si todas las actas tuvieran
exactamente el mismo número de votos totales, habría anticorrelación
perfecta, pero se espera que ésta se destruya al haber varios
candidatos, además de haber candidatos independientes y votos nulos, y
al haber fluctuaciones entre el número total de votos que reciben
distintas casillas.
Las correlaciones entre todos los candidatos, incluyendo no
registrados, y sus correlaciones con el número de votos nulos, número
de votantes, etc. pueden hallarse en este directorio.
Figura 23.8B

Indice
Un problema en muchos de los resultados que muestro en esta página es
que no es claro que significa normal, y por lo mismo, qué
significa anómalo. Sería ideal contar con análisis similares para
muchas otras elecciones, pero eso requiere tener a mano los datos (y el
tiempo para analizarlos). Sin embargo, el dos de julio hubo otras
elecciones para las cuales tenemos todos los datos, i.e., la elección
para diputados y para senadores. Hernán Larralde me sugirió comparar
las funciones de correlación entre estas elecciones. En
la figura 23.8C muestro las funciones de
correlación entre los votos obtenidos por el PAN y la coalición PBT,
como en la figura 23.8B, pero incluyendo ahora
los datos de las otras dos elecciones. Se observa las tres funciones
de correlación muestran esencialmente la misma forma y las mismas
estructuras, y de hecho, las curvas correspondientes a diputados y a
senadores son prácticamente las mismas. Sin embargo, la curva para
presidente se aparta de las otras dos hasta en un 10%. El resultado es
similar para todas las demás funciones de correlación entre todos los
pares de partidos: las correlaciones para diputados y senadores
coinciden entre sí, pero difieren en más o menos 0.1 de las
correlaciones para presidente. En algunos casos las correlaciones para
presidente son mayores y en otras menores. Los distintos elementos de
la matriz de correlación se hallan en este directorio. ¿Por qué coinciden las
correlaciones para diputados y senadores y por qué difieren de las de
presidente?
Figura 23.8C
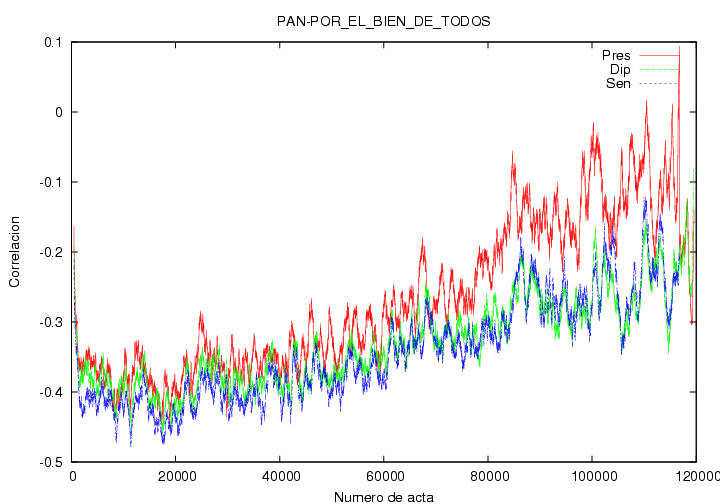
Indice
Raymond Hall hizo un análisis A (la cadena empieza aquí) de los porcentajes de
votación obtenidos por cada candidato como función de tres tiempos
distintos, la hora de recepción de las actas en el comité distrital (Rec),
la hora en que se capturan los resultados en la base de datos central
(Cap) y la hora en que debió haber sido capturada (Est) estimada
mediante la suma del tiempo promedio de espera a la hora de recepción. Uno
hubiera esperado para cada candidato tres curvas similares,
quizás desplazadas una de la otra debida al retraso natural en el
proceso, y quizás estiradas y comprimidas a lo largo del eje del
tiempo debido a las variaciones naturales en la velocidad del
proceso, sobre todo cerca de las horas pico de trabajo. Estas
deformaciones deberían ser comunes a los resultados de todos los
candidatos. Sin embargo, los resultados muestran estructuras
adicionales que no se comparten entre los distintos
candidatos. Pareciera que el retraso en la incorporación de los datos
de cada acta al sistema estuviera correlacionado con los resultados
del acta o con su procedencia.
Figura 23.9

Indice
AL principio de la votación, el número de actas arriban a los centros
de acopio y transmisión de datos más rápidamente de lo que pueden
procesarse, por lo que hay un retraso entre su registro y su captura y
las mismas se acumulan gradualmente. En la figura 23.10 muestro el número total de actas acumuladas
como función del número de acta recibida. Para producir dicha figura
fue necesario alterar los datos oficiales, pues los mismos
son erróneos. Las horas de recepción de las actas en los CEDATs fue
colocada a mano y tiene múltiples errores, de manera que hay actas
aparentemente recibidas antes de iniciada la elección, miles de actas
recibidas antes de cerrada la elección, actas que tardarton más de 24
horas en procesarse (quizás por haber asentado mal la fecha), actas
que tardaron más de 12 horas en procesarse por reportar la hora en
formato de 12 y no de 24 horas y actas que se procesaron unos minutos
antes de haberse recibido.
Aquí incluyo la base de datos corregida y ordenada por tiempo de
recepción.
En la figura vemos que cuando se han
recibido unas 70,000 actas, aproximadamente se han capturado dos
terceras partes de ellas y una tercera parte, poco más de 20,000, se
halla esperando en fila.
La primera parte de la curva muestra un comportamiento
casi lineal con una pendiente de 1/3, es decir, se acumula una de cada
tres actas que llegan. Después de haberse recibido 80,000 actas, el
ritmo de llegada se vuelve menor al ritmo de captura y el tamaño de la
pila de actas empieza a disminuir. Así, entre las 87,000 y 93,000 el
comportamiento es otra vez lineal y por cada dos actas que llegan la pila
disminuye su altura en tres actas, es decir, se procesan cinco actas
cada dos que llegan. Finalmente, a pesar de que cada vez se reciben las
actas más lentamente, vuelve a cambiar la pendiente y la pila
disminuye de tamaño en sólo 9 actas cada 40 actas que arriban, es
decir, se procesan 49 actas por cada 40 que se reciben.
Figura 23.10
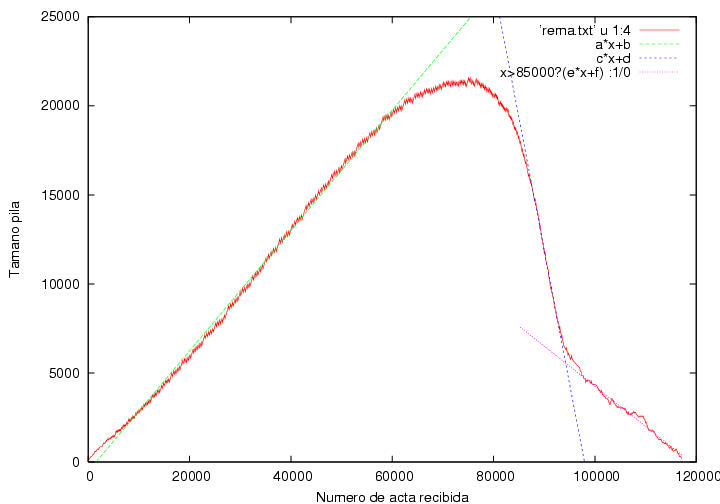
Indice
La figura 23.11 muestra el tamaño de la pila de
actas por procesar como función del tiempo (medido en horas a partir
de las 00:00 del 2/vii/06). La pila alcanza su altura máxima a
la media noche y pasadas las dos y media de la mañana del día 3/vii/06 ya
ha baja a menos de 5,000, donde se ve un cambio de pendiente en la
figura 23.10.
Figura 23.11
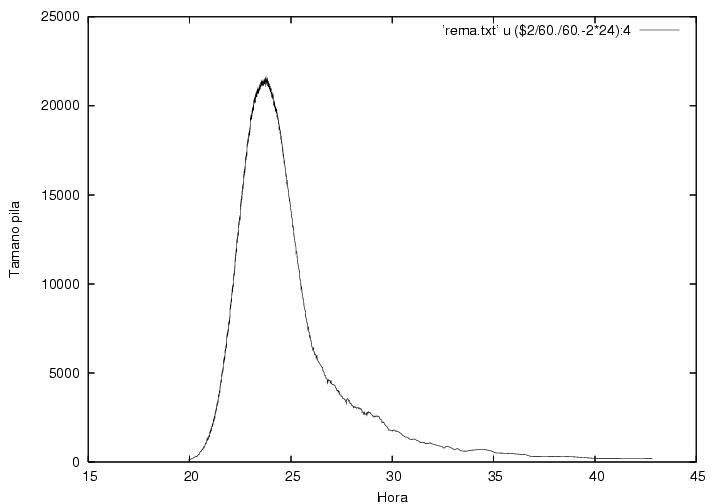
Indice
La figura 23.12 muestra el tiempo transcurrido
desde que un acta es recibida en algún CEDAT hasta que es registrada
en el sistema de cómputo como función del tiempo de recepción. Cada
punto corresponde a un acta
individual. Se observa que los retardos típicos van de unos cuantos
minutos hasta dos horas y media en los momentos de mayor afluencia de
actas, pero que hay retardos anormalmente largos que llegan incluso a
más de veinte horas. Algunos de ellos pueden deberse a algunas
pruebas de validación que emplea el IFE; las actas señaladas por
dichas pruebas son recapturadas posteriormente. Se advierte que las
actas se agrupan en líneas verticales e inclinadas.
Figura 23.12
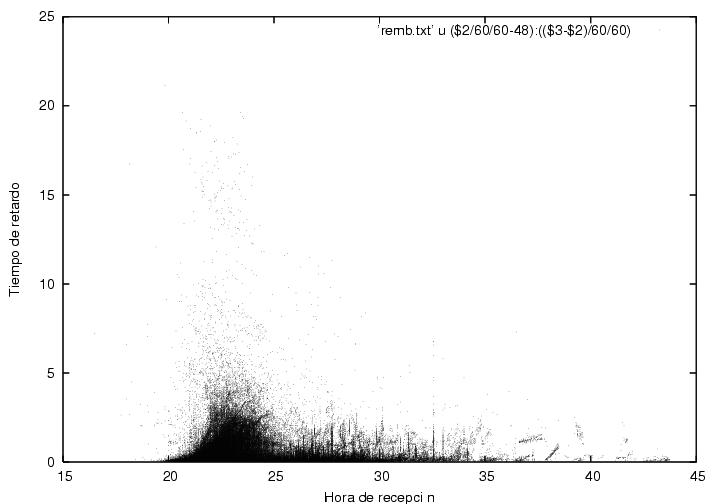
Indice
La figura 23.13 es similar a la
figura 23.12, solo que ahora se grafica el
retardo como función de la hora de captura. Cada punto corresponde a un acta
individual. Las
actas se agrupan claramente en líneas inclinadas. La intersección de
dichas líneas con el eje horizontal (retraso nulo) corresponde al
tiempo nominal de recepción. Vemos entonces que entre las actas
capturadas hacia el final de la elección se hallan algunas recibidas
desde la tarde del 2/vii/06 y hasta la madrugada del 3/vii/06.
Figura 23.13
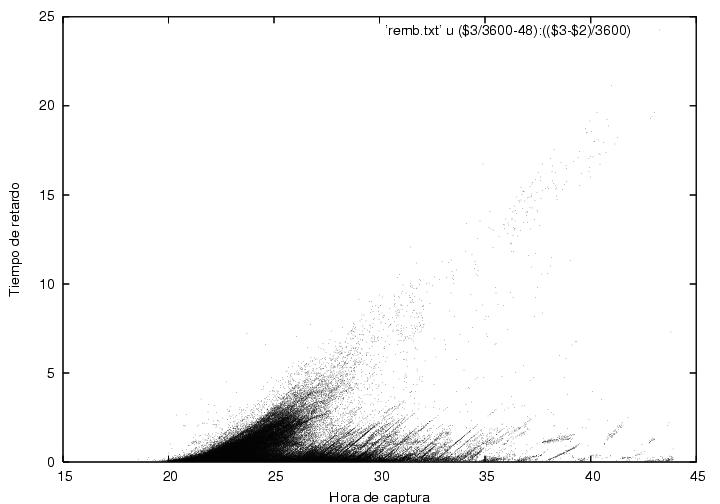
Indice
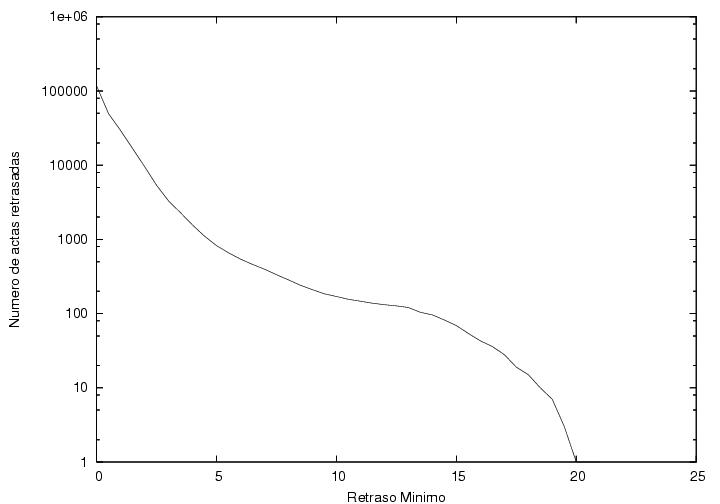
En la figura 23.14 se muestra el número de actas
cuya captura se retrasó más que cierto umbral mínimo como función del
valor del umbral. Como se observa, hay cerca de 10,000 actas con
3,500,000 votos retrasadas más de dos horas y cerca de 800
actas con 250,000 votos retrasadas más de cinco horas.
Figura 23.14
Indice
En la figura 23.15 se muestra el resultado de
la votación contabilizada únicamente sobre aquellas actas cuyo retraso
no excede de cierto umbral. Se observa que conforme movemos el umbral
entre 0 y 5 horas el porcentaje de los votos por el PAN y por la CPBT
se modifican apreciablemente (algo análogo le sucede a la APM). ¿Por
qué aparece una correlación entre el resultado de la votación y el
tiempo que se tardan dentro de los CEDATs en capturar un acta? Los
tiempos de registro se alargan ocasionalemte cuando se detecta un
error durante la primera captura de los datos y estos tienen que volver
a ser capturada, quizás después de un tiempo largo. Estos errores
reflejan en todo caso la capacidad de los capturistas contratados por
el IFE u otras decisiones tomadas en los los Centros Distritales; no
reflejan los errores que pudieron haber cometido los funcionarios
ciudadanos en cada casilla. Por lo tanto, es difícil entender la
dependencia mostrada por la figura.
Como el número total de actas cuyo retraso no excede cierto umbral
se acerca rápidamente al número total de actas conforme se extiende
dicho umbral (ver Fig. 23.14), los resultados
de la figura 23.15 llegan
rápidamente a un valor asintótico. La dependencia del resultado de la
votación en el tiempo de retraso puede apreciarse más claramente en la
figura 23.16, en la que se grafica el
resultado de la elección sobre aquellas actas retrasadas un tiempo que
excede cierto umbral mínimo como función de este umbral. Se puede
apreciar que hasta es posible revertir el resultado de la votacion si
seleccionamos adecuadamente el umbral.
Hay problema con las figuras 23.15 y 23.16, pues el número de actas disponibles para
calcular cada uno de sus puntos vería conforme transcurre el
tiempo. Así por ejemplo, la figura 23.14
muestra que hay muy pocas actas retrasadas más de 5 horas, por lo cual
el comportamiento mostrado por la mayor parte de la figura 23.16 (digamos, de 5 en adelante) podría estar
dominado por fluctuaciones espurias.
Una alternativa a las figuras 23.15 y 23.16 para observar el efecto del retraso podría
ser una gráfica mostrando el resultado de la elección vs. el retraso
para cada acta, como en la figura 23.17. Sin
embargo, como el resultado fluctúa violentamente de una a otra acta,
es difícil visualizarlo directamente, por lo cual es necesario
promediar los datos. Para obtener la figura 23.17 ordené primero los datos de acuerdo al
retraso en su captura. Después los organicé en grupos de mil actas
cada uno. Por ejemplo, el primero contiene las actas 1...1000, el
segundo contiene las actas 2...1001 y así sucesivamente. Finalmente,
en cada grupo promedié el número de votos de cada candidato y el
tiempo de retraso, obteniendo así un punto sobre la gráfica. Como el
número de actas disminuye conforme aumenta el retraso, escogí una
escala logarítmica para desplegar el tiempo de retraso. La curva
roja muestra
que la diferencia porcentual de votos entre el PAN y la CPBT tiene una
dependencia sistemática y significativa con respecto al tiempo de
retardo, la cual no se oculta por las fluctuaciones estadísticas, las
cuales son del orden de +/-2.5%. Sobre aquellas actas procesadas en menos de
5 minutos gana la CPBT, en aquellas que tardan entre 5 mins. hasta
poco más de una hora gana el PAN, entre una hora y poco menos de tres
horas gana la CPBT y arriba de tres horas vuelve a ganar el PAN. Como
en esta gráfica hay el mismo número de actas contabilizadas en cada
punto, las fluctuacines no dependen del retraso. La curva verde,
obtenida mediante el mismo proceso pero promediando sobre un
número mayor (5,000) de casillas y por lo tanto con fluctuaciones
mucho menores, confirma las tendencias anteriores y
demuestra que no son meras fluctuaciones estadísticas. También muestra
estructuras notables, tales y como un pico con una altura de 3.5%
correspondiente a retrasos entre 50 y 70 minutos. Más notable aún es
la subida correspondiente a retrasos de cuatro
horas (¿Cuánto tiempo habrán esperado los funcionarios de casilla en
los CEDATs a que se capturaran los datos de sus actas? ¿Cuantos
funcionarios de casilla habrán abandonado los CEDATs sin confirmar los
datos capturados?).
Queda entonces en el aire la pregunta: ¿por qué el resultado
de la votación promediado sobre un conjunto de actas depende del
tiempo que se hubiesen tardado los capturistas del IFE, distribuidos
en los 300 Centros Distritales, en registrar dichas actas después de
recibidas, lo cual depende de circunstancias totalmente ajenas a los
electores y a los funcionarios de casilla?
Figura 23.15
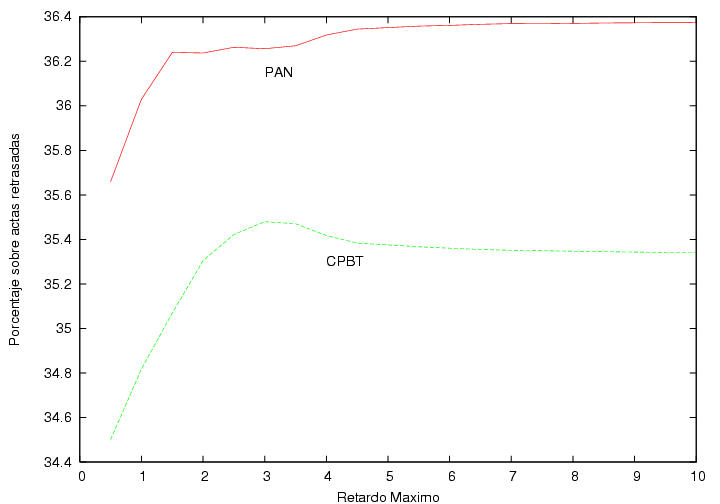
Figura 23.16
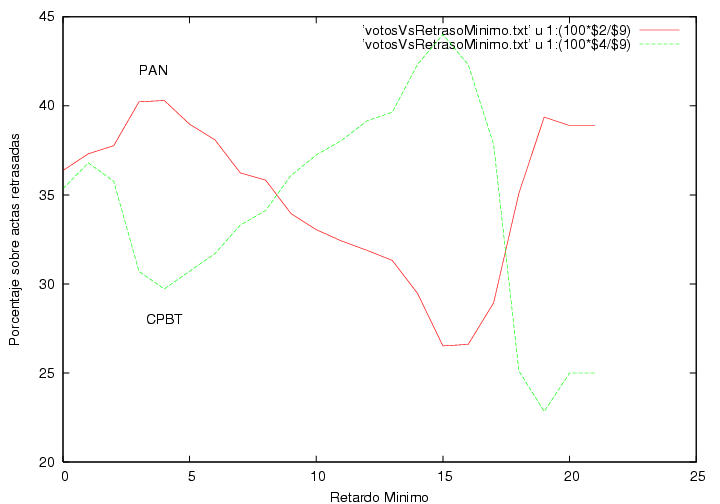
Figura 23.17
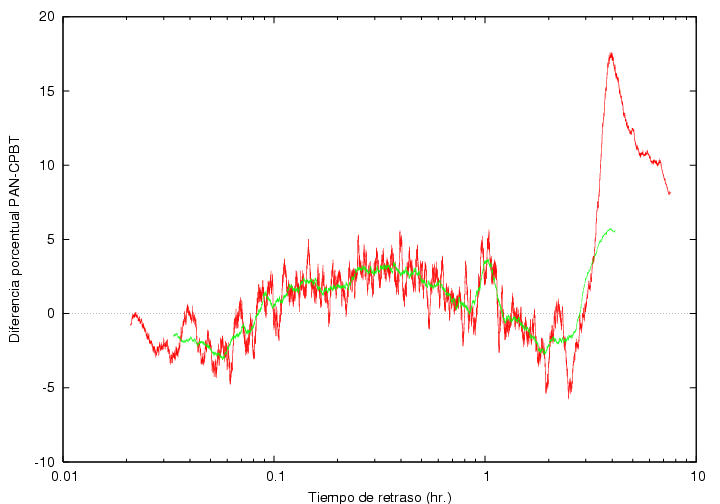
Indice
Una forma de distinguir números enteros grandes obtenidos de un
proceso estocástico de números inventados tiene que ver con su
estadística. A continuación muestro un histograma del número de
veces que apareció cada digito entre el 0 y el 9 en la posición de las
unidades, i.e., no de las decenas, centenas, etc. La probabilidad de
obtener cierto dígito en la última posición debe ser la misma que para
cualquier otro dígito. Las figuras 24, 25 y 26 muestran que cada
dígito apareció más o menos el mismo número de veces para cada
candidato, alrededor de 11700 veces,
aunque la dispersión de los datos
para AMLO parece ser la mitad que para los otros dos. Curioso.
Figura 24
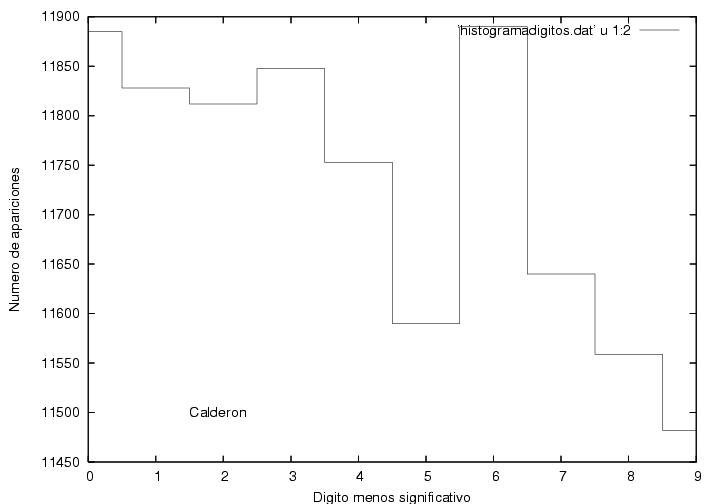
Datos.
Figura 25
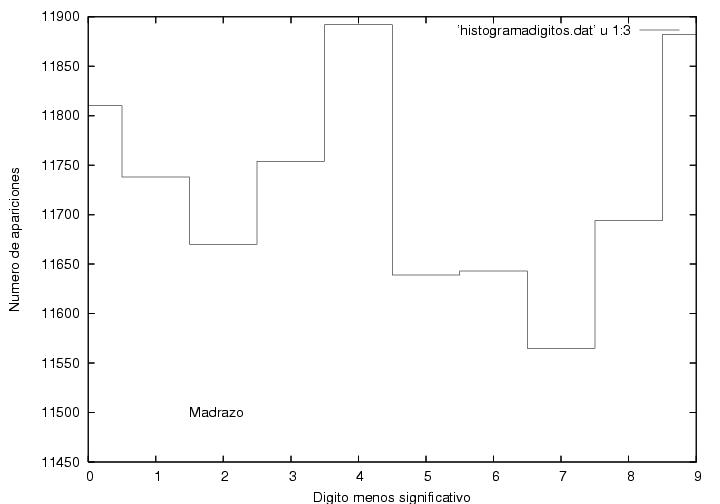
Datos.
Figura 26
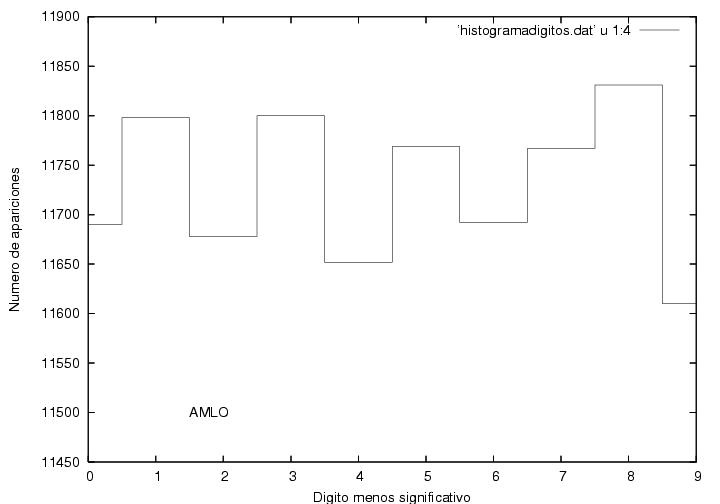
Datos.
Indice
Intenté descartar el que el resultado previo fuese obra de la
casualidad e intenté hacer un programa que evaluara las dispersiones
en diversos rangos, etc., pero estoy muy cansado y no me salió. Así
que me puse a contemplar mi archivo de resultados y me encontré los
datos de Campa y de Mercado. Me ganó la curiosidad...
Figura A25
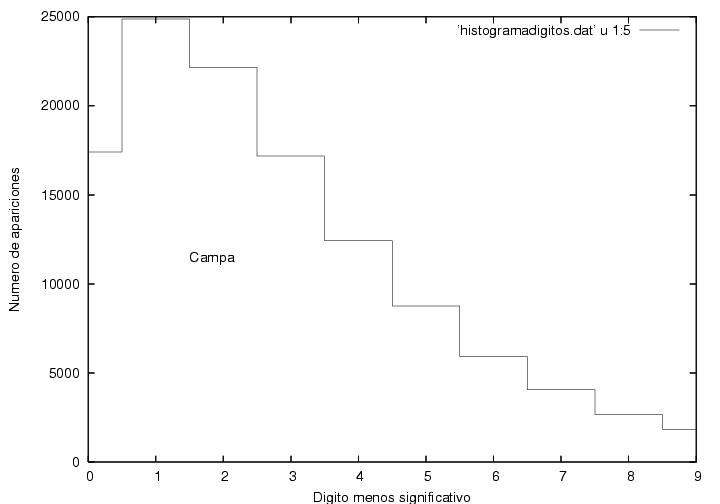
Datos.
Figura A26
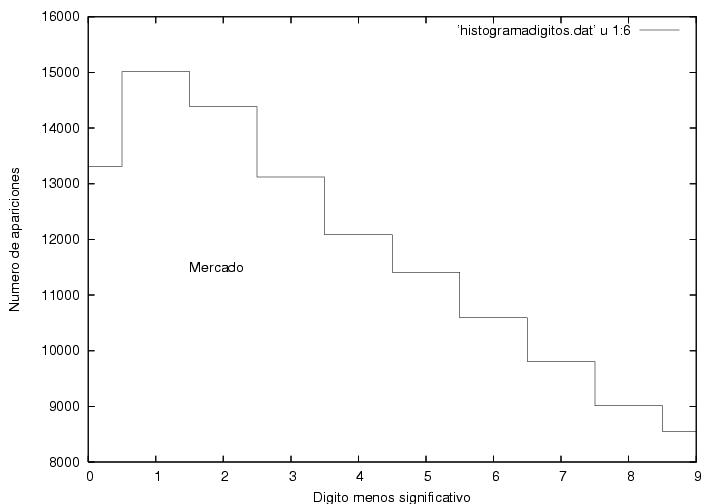
Datos.
Noten la escala. Noten la estructura... pero no, no significa nada,
pues Campa y Mercado obtuvieron votaciones de un dígito, por lo cual
la distribución no tiene por qué ser azarosa.
En todo caso, los
valores de la variancia de las gráficas
previas son:
Calderón 141.00
Madrazo 102.15
AMLO 69.88
Campa 7910.26
Mercado 2122.94
Como referencia, hay cerca de N=117000 votos, la probabilidad de obtener
un dígito cualquiera es p=0.1, el valor promedio del número de veces
que aparece un dígito es p*N=11700 y la raiz cuadrada de
p*(1-p)*N=102.61. ¿Es esta una buena estimación de la variancia para
estos datos? ¡El único dato típico es el de Madrazo! Las enormes
variancias de Campa y Mercado son por su extremadamente baja captación
de votos. ¿Son razonables las variancias de Calderón (40% más que la
esperada) y de AMLO (70% de la esperada)? Este análisis debe repetirse
sobre muchos subconjuntos antes de que pueda ser conclusivo.
Indice
Existe otra prueba estadística sobre la probabilidad de aparición de
dígitos en colecciones de números. Esta es la prueba de Benford. Yo no
sabía de ella hasta hoy (11/vii/06) en que leí el artículo que escribió al respecto
R. Mansilla. Resulta que desde 1881 se conoce la ley de probabilidad,
conocida ahora como Ley de Benford, que describe el histograma de
aparición del dígito más significativo de una colección de números
aleatorios. Está demostrado que esta distribución se debe cumplir en
una gran variedad de bases de datos donde hay algún elemento de azar
tan diversas como áreas de ríos, pesos atómicos de los elementos
químicos, números de las casa en una ciudad, etc. La aplicación actual
más importante de la ley de Benford es la detección de fraudes
fiscales.
¿Qué es la ley de Benford (LB)? El dígito
más significativo de una colección grande de números se distribuye de
la siguiente manera: la probabilidad de hallar el digito D es
log(1+1/d)/log(10). Por ejemplo, el dígito D=1 debería aparecer en la
primera posición con una probabilidad de log(2)/log(10)=0.301, i.e.,
aproximádamente el 30% de las veces, mientras que el dígito D=6
debería aparecer con la probabilidad log(1+1/6)/log(10)=0.067, i.e.,
abajo de 7% de las veces. En la figura 27 muestro
la probabilidad de obtener cada uno de los dígitos 1..9 en la posición
más significativa, expresada como un porcentaje. Como referencia,
marqué también el valor predicho por la LB (línea
continua). Curiosamente ¡ninguno de los resultados del PREP es
consistente con la LB.
- Los datos de Calderón (+) parten de
45% en lugar de 30% y bajan rápidamente mostrando un mínimo para el
dígito 4, subiendo posteriormente hasta aproximarse a la ley de
Benford para digitos mayores.
- Los datos de Madrazo (X) empiezan por debajo de la ley de Benford,
tienen un mínimo en 2 y un máximo en 5, y sólo se aproximan a la ley
de Benford en 9.
- Los datos de AMLO (asteriscos) empiezan arriba de la ley de
Benford, tienen un mínimo en 3 y siguen la ley de Benford
aproximadamente a partir del 5-6.
- Los datos de Campa empiezan poco abajo de la LB y terminan un poco
arriba. Decaen de manera monótona. Sin embargo su decaimiento inicial
es muy lento comparado con el predicho por la LB.
- El comportamiento de Patricia Mercado sigue muy de cerca al de
Calderón.
- Los no registrados empiezan sobre la LB pero siguen muy de cerca
los resultados de Campa.
- Los votos nulos siguen cualitativamente el comportamiento de AMLO,
aunque con variaciones más pequeñas.
¿Será posible que las violaciones a la LB se deban a que los números
de nuestra muestra son muy chicos, todos ellos de 3 o menos dígitos?
¿Habrá efectos de tamaño finito? De ser esta la explicación de las
discrepancias, yo esperaría que candidatos con números totales de
votos similares siguieran curvas similares. Este no es el
caso. Los datos de AMLO y los de Calderón difieren notablemente,
a pesar de haber obtenido votaciones muy cercanas. Los datos de
Calderón y de Mercado se parecen, a pesar de haber obtenido votacioes
muy distintas.
De manera que ningún candidato cumple con la ley de Benford. Sin
embargo, si vuelvo a hacer el cálculo sin distinguir los datos
correspondientes a un candidato de los de los otros candidatos,
es decir, si hago el histograma correspondiente a todos los votos
recibidos por todos los candidatos en todas las casillas, incluyendo
candidatos no registrados y votos nulos, ¡el resultado se vuelve
consistente con la ley de Benford! (figura
28) Esta casualidad... parece
milagrosa, aunque... ¡hay otra explicación! (sugerida por Hernán
Larralde) Es posible que la ley de
Benford no se aplique a nuestras distribuciones, las cuales no son
invariantes de escala. Como las distribuciones tienen un máximo (por
ejemplo, 53 en el caso de Madrazo), es factible que el dígito más
significativo del mismo (5 en el caso de Madrazo) aparezca con una
frecuencia mayor que el dígito anterior o que el posterior (4 o 6 para
Madrazo). Al agregar todos los datos en un mismo histograma, sumamos
candidatos con distintos números esperados de votos y creamos una
distribución más parecida a una distribución invariante de escala, con
lo cual mejoramos el ajuste a la ley de Benford.
Ayer (26/VII/06) me enteré de que, aunque no tenemos por qué esperar
que la ley de Benford mencionada arriba se cumpla para el dígito más
significativo de los datos de las elecciones, hay una generalización
de la ley de Benford que incluye a los dígitos subsiguientes (segundo,
tercero,...) y que su violación es una indicación seria de anomalías y
posibles fraudes. En una nota
electrónica, Luis Horacio Gutierrez me ha facilitado un artículo sobre la teoría matemática que
sustenta a la Ley de Benford y a su amplia aplicabilidad y otro
artículo escrito por el profesor
W. R. Mebane de la U. de Cornell en que aplica dicha ley para estudiar
sistemáticamente los resultados de nuestra reciente elección y la
elección de Florida en 2004. Finalmente, aquí hay una presentación con un estudio
detallado de nuestra eleeción empleando la ley de Benford.
El IFE ha preparado una respuesta
a algunos de los puntos mencionados arriba, en otras partes de esta
página y en una nota enviada al
Dr. Woldenberg.
En particular, en la página 18 se refieren a la ley de
Benford.
El número máximo de boletas que tenía cada casilla era de 750 más 10,
es decir, por diseño se disminuye la probabilidad de que el primer
dígito de cada cantidad de votos sea 7,8 ó 9. El universo de números
para el primer dígito no incluye el 7,8 ó 9 como se incluye en
cualquie otro tipo de experimento...
Aquí hay un error, pues el primer dígito no se refiere necesariamente
a las centenas. SI en alguna casilla se recibieran 75, 83 o 97 votos,
el primer dígito sería 7, 8 o 9 respectivamente. La posibilidad de que
el primer dígito pueda ocupar la posición de las unidades o decenas o
centenas sí está contemplada en la ley de Benford. Pero en todo caso,
como afirmo arriba, la ley de Benford no es aplicable al primer dígito
por lo angostas de las distribuciones de votos.
En cuanto a la ley de Benford del segundo dígito y el artículo escrito por el profesor Mebane, la
respuesta menciona que
La recomendación del profesor Mebane consiste en la realización de
estudios exhaustivos antes de caer en la tentación de hacer un recunto
de los votos.
Me parece que dicha interpretación de la recomendación del Dr. Mebane
es demasiado libre. El Dr. Mebane afirma textualmente en su artículo
The 2BL test results for secciones certainly suggest there are
problems with the 2006 presidential vote counts in many Mexican
states, although probably not in most of them. More refined analysis is
needed to reach sharper conclusions, but the general impression is
that more intensive investigation of the election results is in
order. That might include doing a manual recount of many --perhaps
all-- of the individual ballots. A cost efficient method may be to begin
by recounting a random sample of the ballots --all the ballots in a
sample of secciones-- where the probability that a seccion is selected
for recounting is greater in places where the 2BL test results are
worse. For such an exercise it may be reasonable to conduct 2BL tests
for secciones collected into sets that correspond to the legislative
districts they are part of, with sampling for purposes of initial
recounting done at the level of districts. Perhaps a two-stage
sampling plan could be used, with districts selected at the rst stage
(weighted by the 2BL test results) and secciones within each district
selected at the second stage. If such an initial sampling did identify
problems with the vote tabulations, then the case for a comprehensive
manual recount would become extremely strong.
Como se puede leer, el Dr. Mebane no considera que su estudio sea
conclusivo, pero sí es sugestivo de problemas. El Dr. Mebane
recomienda el recuento manual de muchos o incluso de todos las
votos. Por cuestiones de economía sugiere una solución intermedia que
consistiría en recontar una muestra elegida con criterios
precisos. Afirma también que, de acuerdo a los resultados de dicho
recuento parcial, podría concluirse que el recuento total es
necesario. La impresión que deja la respuesta del IFE de que el
recuento es una tentación que hay que evitar es errónea. Por
otro lado, los tiempos legales no permitirían un recuento parcial de
acuerdo al criterio del Dr. Mebane seguido por un recuento total de
ser necesario, por lo cual el recuento total ahora parece ser la única
forma de obtener la requerida certeza.
Figura 27
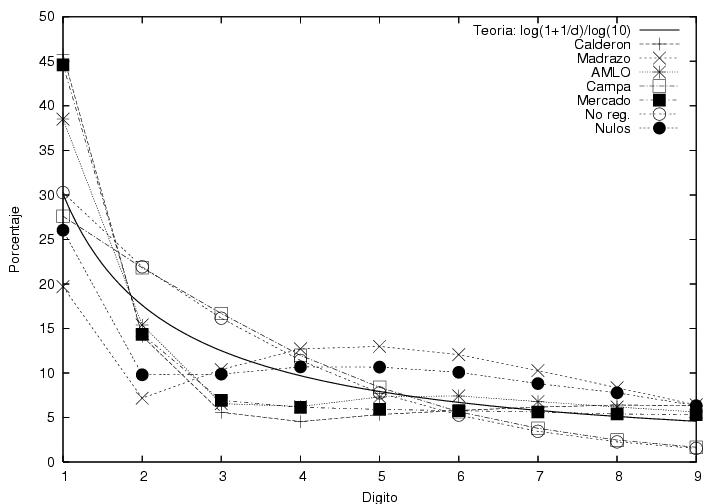
Datos.
Figura 28
Datos.
Indice
Cómputos Distritales
Empecé (14/vii/06) a procesar la base de
datos del Conteo Distrital.
- El número de registros
correspondiente a la elección
presidencial
es de 130,788. Este número sobrepasa en 300 al número de actas que
reportaba el PREP, por ejemplo aquí. ¿De donde salieron las actas
adicionales? Tengo entendido que el PREP ya incluía el voto en el
extranjero. (Hoy (15/vii/06) me aclararon que 130,788 es el número
correcto y 130,488 no lo era).
- El número de registros en las bases de datos de Diputados y de Senadores es de 131310. Hay 522
registros de más en el conteo de diputados y
senadores que en el presidencial, el cual supuestamente coincide
(15/vii/06) con el número total de casillas, incluyendo las votaciones
en el extranjero. ¿Por qué?
- A diferencia de los datos del PREP, aquí no hay registros con
asteriscos...
- pero hay campos en blanco. En la base para presidente hay 311
líneas con campos en blanco. Aquí está la lista de las líneas
incompletas. En cambio, solamente hay 11 líneas incompletas en la base
para diputados (aquí) y 11 líneas incompletas en la
base para senador (aquí). Las 11
líneas parecen venir de las mismas casillas. ¿Por qué aparecen
omisiones siendo que el Conteo es un proceso de revisión? ¿Por qué hay
más omisiones correspondientes a la elección presidencial, siendo que
ésta tiene 522 registros de menos?
- Nota: Las respuestas a las preguntas anteriores se
hallan en un mensaje que me
envió Rici Lake.
- Eliminando las líneas en blanco, no hay inconsistencias entre el
número total de votos válidos (NO_VOTOS_VALIDOS) y la suma de los
votos obtenidos por todos los partidos y por los candidatos no
registrados (NO_VOTOS_CAN_NREG, PAN, APM, PBT, NA, ASDC).
- Substituyendo todos los blancos por ceros, sigue habiendo
consistencia.
- Tampoco hallé inconsistencias con el número total de votos, el cual
es la suma del número de votos válidos más el número de votos nulos
(TOTAL_VOTOS=NO_VOTOS_VALIDOS+NO_VOTOS_NULOS) ni eliminando las líneas
con blancos ni sustituyendo los blancos por ceros. Por lo tanto voy a
substituir blancos por ceros en mis bases procesadas.
- Hay 20 actas (aquí) en las que
el total de votos por presidente fue nulo: no hubo votos por ningún
partido, no hubo votos por ningún candidato independiente y no hubo
ningún voto anulado. Similarmente, hubo 50 actas (aquí) sin votos en la elección de
diputados y 47 (aquí) en la
elección para senador. ¿Qué pasó en las casillas
correspondientes?.
- Las bases de datos del Conteo Distrital no traen
información sobre el número de boletas depositadas en las urnas, de
manera que la enorme inconsistencia entre el número de votos y el
número de boletas que había detectado en el PREP (aquí) no fue aclarada.
- Hay evidencia en el formato de los archivos de que las bases de
datos del conteo distrital a las que tuve acceso fueron preparadas en
alguna computadora con el sistema operativo Windows, el cual es
reconocido como poco robusto e inseguro, características que
seguramente habrán sufrido en carne propia la mayoría de los lectores...
- Los resultados de la base de datos del conteo son
| Calderón | Madrazo | AMLO | Votos válidos |
| Votos | 15,000,284 | 9,301,441 | 14,756,350 | 41,791,322 |
| Porcentaje | 35.89%+ | 22.26%- | 35.31%- | | |
Estos coinciden con los reportados
por el IFE.
- Comparando la base de datos del
Conteo Distrital para la elección de presidente con la
base de datos correspondiente al PREP obtuve
que en el conteo hay 13,501 actas que no se habían contabilizado en el
PREP. Aquí está la sección
correspondiente de la base de datos.
- Los resultados correspondientes a estas casillas son:
| Caledrón | Madrazo | AMLO | Votos válidos |
| Votos | 990,233 | 985,027 | 1,135,971 | 3,191,867 |
| Porcentaje | 31.02%+ | 30.86%+ | 35.59%- | | |
Entiendo que las actas mencionadas arriba (aproximadamente el 10% del
total) no formaron parte del PREP por contener errores de algún tipo o
por haberse guardado dentro del paquete electoral donde eran
inaccesibles. Yo hubiera esperado que la probabilidad de cometer este
tipo de errores fuera uniforme sobre toda la población del país. De
hecho, la figura
40 muestra que no hay correlación aparente entre la
preferencia electoral y la probabilidad de haber cometido uno de estos
errores, i.e., estas actas corresponden a casillas que cubren más o
menos uniformemente todos los posibiles resultados, desde un triunfo
aplastante de Madrazo hasta uno de Calderón o uno de AMLO. La tabla de
arriba muestra que en dicha muestra AMLO ganó por 4.5% y Calderón
obtuvo un resultado muy cercano a Madrazo, como se podía haber
previsto de las últimas encuestas previas a la elección. Es curioso
que el procentaje obtenido por AMLO globalmente es casi igual al
obtenido en
esta muestra, mientras que los porcentajes obtenidos por Calderón
bajan y los obtenidos por Madrazo suben sustancialmente; como si
hubiera habido una transferencia de votos desde Madrazo hacia
Calderón en las actas que sí llegaron al PREP. Un análisis más detallado elaborado por
Gerardo Horvilleur, en el cual se eliminan además las actas en las que
pudo haber un error involucrando a los candidatos principales, arroja
como resultado 28.54% para el PAN, 34.58% para el PRD y 31.72% para el
PRI, i.e., en esas actas, que deberían haber sido un muestreo amplio y
no sesgado de la votación nacional, ¡Calderón queda en tercer
lugar con 2.18%, por debajo de Madrazo y 6.04% por debajo de AMLO. El
estudio referido hace también un análisis estado por estado y discute
en cuáles estados esta muestra es un buen predictor y en cuales no. El
que no sea un predictor a nivel nacional es un misterio.
- Todas las actas reportadas en el PREP aparecen en el Conteo
Distrital, como debía ser.
- Aquí hay un archivo donde alternan
renglones correspondientes a las casillas reportadas tanto por el
Conteo Distrital como por el PREP.
- De las actas reportadas tanto en el PREP como en el Conteo
Distrital, hay 4,151 en las que el número de votantes no coincide. La
lista de dichas inconsistencias puede hallarse aquí (el formato es una línea
del CD, una del PREP, los números que discrepan y una línea en blanco).
- El número total de votos reportado en el PREP supera al número
total de votos reportado en el Conteo en 7,404. Esto es sin contar las
más de 13,000 actas que sí tiene el conteo pero que no tiene el PREP.
- Estos datos parecen diferir de la información dada a conocer a los
medios y publicada el 20/vii/06 (por ejemplo aquí),
en que el IFE
reconoce que se abrieron 2,873 paquetes electorales (no 4,151) y en el
recuento se obtuvo una disminución del número total de votos por
64,026 (no 7,404).
- ¿Por qué difiere mi cuenta de la del IFE? (Agradecería si alguien
descubre un error en mis datos o programas, los cuales coloqué aquí).
- Los puntos anteriores son importantes. En la sección
sobre el PREP señalé que hay al menos 220,000 votos por
arriba del número de boletas. No puedo averiguar si dicha
discrepancia ha sido eliminada pues las bases de datos del IFE sobre
el Conteo Distrital eliminaron el campo de BOLETAS_DEPOSITADAS
(además de cambiar el formato de las bases, lo cual me ha mantenido
entretenido). La nota
podría haber implicado que se empiezan a aclarar las discrepancias, i.e.,
se entendieron 60,000 de los 200,000 votos en exceso. Por ello es
importante hacer cuadrar dicho número con los que reporto arriba.
- Si sólo se abrieron 2,873 paquetes, ¿por qué hallé discrepancias
entre el PREP y el Conteo en 4,151 registros? Los 1,278 errores
faltantes ¿habrán sido corregidos sin tener que recontar?
- Es interesante desglozar el número 7,404 mencionado arriba. Hay
2,376 casillas en las que el número de votos totales registrados en el
Conteo es mayor al número de votos registrados en el PREP. La
diferencia de votos adicionales acumulados en esas casillas es de
35,073. Sin embargo, hay 1,775 en las que el PREP reporta más votos
que el contéo. El número de votos acumulado en ellas es 42,477. La
diferencia de estos dos números corresponde a los 7,404 votos que le
sobran al PREP.
- Comparando únicamente las actas reportadas tanto en el PREP como en el
Conteo, el PAN obtuvo 1,853 votos adicionales en el conteo (además de
los 985,027 votos que tuvo en las 13,501 registros que no están en el
PREP). Similarmente, la Alianza por México perdió 1,112 votos y la
Coalición por el Bien de Todos ganó 6,963. Juntando estos números obtengo
7,704, casi igual a los 7,404 votos esperados, pero con el signo
contrario; entre los tres partidos aumentaron su número de votos
mientras que el total de votos disminuyó al comparar las actas del
PREP con los registros corresondientes del Conteo.
- La diferencia entre 7,704 y -7,404 debe encontrarse entre los
partidos pequeños. Así, Nueva Alianza perdió 2,334, Alternativa Social
Democrata perdió 670, los candidatos no registrados aumentaron en 627
y los votos anulados disminuyeron en 12,731.
- Los cambios sufridos por los principales contendientes durante el
conteo están ilustrados en la siguiente tabla. En ella muestro para
cada uno el número de casillas en que cambió, mejoró y empeoró su
votación y el número de votos que cambió, ganó y perdió en el conteo
respectivamente. En esta tabla incluí registros incompletos (con
asteriscos cambiados por ceros) y con inconsistencias (total de votos
distinto a número de boletas depositadas).
| Diferentes | Mejoró | Empeoró |
| PAN casillas | 1243 | 699 | 544 |
| PAN votos | 1853 | 9194 | -7341 |
| APM casillas | 1278 | 710 | 568 |
| APM votos | -1112 | 7279 | -8391 |
| PBT casillas | 1458 | 919 | 539 |
| PBT votos | 6963 | 14063 | -7100 |
Me parecen notables las diferencias de comportamiento de los números
de arriba. El número de casillas donde FC y RM mejoraron es alrededor
de 25% mayor que el número de casillas donde perdieron, y el número de
votos que ganaron y perdieron son similares, mientras que el número de
casillas donde AMLO mejoró durante el Conteo es mayor en 70% al
número donde perdió, y el número de votos que ganó es aproximadamente
el doble de los que perdió. Si los errores que
fueron corregidos durante el recuento hubieran sido producidos por
descuido, yo hubiera esperado aproximadamente el mismo número de
casillas a favor y en contra de cualquier candidato, con fluctuaciones
descritas por una distribución binomial. ¿Podrán explicarse los números
de arriba simplemente por el grado de determinación e insistencia de
uno u otro partido en corregir los errores que le perjudicaban durante
el conteo?
- La afirmación anterior se puede cuantificar. Por ejemplo, la
probabilidad de que en 1458 cambios que tuvo la Coalición PBT hubiera
habido más de 850 cambio a su favor y por lo tanto menos de 608 votos
en contra es, de acuerdo a la distribución binomial, de una parte
1010, i.e., una parte en diez mil millones. La probabilidad de
tener más de 900 cambios a favor y menos de 558 en contra es tantas
veces menor que mi computadora no la puede evaluar, pero es menor que
1017, i.e., menor a una parte en cien mil millones de millones
i.e., para todos motivos prácticos, es imposible. ¡La desviación
entre 919 y la media esperada es de casi de diez desviaciones estandard!
Es decir, una situación como la mostrada en el penúltimo renglón de la
tabla mostrada arriba no podía suceder si los errores que se
corrigieron durante el conteo fueran aleatorios y fuera igualmente
probable ganar o perder en cada cambio. ¿Por qué los errores fueron
mayoritariamente en contra de AMLO, de forma que al corregirlos mejoró
su votación de manera tan improbable?
- La situación descrita arriba corresponde a aventar 1500 volados y
obtener 900 águilas. Inténtelo y verá que eso jamás sucede, aunque si
sólo tira 15 volados obtendrá 9 águilas una de cada 5 veces que juegue.
- Los cambios registrados por los otros candidatos también son poco
probables, aunque no tan dramáticamente. Calderón excede al promedio
esperado en 4.4 σ's y Madrazo excede el valor esperado en 4.0 σ's
Por ejemplo, la probabilidad
de que Madrazo mejorara en más de 650 de 1278 casillas es de 27%
y la probabilidad de que Calderón mejorara en más
de 650 de 1243 cambios es de 5%. En los tres casos puse el umbral
alrededor de 50 cambios por debajo del número obtenido. Poniéndolo 20
cambios por debajo, la probabilidad de que Madrazo hubiera
mejorado en más de 690 cambios es de 2 partes en 1,000 mientras la
probabilidad de que Calderón hubiera obtenido más de 680 cambios
favorables sería del 0.04%.
- Luis Gerardo Magaña realizó un estudio cuidadoso sobre los cambios
en aquellas casillas donde se realizó un recuento.
- El IFE ha preparado una respuesta
a algunos de los puntos mencionados arriba, en otras partes de esta
página y en una nota enviada al
Dr. Woldenberg.
- En dicha respuesta se menciona que hubo 11,184 casillas que no
llegaron al PREP por inconsistencias en su llenado, y sus resultados
están disponibles en una
base
de inconsistencias.
- A pesar de que se afirma que
Las actas que presentan inconsistencias no se
relacionan directamente con la votación a favor de la Coalición por el
Bien de Todos
y que
No hay posibilidad de que exista una correlación inducida entre las
actas con inconsistencias y el voto po la Coalición por el Bien de
Todos (CBT), ya que las actas que no se publicaron provinieron de todas
las entidades federativas,
se menciona que en estas actas hubo 743,795 votos para el PAN (28.8%), 809,003
para la APM (31.34%) y 888,971 para la coalición PBT (34.43%) de un
total de 2,581,226 votos, lo cual le da una ventaja a PBT de 3.09%
sobre la APM y de 5.62% sobre el PAN. Estos datos del IFE confirman
que el resultado de la elección sobre este subconjunto de actas es muy
distinto a los resultados de la elección global. ¿Por qué?
- Dicha respuesta menciona que la correlación de Pearson entre el
porcentaje de actas inconsistentes y el porcentaje obtenido por el PBT
en dichas actas es muy bajo, pero eso no implica que no exista
correlación entre la existencia de inconsistencias y la preferencia
electoral, i.e.,el resultado de la votación es muy distinto en
las actas con inconsistencias con respecto al resultado global.
- En la página 7 de su respuesta, se explica que esta preferencia
por la PBT sobre el PRI y sobre el PAN se debe a que las 11,184
casillas que no llegaron al PREP por inconsistencias son en su mayoría
no-urbanas (7,338, 64.6%) y minoritariamente urbanas (3,846, 34.4%)
mientras que globalmente 40,202 casillas (30.81%) son no-urbanas y
90,286 (69.19%) son urbanas.
- En la página 8 de la respuesta
del IFE se menciona que la tabla del punto 26 arriba es
incorrecta, lo cual se muestra a través de su inconsistencia con su
tabla 6. Sin embargo, la tabla 6 fue elaborada con una base de datos
distinta a la empleada por mí. Yo empleé la base de datos que el
PREP hizo pública vía
http://prep2006.grc.com.mx/extraccion-servlets/presidente.txt
y
http://prep.eluniversal.com.mx/extraccion-servlets/presidente.txt
y la cargué el día 7 de julio pasado. Confirmé que las votaciones
totales obtenidas de mi base de datos son consistentes con las
obtenidas de las bases de datos http://www.ife.org.mx/documentos/proceso_2005-2006/prep2006/bd_prep2006/PREP2006-Presidente.zip
a las que se accede actualmente (14/viii/07) a través del IFE
siguiendo la ruta
http://www.ife.org.mx/->PREP
2006, Consulta de Resultados->Descarga de la Base de Datos del PREP
2006->PREP2006-Presidente.zip. En ellas obtengo 14,008,198 votos para
el PAN, 8,317,526 votos para la APM y 13,613,416 para la coalición
PBT. Estos números son significativamente menores a los que reporta la
tabla 6 de la respuesta. Probablemente el IFE empleó alguna base de
datos que incluía el voto en el extranjero y/o las 11K casillas
inicialmente fuera del PREP para elaborar su tabla, pero su uso de una
base de datos distinta no invalida los cambios que yo detecté entre
dos bases de datos oficiales del PREP y del CD.
Indice
La figura 29 muestra el histograma de votos
obtenidos por Calderón, Madrazo y AMLO. El eje horizontal es el
número de votos y el eje vertical el número de veces que se obtuvo ese
número de votos de acuerdo al conteo distrital. La gráfica es
esencialmente igual a la figura 21.2, con las
mismas peculiaridades. Los datos parecen tener menos dispersión que
los datos del PREP. Curiosamente, aunque Madrazo tiene un número mayor
de actas en su máximo, la dispersión absoluta en sus datos es menor que para
AMLO y que Calderón. Además la curva de Calderón parece bifurcarse
cerca del máximo en dos curvas con poca dispersión en lugar de verse
como una curva con mucha dispersión (esto, desde luego, es una
apreciación subjetiva). La anomalía en la curva de Calderón muestra
ahora un mínimo muy claro en 26 votos 420 actas y una subida
sistemática hasta un máximo en 6 votos con 560 casillas. Esta
estructura estaba oculta en la dispersión de la figura 21.2.
Figura 29
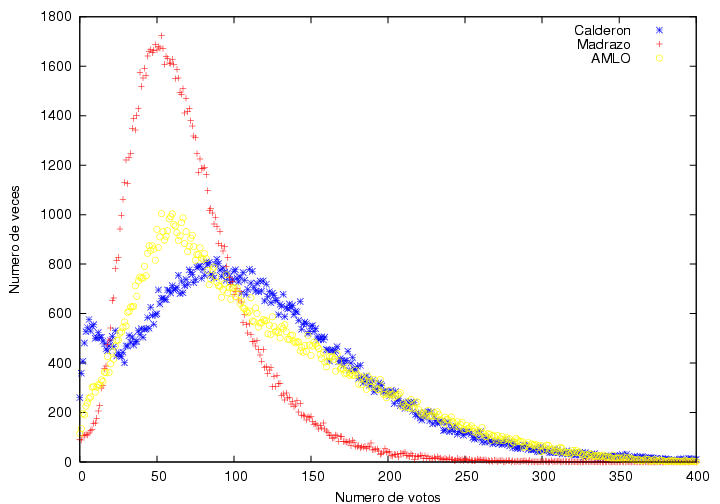
Datos.
Indice
Después de hacer una serie de ajustes a las curvas que muestra la
fig. 29, Jaime Ruiz sugirió que quizás lo que
sucede es que México no es uno sino dos paises. Eso sería consistente
con el
mapa bicolor que publica el IFE (página 6). Repetí entonces el
histograma de la fig. 29, pero separándolo en dos
contribuciones: las de los estados del norte fig. 29.1 y la de los estados del sur fig. 29.2. La gráfica de cada región por separado
se ve
más acorde con el sentido común que la fig. 29. En el norte, la votación por AMLO fue
similar a la de Madrazo, mientras que la de Calderón tuvo una
distribución mucho más ancha. En el sur, la distribución de AMLO fue
muy ancha y la de Calderón no se angostó tanto como la de AMLO en el
norte, aunque permanece el extraño pico cercano a cero votos. Mi
definición de norte fue Aguascalientes, Baja California, Baja
California Sur, Coahuila, Colima, Chihuahua, Durango, Guanajuato,
Hidalgo, Jalisco, Nayarit, Nuevo León, Querétaro, San Luis, Sinaloa,
Sonora, Tamaulipas y Zacatecas. Mi definición de sur fue
Campeche, Chiapas, Distrito Federal, Guerrero, México, Michoacán,
Morelos, Oaxaca, Puebla, Quintana Roo, Tabasco, Tlaxcala, Veracruz,
Yucatán. Seguramente habrá una manera más sensata de dividir al país
en regiones (se aceptan sugerencias). Intenté hacer el mismo tipo de
gráficas estado por estado, pero hay tan pocos datos por estado que en
un primer vistazo no aprecié ninguna estructura.
Figura 29.1
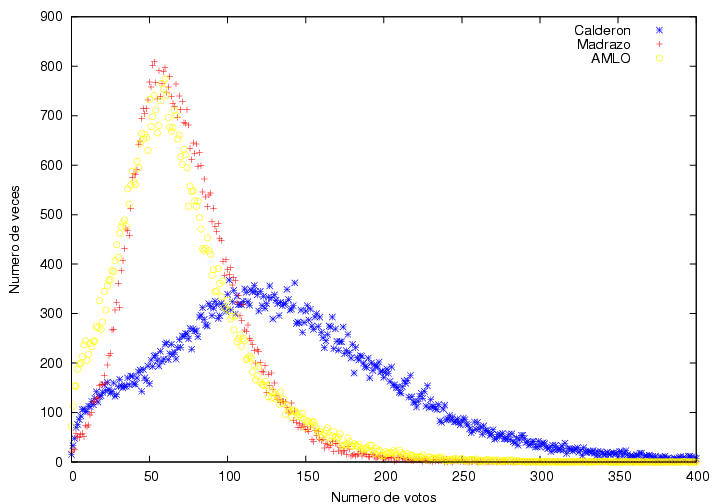
Datos.
Figura 29.2
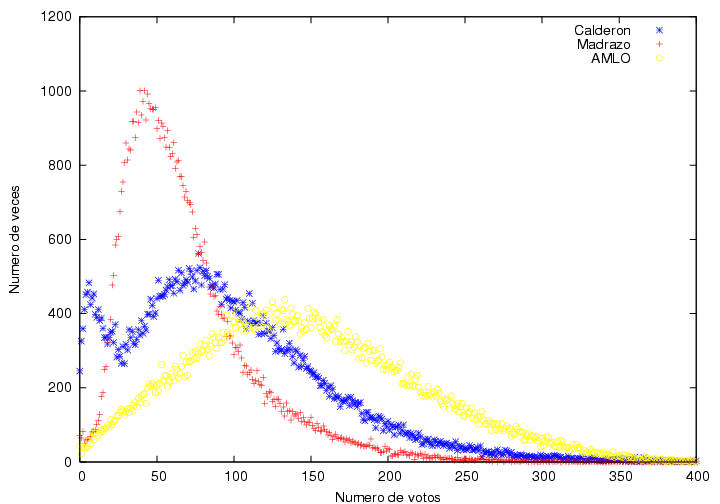
Datos.
Indice
Gerardo Horvilleur me acaba (16/vii/06) de comemtar una observación
interesante sobre la distribución de votos por
candidato. A pesar de que las distribuciones correspondientes a
Calderón y a AMLO son muy extrañas, la distribución de votos totales y
de votos válidos las cuales contienen datos de ambos candidatos
parecen ser normales. Incluso, la distribución para la suma de votos
de Calderón+AMLO también parece ser normal, como muestra la figura 30. Tal parece que las peculiaridades de ambas
distribuciones se cancelan una a la otra. Parafraseando a Gerardo,
¿por qué habría una relación como esta entre dos variables, las cuales
son más o menos independientes ya que los que no votaron por el
PRD no estaban obligados a votar por el PAN: había otras opciones.
La 'rodilla' visible del lado izquierdo de estas
distribuciones podría reflejar la distribución de tamaños de casillas
(quizás habría que correlacionarla con las listas
nominales). El piquito
hasta el extremo derecho de la distribución (en 760) debe corresponder a las
casillas especiales, las que seguramente agotaron su número disponible
de boletas.
Figura 30
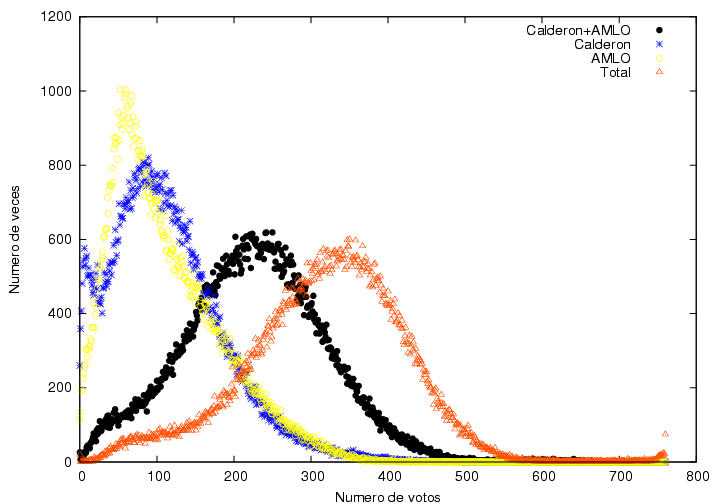
Datos.
Indice
En la figura 31 se muestra el histograma de las
listas nominales, i.e., el número de casillas que esperaban N
votos como función del número N de votos esperados en ellas
(sé que parece trabalenguas). Se advierten claramente cuatro grupos de
casillas: 822 sin lista nominal (especiales), 10858 que esperaban 375 o
menos votos, 26162 entre 375 y 500 votos y 92,946 entre 500 y 750
votos, las cuales suman 130,788 casillas. (Sigo sin entender por qué
hay más casillas para diputados y senadores que para presidente).
Figura 31
Datos.
Indice
En la figura 32 traté de buscar correlaciones
entre las votaciones por los tres candidatos principales. El eje
horizontal contiene la fracción de votos recibida por Calderón
(normalizada a la suma de los tres contendientes más fuertes, no al
total). El eje vertical tiene la fracción correspondiente a
AMLO. Cada punto corresponde a los resultados de un acta. Como la
votación total no puede exceder el 100%, la suma de ambas coordenadas
no puede exceder la unidad, correspondiente a la línea diagonal que va
de (0,1) a (1,0). La distancia a dicha diagonal es una medida del
porcentaje de votos obtenido por Madrazo. Así, el origen (0,0) (abajo
a la izquierda) correspondería a un acta en que Madrazo obtuvo todos
los votos (excepto quizás por los partidos pequeños), el punto (1,0)
(abajo a la derecha) correponde a actas en las que todos los votos son
para Calderón y el punto (0,1) (arriba a la izquierda) corresponde a actas
en que todos los votos son para AMLO. Hay una franja obscura
angosta alrededor de (0.2,0.8) que corresponde a muchas actas con pocos votos
para Madrazo y muchos para AMLO. Hay otra franja extendida desde (0.2,0.6)
hasta (0.6,0.2), un poco más angosta arriba a la izquierda y más ancha
abajo a la derecha, donde la votación relativa para AMLO y Calderón varía
mientras que la de Madrazo es casi constante y cercana al
20%. Finalmente, hay una isla ligeramente obscura cerca de (0.05,
0.55) en donde la votación para Calderón es inusualmente baja. Sin
embargo, en esa región no arrasa AMLO sino que comparte la votación
con Madrazo. Esa isla corresponde al extraño pico que muestran hasta
el extremo izquierdo los histogramas que describen la votación por
Calderón, por ejemplo en la figura 29.
Figura 32
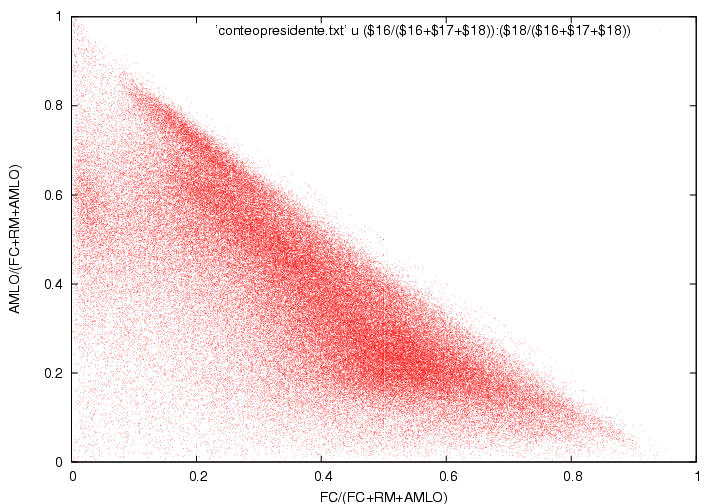
Datos.
Indice
La figura 33 es similar a la figura 21.5 pero elaborada con los datos del
conteo distrital. Ambas figuras son cualitativamente similares, es
decir, las correcciones realizadas durante el conteo no eliminaron su
estructura, la cual había descrito como una Gaussiana con la punta
recorrida.
El IFE ha preparado una respuesta
a algunos de los puntos mencionados arriba, en otras partes de esta
página y en una nota enviada al
Dr. Woldenberg.
En la página 12 de la respuesta se menciona que la figura 33 no
cuadra con ninguna de las bases de datos del PREP. Sin embargo, la
figura 33, como se menciona arriba, está realizada con la base de
datos del conteo distrital. Más adelante (página 13) se demuestra que
incluyendo las colas completas de la distribución, las cuales se
extienden desde -648 hasta 543, que la distribución no es
normal. Dicho análisis, basado en las pruebas estadísticas de
Kolmogorov-Smirnov confirma mi afirmación previa: las distribuciones
ilustradas por las figuras 33 y figura 21.5 no son Gaussianas. El IFE afirma que
la no-Gaussianidad proviene de las colas. Yo creo que, a
simple vista, se observa en la punta. En cualquier caso, la discusión
de la figura 33 se vuelve un poco irrelevante después de analizar las
figuras 34 y subsecuentes.
Figura 33
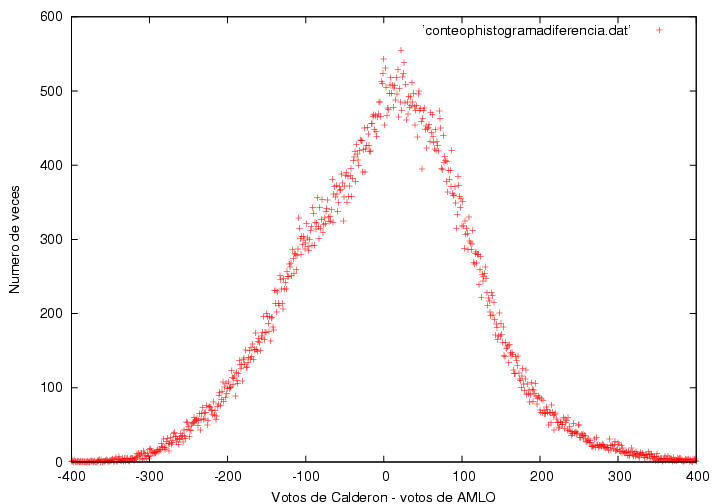
Datos.
Indice
La figura 34 muestra el mismo histograma que la
figura 33, pero separado en contribuciones
provenientes de los estados del norte y del sur, como en las figuras
29.1 y 29.2. La figura
34 muestra que mi interpretación original de las
figuras 21.5 y 33 es
errónea, como me había advertido la Dra. Gloria Koenigsberger. No se
trata de una curva normal cuyo pico se ve desplazado
hacia la derecha, sino de la suma de dos curvas, una centrada
alrededor de -50 (más o menos) correspondiente al Sur, en la que AMLO
domina las
preferencias, y otra centrada alrededor de 50 correpondiente al Norte,
y en la cual es Calderón quien domina las preferencias. La curva
correspondiente al Sur se puede ajustar relativamente bien por una
Gaussiana (a propuesta de Jaime Ruiz) de la forma a*exp(-b(x-c)^2), donde
x es la diferencia de
votos y a=292.1+/-1.0, b=5.28e-05+/-4e-07 y
c=-54.8+/-0.4 son los parámetros de ajuste (línea punteada). Por
otro lado, la curva correspondiente al norte no se parece a una
Gaussiana ni a una Lorentziana. La curvatura en las colas donde número
de veces es menor a 100 y la de la cima cima no es consistente con la
subida donde el número de veces pasa de 100 a 275. Además, la curva es
bastante asimétrica. Las diferencias entre la forma de las
dos distribuciones se vuelven evidentes si las desplazamos
horizontalmente para que se superpongan. En la figura
35 muestro las curva para el Norte desplazada 50 votos hacia la
izquierda y la curva para el Sur deplazadas 50 votos hacia la
derecha. Los astrónomos reconocerán en la curva del Norte el llamado
Perfil P Cisne (según Gloria Koenigsberger), correspondiente
al espectro que describe el color de la luz proveniente de ciertas
estrellas cuya radiación es selectivamente absorbida por el viento estelar.
El IFE ha preparado una respuesta
a algunos de los puntos mencionados arriba, en otras partes de esta
página y en una nota enviada al
Dr. Woldenberg.
En la página 14 de dicha respuesta, el IFE menciona que no puede
comentar sobre las figuras 34-36 pues no hallaron mi definición de norte
ni de sur. Desafortunadamente, no prestaron atención a la
nota que se halla dos párrafos arriba, que afirma que la división
norte-sur se realizó como en las figuras 29.1 y 29.2. En la
descripción de dichas figuras se halla la lista de estados que
arbitrariamente designé como norte y como sur.
Figura 34
Datos del norte y
del sur.
Figura 35
Datos del norte y
del sur.
Indice
Gerardo Horvilleur hizo la
observación de que el lado derecho de la
curva azul en la figura 35 no es demasiado
distinta al lado derecho de la curva amarilla, descrita por una curva
normal, mientras que el lado izquierdo difiere notablemente. Además,
observó que el cambio de comportamiento coincide con la región donde
las curvas azul y amarilla se intersectan en la figura 34, es decir, en aquella zona de la gráfica
donde AMLO le lleva una ventaja ligera a Calderón en la región
norte. Jaime Ruiz estudió estas
curvas y obtuvo que se pueden describir como dos lorentzianas distintas. La
figura 36 ilustra la misma idea pero empleando
ajustes gaussianos. Como habíamos visto en la figura figura 34, la distribución del sur puede ajustarse
bien a una curva normal. En cambio, es necesario dividir la
distribución del norte en dos intervalos, cada uno descrito por
una gaussiana de la forma a*exp(-b(x-c)^2) pero con parámetros a,b,c muy
distintos. Una describe la región en que Calderón le gana a AMLO. Los
parámetros correspondientes (a=307.1+/-1.5, b=6.71e-05+/-1.6e-06 y
c=44.0+/-1.2) son similares a los de
la gaussiana que describe la votación en el sur (a=292.1+/-1.0, b=5.28e-05+/-4e-07) excepto por
la posición (c=-54.8+/-0.4) del máximo. Otra describe la región donde
AMLO le gana a Calderón. Sus altura (a=73000) es ridículamente alta,
lo cual indica que dicha región es muy anómala. Ambas gaussianas se cruzan
donde la diferencia de votos es casi nula y a partir de ese punto se alejan
muy rápidamente entre sí y de los datos subsiguientes. ¿Por qué la
estadística en el sur, mayoritariamente perredista, es normal,
mientras que la estadística en el norte, mayoritariamente panista,
muestra una fuerte anomalía, pero sólo en el intervalo donde AMLO
tiene más votos que Calderón?
Figura 36
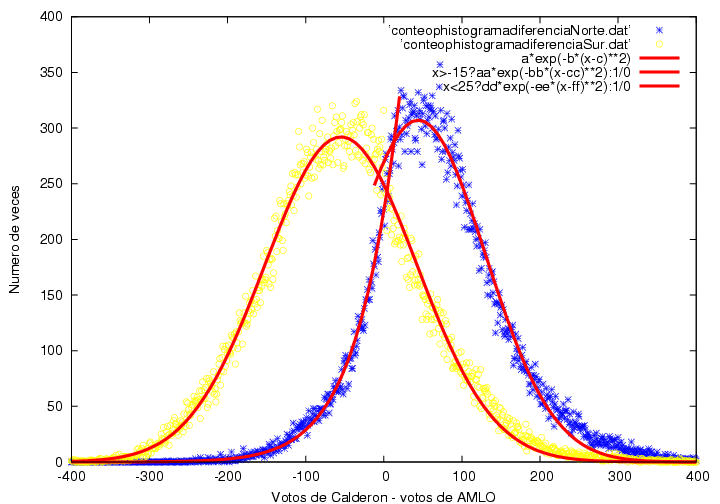
Datos del norte y
del sur.
Indice
Siguiendo sugerencias de Gerardo Horvilleur y de Jaime Ruiz, hice una
búsqueda de uno en uno de aquellos estados que
pudieran haber dado origen al
comportamiento singular de las funciones de
distribución de votos. En
la figura 37 muestro el histograma de diferencia
de votos correspondiente a los estados de Chihuahua, Guanajuato,
Jalisco y Nuevo León. Se ve completamente anómalo, es muy
asimétrico y tiene una enorme dispersión cerca del máximo.
Aunque más importante es
que al excluir dichos estados de la lista previa de estados del norte,
el histograma correspondiente a todos los estados del norte restantes,
mostrado en la figura 38 parece ser moderadamente
normal, mucho más que el histograma mostrado en la figura 36. Sin embargo, el ajuste gaussiano a*exp(-b*(x-c)**2) con
a=206+/-1, b= 0.000122+/-1.5-06, c=37.1+/-0.4) deje mucho que
desear aún y hay permaece una dispersión extraña cerca del máximo.
Figura 37
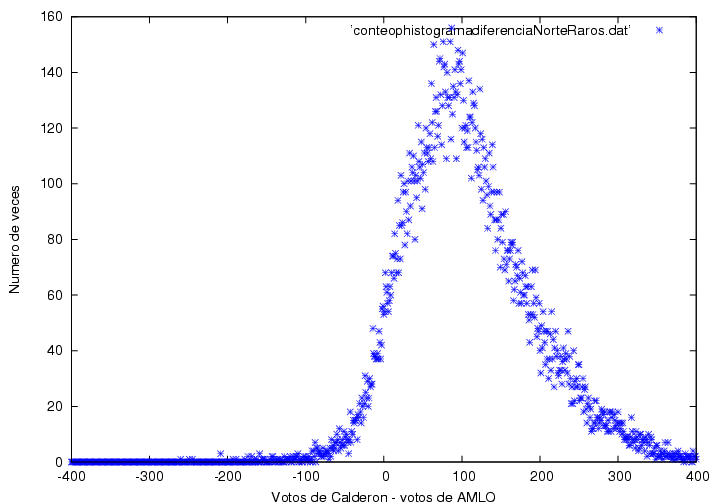
Datos.
Indice
Figura 38

Datos.
Indice
Indice
Figuras 39
En este directorio hay gráficas que muestran la
correlación de votos entre los distintos candidatos, una para cda
estado. La descripción de cada gráfica es equivalente a la de la figura 32).
Indice
La figura 40 muestra la correlación entre los
votos recibidos por los distintos candidatos pero tomando en cuenta
únicamente las actas que sí aparecieron en el Conteo Distrital pero
que no aparecieron en el PREP, es decir, las actas a las que se les
detectaron errores, inconsistencias, o que simplemente fueron
guardadas en un lugar inaccesible. Se observa que hay una enorme
dispersión; los puntos forman una nube que llena todo el espacio
disponible, llegando a las tres esquinas donde uno u otro de los tres
candidatos principales derrota abrumadoramente a los otros
dos. Curiosamente, esta figura no es representativa de la nación, pues
no se parece a la figura 32 correspondiente a
todo el país. Esto me sorprende, pues la probabilidad de cometer algún
error no debería estar correlacionada con la región geográfica. De
hecho, la misma figura muestra una correlación nula con la preferencia
electoral.
Figura 40
Indice
La figura 50, preparada por Jaime Ruiz, muestra los
resultados del Cómputo Distrital (CD) tal y como fue dado a conocer a
través de los medios a partir del medio día del miércoles 5 de
julio. La figura 51 muestra los mismos resultados
pero tomados de de una base de
datos que es una copia fiel de la base de
datos del IFE, pero ordenada en el tiempo. Las dos figuras son
consistentes.
Nota:Estas figuras fueron modificadas el 27/VII/06. Las
versiones previas de las mismas mostraba una inconsistencia entre los
resultados mostrados en los medios y los resultados obtenidos de las
bases de datos. El origen de dicha inconsistencia resulto ser un
error en la versión previa de mi base de datos ordenada en el
tiempo y no una manipulación en la presentación de los datos como
creíamos Jaime Ruiz y yo. El error se debió a la siguiente línea de
código
my $timesec=(((($dia-05)*24+$hora*60)+$min)*60+$seg);
cuyo propósito es convertir la fecha y hora en el número de segundos
transcurridos desde la media noche del 5/vii/06. Si estudian esa
línea con cuidado descubrirán el error. Pido una disculpa por el
mismo. Este tipo de errores ilustra el riesgo que he tomado al mostrar
en esta página resultados conforme los he ido obteniendo sin esperar
su plena confirmación. El
procedimiento usual en Ciencia es no publicar resultado alguno hasta que
hubiese confirmado varias veces por distintos caminos para evitar la
pena asociada a la publicación de erratas.
Figura 50

Figura 51
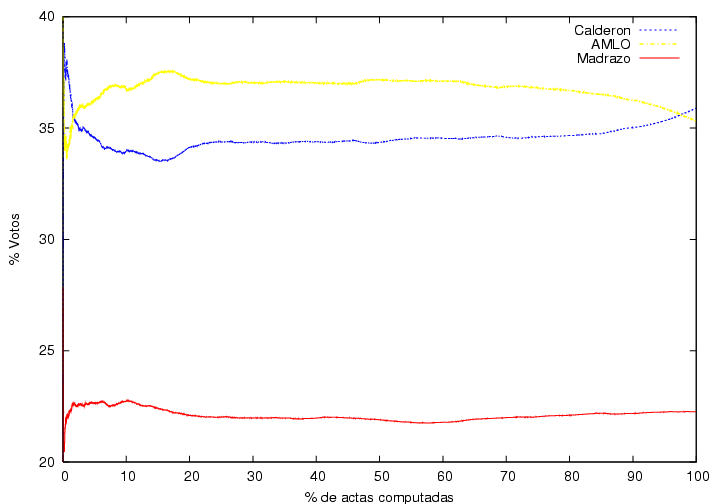
Indice
La figura 60 muestra para cada estado de la la
dispersión obtenida en la estadística del dígito menos
significativo, i.e., el que va hasta el extremo derecho. Como se
discutió al presentar las figuras 24-26, se espera
que cada dígito sea equiprobable y que aparezca alrededor de 0.1 N
veces en un estado, con fluctuaciones caracterisadas por una
desviación estandard dada por la raiz cuadrada de 0.1*0.9*N, donde N
es el número de actas contabilizadas. Calculé la varianza empleando
para ello los diez dígitos 0,1,...9 en cada uno de los 32 estados, los
cuales aparecen numerados en orden alfabético en el eje horizontal de
la figura. En el eje vertical puse el valor de la
desviación estandard de la muestra normalizada al valor de la desviación
estandard esperada. Para que la gráfica no quedara amontonada,
desplacé los resultados corresondientes a APM y a PBT una distancia de
2 y 4 respectivamente en la dirección vertical.
De manera análoga a lo observado con los datos del conteo,
observamos que la varianza toma valores más grandes en general para el
PAN que para la Alianza por México, para la cual es más grande aún que para la
Coalición por el Bien de Todos. Arriegándome a un primer ejercicio de
principiante en
cuantificación estadística, evalué crudamente la probabilidad de estos
resultados empleando la distribución chi cuadrada con 9 grados de
libertad (10 dígitos - 1) (Esto no es estrictamente correcto pues los
resultados para los 10 dígitos no son estríctamente
independientes). En Guerrero el PAN muestra una desviación estandard
mayor a 2.2. La probabilidad de que esto hubiese ocurrido en un estado
dado de acuerdo a la distribución chi cuadrada es menor a una parte
en 100,000. La probabilidad de que hubiese sucedido en alguno de los
32 estados es entonces menor a 3 partes en 10,000.
Del mismo modo, la probabilidad de obtener una variancia mayor a 1.6
es menor a 6 partes en 1000. Sin embargo, para el PAN dicha variancia
se excede en tres estados. La probabilidad de dicho evento es menor a
una parte en mil. Se puede concluir entonces que la probabilidad de
una distribución de dígitos como la mostrada en la figura 60
¡es sumamente improbable! (Nota: Fernando Rodriguez ha hecho
una crítica a la hipótesis de
equiprobabilidad.)
El IFE ha preparado una respuesta
a algunos de los puntos mencionados arriba, en otras partes de esta
página y en una nota enviada al
Dr. Woldenberg.
En la página 15 de dicha respuesta se critica la suposición de
equiprobabilidad en términos similares a los de la nota mencionada arriba. También se
critica mi empleo de una distribución binomial para cada dígito cuando
debí haber empleado una distribución multinomial, dado que la suma del número
total de apariciones de cada uno de los 10 dígitos está constreñida al
número total de votos en cada estado. Esta última crítica es acertada,
pero dudo que modifique el resultado pues únicamente reduciría el
numero de grados de libertad de 10 a 9. Sobre la primera crítica, es
necesario valorarla, aunque parece consistente con el hecho de que la
desviación estandard para el PAN sea mayor en estados como Chiapas,
Guerrero y Tabasco, donde el PAN obtuvo una votación relativamente
pequeña.
Figura 60
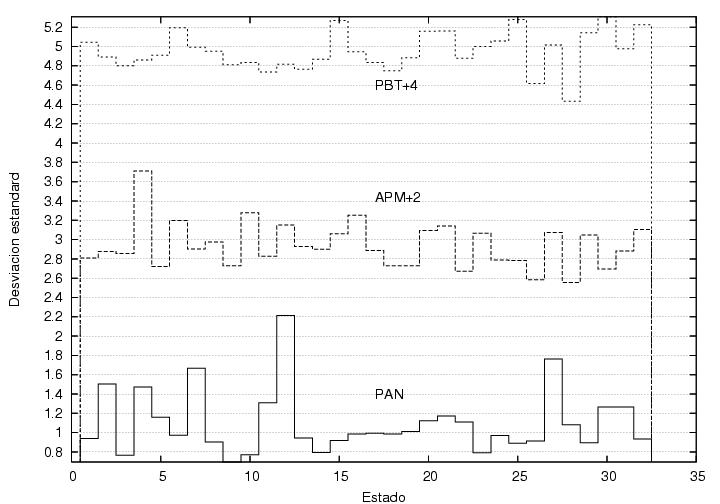
Lista de estados: 1 Aguascalientes, 2 Baja California, 3 Baja
California Sur, 4
Campeche, 5 Coahuila, 6 Colima, 7 Chiapas, 8 Chihuahua, 9
Distrito Federal, 10 Durango, 11 Guanajuato, 12 Guerrero, 13 Hidalgo,
14 Jalisco, 15 Mexico, 16 Michoacan, 17 Morelos, 18 Nayarit, 19 Nuevo
Leon, 20 Oaxaca, 21 Puebla, 22 Queretaro, 23 Quintana Roo, 24 San
Luis, 25 Sinaloa, 26 Sonora, 27 Tabasco, 28 Tamaulipas, 29 Tlaxcala,
30 Veracruz, 31 Yucatan, 32 Zacatecas.
Indice
El país está dividido en estados, distritos, secciones y casillas.
Las distintas casillas de una misma sección se hallan juntas una a la
otra, por lo cual es de esperar que el resultado de la
votación sea similar en todas ellas, aunque puede haber
fluctuaciones. La decisión sobre qué ciudadano vota en cual casilla de
una sección se toma de acuerdo a la primera letra de su apellido. Así,
por ejemplo, en alguna casilla pudo haber votado la familia Alvarez
mientras que en una casilla contigua votó la familia Zapata. Si ambas
familias fueran numerosas y una fuera panista y la otra perredista,
entonces en una casilla el PAN hubiera obtenido un porcentaje mayor de
votos que el promedio y en la otra hubiera obtenido un porcentaje
menor. Análogamente, en la primera casilla la CPBT hubiera obtenido un
porcentaje menor y en la otra un porcentaje mayor. Ambos partidos
hubieran tenido fluctuaciones en esa sección. Por otro lado, si todas
las casillas de la sección hubieran presentado resultados similares,
pero los resultados de una sóla de las urnas fueran manipulados añadiendo
votos a uno de los partidos, dicho partido mostraría fluctuaciones
grandes a la vez que aumentaría el porcentaje de votos a su favor,
mientras que los demás mostrarían fluctuaciones pequeñas y una pequeña
disminución del porcentaje. Lo opuesto pasaría si se sustrajeran votos
correspondientes a un partido. Aunque los escenarios as descritos
arriba no agotan todas las posibilidades, si muestran que puede ser
interesante estudiar las fluctuaciones entre los resultados
electorales obtenidos en las casillas de una misma sección.
En la figura 65 muestro la diferencia entre el
PAN y la CPBT sobre todas las secciones cuyas fluctuaciones sobrepasan
cierto umbral mínimo. Hay tres curvas. En una de ellas comparé las
fluctuaciones tanto del PAN como de la CPBT para decidir qué secciones
contribuyen a cada punto de la curva y cuales no. Observamos que sí
hay una correlación entre las fluctuaciones y el resultado de la
elección, el que sube de poco menos del 0.06% al sumar todas las
secciones hasta poco más de 1.3% al considerar secciones con
fluctuaciones de más de 1.5%. Aquí cuantifiqué las fluctuaciones a
través de la desviación estandard simple.
Para desglozar las contribuciones de las fluctuacines de cada uno de
los partidos, también incluí una curva para la cual el criterio de
decisión se basa en las fluctuaciones únicamente del PAN, haciendo
caso omiso de las fluctuaciones de la CPBT. Se ve claramente que
mientras más grandes son las fluctuaciones del PAN, obtiene una
ventaja mayor sobre la CPBT. La ventaja es casi lineal en las
fluctuaciones. Incluí también una curva empleando como criterio
únicamente las fluctuaciones de la CPBT, ignorando las fluctuaciones
del PAN. El resultado es análogo pero al revés, i.e., mientras más
fluctuaciones tiene la CPBT menor es la ventaja del PAN, la cual se
revierte rápidamente y se convierte en ventaja para la CPBT.
No sé cual es la explicación de estas curvas, aunque uno podría
especular: Los resultados son consistentes con que cada partido hubiera
añadido a algunas urnas de algunas secciones votos para sí de manera
irregular. Mientras más votos irregulares, más fluctuaciones y más
ventaja. También serían consistentes con que cada partido hubiera
sustraido votos del contrincante pero de manera selectiva,
extrayendole más votos donde tuviera más ventaja. O que un partido se
hubiera añadido votos a sí mismo de manera irregular y hubiera
sustraido votos ajenos de manera selectiva, o...
Figura 65
Indice
Información sobre el recuento
- Tengo una lista tentativa e incompleta (7/VIII/06) de
casillas en las que quizás
se lleve a cabo el recuento. La lista está aquí. Los registros de los Cómputos
Distritales correspondientes están aquí.
- Los 25 estados donde se harán recuentos y el número de casillas a
recontar en cada uno son tentativamente Aguascalientes (436), Baja
California (1099), Campeche (169), Chiapas (81), Chihuahua (479),
Coahuila (351), Colima (251), Distrito Federal (226), Durango (344),
Guanajuato (313), Jalisco (2556), México (362), Michoacán (297),
Morelos (370), Nuevo León (507), Puebla (194), Querétaro (147),
Quintana Roo (8), San Luis Potosí (465), Sinaloa (329),
Sonora (801), Tamaulipas (942), Veracruz (346), Yucatán (228),
Zacatecas (218).
- Los datos de arriba no cuadran con los números de casilla por
estado lista
que publicó el TRIFE. El número total de distritos (145) tampoco
cuadra con los 149 distritos a recontar.
- Sin embargo, los datos de la página del TRIFE no son consistentes
tampoco con el boletín de prensa
emitido por el mismo trife, el cual además muestra
errores. Guerrero aparece con un distrito sin casillas y la
suma de los distritos (172, mostrada a mano) no es igual al número
total de distritos (149, en el primer renglón de la tabla).
- Desafortunadamente, no he encontrado la lista oficial de
casillas a recontar.
- Espero poder extraer la lista de casillas a recontar a partir de
las sentencias del tribunal, las cuales podrá encontrar aquí.
- Los resultados de la elección sobre estas 11,273 casillas a recontar
son:
| Partido | Votos | Porcentaje |
| PAN | 1,840,839 | 48.93% |
| APM | 856,645 | 22.77% |
| PBT | 815,403 | 21.68% |
| NA | 41,117 | 1.09% |
| ASDC | 107,966 | 2.87% |
| No registrados | 27,007 | 0.72% |
| Nulos | 72,871 | 1.94% |
| Válidos | 3,688,977 | 98.06 |
| Total | 3,761,848 | 100.00% |
| Lista Nominal | 6,447,413 | |
- Las sentencias sobre el recuento emitidas por el tribunal los días
28 y 30 de agosto pueden hallarse aquí.
- Tengo una lista de casillas recontadas con algunos resultados
del recuento. Algunos de sus resultados se pueden consultar aquí.
- Es necesario verificar que esta base de
datos sea consistente con las sentencias.
- Comparé esta base de datos con la base que usé previamente (puntos
1-8 arriba). Los 11,273 registros de la base previa y los 11,654 de la nueva
contienen 11,177 registros en común.
- De la misma se desprende que:
- De 11,654 registros que tengo sobre el recuento, hallé 11,651 en
las bases de datos del PREP, incluyendo las bases de datos con los
votos del extranjero y las bases de datos con inconsistencias.
- De estos, hay
8,630 donde el número de votos obtenidos por cada uno de los partidos
pan+apm+pbt+na+asdc mas los no registrados mas los nulos mas las boletas
sobrantes no coincide con las boletas recibidas.
- Sobre estos registros, el número de votos excede
al número de boletas distribuidas a los votantes en 578,237.
- En 4,373 de esas casillas hubo 646,936 votos de más y en 4,257
casillas hubo 68,699 votos de menos, es decir, 715,635
votos irregulares, 83 votos irregulares por casilla.
- El número de votos de más es mayor que la diferencia entre el
PAN y la CPBT. Por lo tanto, un resultado del recuento es que
no se puede saber con certeza qué candidato recibió el mayor número
de votos. Empleando el mismo criterio con el
cual el tribunal anuló algunas casillas (i.e., donde las
irregularidades fueron mayores a las diferencias entre los
candidatos) debería haber anulado la elección.
- En esas casillas el PAN le gana a la CPBT por 772,821 votos
(646,936 votos de ventaja en aquellas 4,373 casillas donde sobran votos y
402,185 votos de ventaja en aquellas 4,257 casillas donde faltan votos),
de manera que, de haberse anulado dichas casillas, o cualquiera de los dos
grupos (donde hubo más votos que las boletas disponibles o donde hubo menos)
hubiera ganado la CPBT.
- Parte del motivo por el cual hubo tantos votos de más en el inciso
(d) es la pésima capacitación que se les dió a los funcionarios de
casilla, muchos de los cuales no supieron cómo llenar las actas,
y en particular, el dato correspondiente a el número de boletas
recibidas antes de la elección. De las 8,630 casillas con
irregularidades mencionadas
arriba, hay 1,078 donde el número de boletas recibidas no quedó
asentado en actas y 128 donde se registraron cero boletas recibidas,
lo cual es poco creible. Por lo tanto, es imposible saber si en verdad
sobraron o no votos en esas 1,206 casillas.
Quizás el número de boletas
recibidas por cada casilla esté registrado en alguna otra base de
datos del IFE, pero no la han hecho pública.
- Excluyendo las casillas inverificables, obtengo
7,424 registros donde el número total de votos mas las boletas
sobrantes no coincide con las boletas recibidas.
- En estos registros, el número de votos es
menor en 24,900 al número de boletas distribuidas a los votantes.
- En 3,167 de esas casillas hubo 43,799 votos de más y en 4,257
casillas hubo 68,699 votos de menos, es decir, 112,498 votos
irregulares, 15 votos irregulares por casilla.
- Aunque el número de votos irregulares (agregados o sustraidos) es
ahora menor que la diferencia entre los primeros lugares, es casi la
mitad de dicha diferencia. Tomando en cuenta que de acuerdo al PREP
hubo muchas más irregularidades que las verificadas en el recuento
(ver la sección sobre las dificultades en
el PREP y el articulo con su análisis
detallado) y que el PREP es la única base de datos pública con
suficiente información para poder verificar la calidad y certeza de la
elección, y dado que en el recuento quedaron 1,206 registros no
verificables, no puede saberse con certeza qué candidato obtuvo más
votos.
- En las 7,424 casillas mencionadas arriba el PAN le gana a la CPBT
por 692,759 votos (290,574 votos de ventaja en aquellas 3,167 casillas
donde sobran votos y
402,185 votos de ventaja en aquellas 4,257 casillas donde faltan votos),
de manera que anulando todas estas casillas, o cualquiera de los dos
grupos (donde hubo más votos que las boletas disponibles o donde hubo
menos) hubiera ganado la CPBT.
- Otro criterio (limitado) para detectar irregularidades donde no sabemos
cuántas boletas le entregaron a cada casilla es comparar el número
total de votos con la lista nominal, añadiéndole los diez votos
reservados para los funcioinarios de casilla y para los representantes
de partido.
- Dentro de las casillas recontadas hubo 2,505 donde el número total
de votos sobrepasa a la lista nominal + 10 (excluyendo
las casillas especiales). El exceso de votos es 21,899 sobre la lista
nominal + 10, 9 por casilla. En esas casillas el PAN le gana a
la CPBT por 233,062 votos. Si se anularan dichas casillas...
- No tengo a la mano la lista de casillas anuladas, por lo que a
continuación voy a simular los resultados que hubiera tenido
el recuento si aplico los criterios de los magistrados sobre las bases
de datos a mi disposición.
- Definiendo el número de votos irregulares como
Vi=abs(Vv+Vn+Bs-Br),
donde Vv es el número de votos válidos hallados en el recuento,
Vn el número de votos nulos, Bs el número de
boletas sobrantes después de la elección y Br el número de
boletas recibidas antes de la elección, el criterio para anular una
casilla fue Vi > V1-V2, donde
V1 y V2 representan los votos obtenidos por el
primer y segundo lugares.
- Aplicando directamente dicho criterio a las casillas recontadas
obtengo 1,829 que debieron ser anuladas, empleando datos del recuento
y tomando en cuenta que los ganadores podrían haber sido PAN y CPBT,
CPBT y APM o APM y PAN en cualquier orden. Los detalles están en la
siguiente tabla
| Num. casillas | PAN-CPBT | Orden |
|---|
| anulables | (CD) | |
|---|
| 2 | 157 | APM = PAN = PBT |
| 4 | 61 | APM > PAN = PBT |
| 26 | 869 | APM = PAN > PBT |
| 311 | 11,939 | APM > PAN > PBT |
| 5 | -89 | APM = PBT > PAN |
| 64 | -467 | APM > PBT > PAN |
| 17 | 1,155 | PAN > APM = PBT |
| 728 | 70,971 | PAN > APM > PBT |
| 19 | 12 | PAN = PBT > APM |
| 559 | 31,879 | PAN > PBT > APM |
| 1 | -1 | PBT > APM = PAN |
| 35 | -1,667 | PBT > APM > PAN |
| 58 | -1,057 | PBT > PAN > APM |
| 1,829 | 113,762 | TOTAL |
- De acuerdo al CD, sobre
esas casillas el PAN había obtenido 230,799 votos y la CPBT 117,037,
i.e., el PAN le llevaba una ventaja a la
CPBT de 113,762 votos, los que se deberían descontar de la
ventaja total de 243,934 que llevaba el PAN, reduciendola a 130,172.
- Sobre las casillas no anulables de acuerdo a este critero, el PAN
perdió 6,785 votos al comparar los resultados del recuento con los del
CD. Similarmente, la PBT ganó 817 votos. De manera que sobre la
ventaja del PAN sobre la PBT se reduciría en otros 7,602 votos.
- De acuerdo a estos criterios, el PAN hubiera obtenido una votación
final de 15,000,284-230,799-6,785=14,762,700 votos y la CPBT de
14,756,350-117,037+817=14,640,130. El PAN le hubiera ganado a la CPBT
por únicamente 122,570 votos.
- El total de votos en las casillas anuladas hubiera sido de
519,240. El número de votos en las casillas no anuladas hubiera
disminuido en 4,088. El número total de votos en los CD fue
41,791,322. Por lo tanto, el número total de votos después del
recuento sería 41,267,994.
- Los resultados estan resumidos en la siguiente tabla:
| Total | PAN | %
PAN | CPBT | %CPBT | Dif. PAN-CPBT | % Dif. |
|---|
| Cómputos
Distritales | 41,791,322 | 15,000,284 | 35.89%
| 14,756,350 | 35.31% | 243,934 | 0.58% |
| Anulación de
casillas | -519,240 | -230,799 | | -117,037 | | -113,762 | |
| Otros cambios en
recuento | -4,088 | -6,785 | | +817 | | -7,602 | |
| Resultados finales | 41,267,994 | 14,762,700 | 35.77% | 14,640,130 | 35.48% | 122,570 | 0.30% |
- Aplicando los criterios de anulación de casillas enunciados por el
TEPJF, la ventaja del PAN sobre la CPBT se hubiera reducido
aproximadamente a la mitad de la que llevaba en los Cómputos
Distritales, i.e., hubiera ganado la elección presidencial por 122,570
votos que representan apenas el 0.297% del número total de votos. Esto
sin tomar en cuenta las irregularidades que fueron detectadas en el
PREP y en el CD en cerca de la mitad de las casillas (detalladas aquí), la mayor parte de las cuales no fue
sujeta a recuento.
- Desde luego, el TEPJF ha de haber empleado otros criterios además
del enunciado arriba, por lo cual los resultados mostrados en la tabla
previa no coinciden con los resultados oficiales.
- En particular, es importante saber qué hizo el TEPJF en aquellas
casillas en las cuales el PREP no reporta el número de boletas
recibidas antes de la votación, o donde erróneamente se reportan cero
boletas recibidas. ¿Cómo se puede verificar si hubo o no
irregularidades en dichas casillas y la magnitud de las mismas? ¿Qué
criterios empleó el TEPJF en las mismas? Aquí podrá consultar la lista de
casillas correspondiente.
- La transparencia que mostró el IFE al hacer públicos sus datos en
forma electrónica de manera inmediata al terminar la votación se ha
ido perdiendo durante las etapas posteriores de la elección y no
corresponde a la falta de información útil durante el recuento y la
calificación de la elección.
La figura 70 muestra el histograma de la
diferencia entre los votos obtenidos por FC menos los votos obtenidos
por AMLO. La figura es similar a las figuras 34 o
37, pero están elaboradas tomando en cuenta
únicamente los datos de las casillas a recontar. El lado derecho de la
gráfica está descrito por una curva gaussiana de la forma a
exp(-b(x-x0)2) con los parámetros a=67,
b=6.5*10-5 y x_0=49. El ancho y centroide de esta curva son
consistentes con los que describen la parte gaussiana de la
distribución del norte en la figura 36. Sin
embargo, esta curva muestra una fuerte discontinuidad cuando la
diferencia de votos se anula. Por ejemplo, hay 68 casillas donde FC le
ganó a AMLO por 2 votos mientras que sólo hay 18 casillas donde AMLO
le ganó a FC por 2 votos. No se si esta discontinuidad sea consecuencia
de una irregularidad o sea consecuencia del procedimiento para elegir
esta colección de casillas, en la que se pudieron haber eliminado
casillas en las que AMLO gana por un número pequeño de votos. Sin
embargo, la caido abrupta al cruzar por cero está presente en
otros histogramas donde no la hubiera esperado, como la curva del lado
derecho de la figura 36.
Figura 70

Indice
Comentarios sobre la Calificación de la
Elección
Si bien es cierto que... no ha quedado acreditado que...
(TEPJE, 5/IX/06)
- Si bien es cierto que los magistrados recibieron varios escritos
describiendo toda suerte de anomalías, errores e inconsistencias, no
ha quedado acreditado que las hayan leido, comprendido, estudiado,
ponderado, considerado, buscado asesoría ni respondido.
- Si bien es cierto que los magistrados supieron desde
semanas atrás que
los datos oficiales publicados por el IFE muestran inconsistencias
como las siguientes:
- De las 51,538 secciones verificables, en 16% el número de boletas
depositadas en las urnas es mayor a la
diferencia entre las boletas recibidas y las sobrantes (632,682
boletas de más) y en el 37% es menor (580,875).
En total, hay 27,416 secciones (53%) con este tipo de
inconsistencia, la cual involucra 1,213,557 boletas.
- De 42,093 secciones, en 27% el total de votos contabilizados es
mayor que el número de ciudadanos que se presentaron a votar (517,866
votos de más) y en otro 27% es menor (761,954). En total, hay
22,498 secciones (53%) con este tipo de inconsistencia, la cual
involucra 1,279,820 votos.
- De 50,035 secciones, en 19% el
número de boletas depositadas en la urna es mayor al número de
ciudadanos que se presentaron a votar (685,298 boletas de más) y en
32% es menor
(1,213,921). En total, hay 25,150 secciones (50%)
con este tipo de inconsistencia, la cual involucra 1,899,219
boletas.
- De 40,057 secciones, en 28% el número total de votos contabilizados
es mayor al número de boletas depositadas en las urnas (345,112 votos
de más) y en 14% es menor (156,094). En total, hay 16,547 secciones
(41%) que muestran este tipo de inconsistencia, la cual involucra
501,206 votos.
no ha quedado acreditado que entendieran que la incertidumbre
asociada a 1,213,557 boletas depositadas que difieren del número de
boletas empleadas, 1,279,820 votos que difieren del número de
votantes, 1,213,921 boletas que difieren del número de votantes y
501,206 votos que difieren del número de boletas depositadas es mayor
a la diferencia de votos entre los contendientes principales.
- Si bien es cierto que los magistrados calificaron la elección
presidencial y que su resolución es jurídicamente inatacable, no
ha quedado acreditado que hubieran garantizado que la
elección cumpliera con el criterio legal, y menos aún, con el criterio
técnico de certeza.
Me imagino un partido de futbol con magistrados en lugar de árbitros:
- Si bien es cierto que le cometieron una falta cuando iba
a tirar desde el área, no ha quedado acreditado que hubiera metido gol
de no haber recibido una patada en la espinilla. Por lo tanto, la
pretensión de tirar un penal es improcedente.
- Si bien es cierto que al momento del pase se hallaba en fuera de
lugar, no ha quedado acreditado que hubiera fallado el gol de no
habrse adelantado. Por lo tanto, la pretensión de anular
el gol es improcedente.
Si bien es cierto que 1+1=2, no ha quedado acreditado que 7
magistrados se hayan enterado.
La jurisprudencia recién establecida enseña que, como nadie podría
demostrar jamás que perderías de jugar limpio, a partir de ahora todas las
trampas valen. Si no las haces, dudaremos de tu salud mental y
merecerás perder. Si las haces, quizás te regañen cuando te descubran...
y luego te declararán presidente electo..
Indice
Información sobre la elección de gobernador en
Chiapas
- Aquí hay una base de datos
sobre el PREP de la elección. Los datos fueron tomados de las páginas
web publicadas en
http://www.prep-chiapas.com.mx/current/gobernador/,
habiéndose capturado cada 5 mins. aproximadamente.
- Aquí están los mismos datos,
pero con los votos acumulados.
- El programa que empleé para bajar las páginas está aquí.
- El programa para juntar todas las páginas web y formar con ellas
una base de datos está aquí.
Indice
En la Figura 80 se muestran los resultados del
PREP para la elección de gobernador en Chiapas...
Figura 80
Indice
Indice
A partir de un análisis de los datos del Programa de
Resultados Electorales Preliminares (PREP) y de los Cómputos
Distritales (CD) que el IFE hizo públicos, he
encontrado, con ayuda de muchos colegas y de colaboradores que me son
aún desconocidos, una larguísima serie de resultados que, a mi
parecer, son anómalos y demandan una explicación detallada. Quizás
haya expertos en elecciones y expertos en estadística que puedan
ofrecer dicha explicación, o quizás sea necesario esperar el
desarrollo de investigaciones científicas detalladas sobre esta
elección; sin duda, investigaciones conclusivas de este tipo
requerirán mucho tiempo en llevarse a cabo. Quizás no haya problemas
con el PREP ni el CD y
las anomalías que he señalado no lo sean en realidad. Sin embargo, mientras
no se realicen las investigaciones a que me he referido y no veamos
los resultados o hasta que nos aclare algún experto nuestras dudas de
manera convincente, y con base en la información que he logrado
recopilar y los análisis que he logrado realizar, considero que
es razonable sospechar que pudo haber habido una manipulación de los
resultados reportados por el PREP y por el CD.
Se me ha dicho que parte del trabajo que he realizado es irrelevante pues a
fin de cuentas el PREP no tiene validez legal. Los datos importantes
son los del CD distrital. Sin embargo, me resisto a creer que el
PREP haya puesto a nuestra disposición toda la información detallada
de la elección con el propósito de que nos entretengamos la noche de
la elección o que juguemos a las quinielas. El PREP surgió como un
mecanismo que permita a los ciudadanos monitorear y analizar el
desarrollo transparente de las elecciones, volviendo difícil o
imposible el que se
cometan irregularidades sin que sean detectadas. En este sentido,
considero que el PREP es un gran instrumento. Pero para que sea un
gran éxito, debe llevarse a sus últimas consecuencias. Así como se han
hallado irregularidades en el PREP, se han hallado irregularidades
semejantes en el CONTEO, además de inconsistencias internas e
inconsistencias mutuas entre ambas bases de datos.
Cuando en Ciencia tenemos dudas sobre un resultado, lo que procede es
repetir la medición, repetir el cálculo, verificar, buscar las
fuentes de error, eliminarlas, etc. Cuando las dudas tienen una
trascendencia tanto mayor para la vida democrática de un país, no
debemos hacer menos.
Indice
Este trabajo ha sido apoyado, inadvertidamente e involuntariamente,
por el proyecto DGAPA-UNAM-IN111306. Deseo agradecer immensamente a
todos aquellos que han participado en este trabajo análisis enviandome
notas, datos, sugerencias o simplemente su apoyo y entusiasmo.
Indice
Si desea comentar esta página, por favor envíeme un mensaje aquí o, mejor aún, añada un
comentario al blog.
Puede consultar los mensajes recibidos con anterioridad, organizados como
cronológicamente
o como
hilos de discusión.
Indice
- Estudio de
Julen Sagardoa sobre el comportamiento
periódico anómalo en los datos de la elección al presentarlos como
función del tiempo de arribo a los centros de captura. Al identificar
y eliminar los
datos de grupos de casillas estadísticamente improbables el resultado
de la elección cambia fuertemente.
- Estudio
titulado Evidencias estadísticas de una manipulación en los conteos
de los votos de las
elecciones presidenciales del
2 de julio de 2006.
¿fraude ``cibernético''? por Victor Romero.
- Base de datos de la
elección de gobernador en Tabasco.
- Base de datos de la
elección de gobernador en Tabasco.
- Video
tomado de EnContexto, en el cual un ex-mapache confiesa cómo ejecutó
un par de fraudes electorales en México y discute sobre las
posibilidades en la elección del 2 de julio.
- Análisis de Pedro Martínez
sobre todos los aspectos de la elección.
-
Artículo de Craig Adair titulado Mexico Misses Chance to
Foster Democracy, publicado en el Austin-American Statesman el
14/ix/06.
-
Out for the Count. Análisis de nuestras elecciones por el
profesor James K. Galbraith, quien ocupa la cátedra Lloyd M. Bentsen,
Jr. Chair in Government/Business Relations en la escuela LBJ School of
Public Affairs de la Universidad de Texas en Austin.
- Uncertainty and Errors in the Mexican
Election of July, 2006. Primer intento (muy poco pulido aún) de
traducción al inglés del artículo
Incertidumbre y errores en las elecciones de julio del 2006
por W. Luis Mochán.
- Espacio para
exponer, discutir e integrar análisis cuantitativos que se han
realizado con los datos de las elecciones del 2 de julio del 2006 en
México.
- Denuncia de Juicio Político al TEPJF por su resolución de las impugnaciones a la
elección presidencial del 2006 en las cuales violaron el artículo 7 de la
Ley Federal de Responsabilidades de los Servidores Públicos, no asumieron sus
facultades constitucionales, actuaron en contravención
a la Constitución Federal, contra su naturaleza institucional y
contra de la lógica jurídica que ellos mismos utilizaron de manera
oficial hace dos años. El tribunal había recibido desde el 30 de julio
del 2006 una serie de estudios técnicos (expediente SUP-JIN-212/2006)
que demuestran dudas insoslayables que representan circunstancias que
ponen en entredicho la certeza de los resultados de la elección del
2006, los cuales fueron ignorados. La solicitud de juicio político
se encuentra en formato .doc aquí y en
formato html aquí.
- El
extraño criterio de los jueces: análisis de Pedro Martínez sobre
lo absurdo de algunos criterios empleados por los magistrados del
TEPJF en sus decisiones recientes.
Ya confirmé en lo fundamental el escrito de Pedro Martínez. Por
ejemplo, en la sentencia
SUP-JIN-013-2006 el tribunal dice
Sin embargo, en todos los casos, los errores precisados no son
determinantes para el resultado de la votación, porque aún restando
los votos que pudieron haberse computado irregularmente al partido
político o coalición que logró el primer lugar en las casillas de que
se trata, las posiciones entre éste, y quien ocupó el segundo lugar,
permanecen inalteradas.
De esa manera si la existencia del error no genera en sí misma la
nulidad de la votación recibida en la casilla, sino sólo en los casos
en que resulte determinante, al no cumplirse esta condición, resulta
inatendible la pretensión de nulidad de la votación relativa al bloque
de casillas analizado.
Es decir, si yo pierdo en un casilla por, digamos 100 votos, puedo
robarle 49 votos a mi adversario impunemente. Si en cambio gano por 1
voto, me puedo añadir otros 100 sin problema. El tribunal
diría que como el ganador de la casilla no cambiaría al devolver los
votos faltantes o al eliminar los votos sobrantes, no hay por qué
anular dicha casilla, como si el triunfador se determinara por el
número de casillas a su favor y no por el número total de
votos. En mi opinión, este es un fraude, pero no de un partido
contra otro, sino
del tribunal contra nuestro sistema electoral. Hablemos ahora del
respeto a las instituciones...
- Artículo titulado
Incertidumbre y errores en las elecciones de julio del 2006
por W. Luis Mochán (yo), en el que se analizan las bases de datos del
IFE para estimar la magnitud de los errores esperados durante la
cuenta de los votos y se concluye que es mucho mayor que la diferencia
entre FC y AMLO. En resumen,
- De las 51,538 secciones verificables (en algunas faltan datos para aplicar
la prueba), en 16% el número de boletas depositadas en las urnas es
mayor a la
diferencia entre las boletas recibidas y las sobrantes (632,682
boletas de más) y en el 37% es menor (580,875)
En total, hay 27,416 secciones (53%) con este tipo de
inconsistencia, la cual involucra 1,213,557 boletas.
- De 42,093 secciones, en 27% el total de votos contabilizados es
mayor que el número de ciudadanos que se presentaron a votar (517,866
votos de más) y en otro 27% es menor (761,954). En total, hay
22,498 secciones (53%) con este tipo de inconsistencia, la cual
involucra 1,279,820 votos.
- De 50,035 secciones, en 19% el
número de boletas depositadas en la urna es mayor al número de
ciudadanos que se presentaron a votar (685,298 boletas de más) y en
32% es menor
(1,213,921). En total, hay 25,150 secciones (50%)
con este tipo de inconsistencia, la cual involucra 1,899,219
boletas.
- De 40,057 secciones, en 28% el número total de votos contabilizados
es mayor al número de boletas depositadas en las urnas (345,112 votos
de más) y en 14% es menor (156,094). En total, hay 16,547 secciones
(41%) que muestran este tipo de inconsistencia, la cual involucra
501,206 votos.
Las mismas cuentas pero realizadas casilla por casilla en vez de
sección por sección arrojan aún más inconsistencias.
En resumen, en cerca de la mitad de las secciones hay inconsistencias que
involucran del orden de un millón de votos. Con incertidumbres de
ese tamaño,
¿cómo podemos definir un triunfo certero con una ventaja de
poco más de doscientos mil votos?
- Estudio de Gerardo Horvilleur
sobre boletas sobrantes y faltantes. Aún agregando las boletas por
sección para eliminar la posibilidad de votantes que simplemente
se equivocaron de urna quedan 819,067 boletas sobrantes y
2,979,598 boletas faltantes en 36,081 secciones con 57,657
casillas.
-
Entrevista a Mark Weisbrot, co-director del Center for
Economic and Policy Research en Washington, DC, donde cuestiona
la falta de transparencia en los recuentos y la falta de atención de
los medios internacionales a las enormes irregularidades obvias y
comprobables en los número de boletas. Un análisis crítico y detallado
de Mark Weisbrot et al. sobre los paquetes recontados durante los cómputos
distritales se halla
aquí.
- Nota
del Dr. Arnulfo Castellanos Moreno, especialista en estadística, quien
identifica curvas de
Levy en los histogramas de votación por la CPBT y la APM pero no
identifica ningún comportamiento conocido para los histogramas del
PAN. Asimismo, discute bajo qué condiciones se aplica el teorema
central del límite.
- Video en ingles de Clinton
Eugene Curtis testificando en 2004 ante un juzgado en Ohio sobre
fraudes electrónicos: -¿Cómo sabe [que existen programas para
manipular elecciones]? -porque yo escribí uno para el congresista Tom
Feeney... -¿y podría ser detectado...? -Jamás...
- Análisis por Hugo
Almada Mireles de los resultados del recuento ordenado por el TRIFE,
concentrándose en las alteraciones en los resultados y sus efectos sobre los
diversos actores y enfatizando el caso de Guanajuato.
- Victor Romero ha preparado una gráfica mostrando el número de
casillas rurales y urbanas que contiene cada grupo de 1,000 casillas
ordenadas de acuerdo a la llegada al PREP. Se observa que, como se ha
repetido en numerosas ocasiones, el número de casillas urbanas se
reduce gradualmente mientras que el número de casillas rurales
aumenta. Sin embargo, dichos cambios son graduales y son lineales en
el número total de casillas contabilizadas. De hecho, hay dos
regimenes lineales y la transición entre uno y otro se da poco antes
de las 80,000 casillas. A partir de las 100,000 casillas, el voto
rural comienza a sobrepasar al voto urbano. Contra lo previsto en
otros análisis, el comportamiento del voto urbano-rural no parece
estar relacionado y menos aún explicar el extraño comportamiento de la
diferencia FC-AMLO de las figuras 5 o 23.1.
- Análisis de Pedro
Martínez sobre las elecciones, enfatizando los errores y las
inconsistencias en el reporte del PREP, en sus bases de datos y en las
bases de datos de los Cómputos Distritales. Otra versión se halla aquí.
- Directorio de imágenes enviadas por Jesús
Ibarra Salazar que muestran un error en el expediente
SUP-JIN-274/2006-1: con respecto al Cómputo
Distrital relativo al Distrito Federal 11, de Nuevo León,
con cabecera en el municipio de Guadalupe, el TRIFE confundió los
resultados de la elección presidencial con los de la elección de
diputados. Otro par de imágenes muestran una discrepancia entre
los datos reportados por el PREP y los mismos datos reportados por el
CD (un 186 se transformó en 786).
- Blog de Jesús Ibarra
Salazar sobre las elecciones.
- Luis Estrada y Alejandro Poiré han
preparado un documento titulado
La Evidencia del Fraude en el que argumentan que no
hay evidencia de fraude. Desgraciadamente, dicen desmentir toda
la evidencia existente cuando en realidad parecen obtener
simplemente que a grosso
modo los resultados agregados no son inconsistentes con datos de
votaciones previos, y que de hecho, hubo cierto avance del PRD. Una
diferencia de unos cuantos cientos de miles de votos en los resultados
finales no podrían cambiar sus conclusiones, pero sí podrían modificar
el resultado de la elección.
- Análisis por
Philip Davies sobre la relación entre los votos obtenidos por los
principales contendientes con la participación ciudadana y con el
porcentaje de votos nulos. Se translapa con un estudio
previo de Raymond Hall.
- Estudio de Miguel de
Icaza-Herrera titulado Fraude acromático de las elecciones del 2
de julio del 2006 en el cual calcula de manera muy didáctica la
probabilidad de obtener
las desviaciones observadas en la participación ciudadana, concluyendo
que éstas son prácticamente imposibles, suponiendo que la asignación a
cada casilla de ciudadanos que votan y de ciudadanos que no votan es
aleatoria. Creo que un problema con dicho estudio es que asume que la
decisión de votar o no es individual, en cuyo caso, el ancho del
histograma de participación ciudadana sería mucho mayor que el
esperado. Sin embargo, dicha decisión se puede tomar en grupo, i.e.,
por familia, o grupos de vecinos, etc. El ancho (no la forma)
observado en el histograma sugiere que dichos grupos contienen del
orden de 20 participantes.
- Otro estudio
didáctico de Miguel de Icaza-Herrera en que muestra que el PREP no se
comporta como una caminata aleatoria.
- Respuesta de Miguel de Icaza-Herrera
a mis comentarios sobre el Fraude Acromático, detallando la huella de
los votantes rasurados y añadidos.
- Lista de las 543 casillas de
Guanajuato, de un total de 6,122, en las que los funcionarios
insaculados fueron sustituidos por miembros del SNTE. En 93.92% de
ellas el triunfo correspondió al PAN, mientras que en sólo el 1.66%
ganó la CPBT.
- Lista de las 11,876 casillas
donde AMLO sacó menos votos que que el senador por la misma coalición
PBT. La diferencia de votos llega a 597, y supera los 50 votos en 234
casillas. La suma total de diferencias es 108,294. Asímismo, hay 9,195
casillas donde AMLO obtiene menos votos que los diputados de la
CPBT. La diferencia llega hasta 576 y la suma de las diferencias es de
71,138.
- Lista de las 450 casillas en
las que la CPBT obtuvo dos o menos votos en total.
- Resultados de Carlos
Rodríguez Román, quien realizó una simulación
de la elección basada en las funciones de distribución de voto
reales. A partir de las distribuciones correspondientes a
cada candidato (figura 29) lleva a cabo una
simulación con la cual genera las distribuciones para las diferencias de votos entre pares de
candidatos. Estas coinciden con los resultados reales,
excepto por las anomalías que muestra la figura 33.
Sin embargo, manipulando las votaciones de una manera programada logra
reproducir dicha anomalía.
- Análisis de Alicia Garza
sobre las correlaciones
entre candidatos y entre número de votos y resultados electorales en
la base de datos de inconsistencias.
- Algunas respuestas
de personal del IFE a planteamientos hechos en esta página y en una nota enviada al Dr. Woldenberg.
- Análisis publicado como Ecanal
Special Report No. 1, July 2006 (en inglés).
- Lista de juicios de inconformidad.
- Análisis
sobre los cambios entre los resultados del PREP y del CD, y
recomendaciones para el recuento.
- Explicación de Rici Lake
sobre las diferencias entre números de actas en las elecciones de
presidente, senadores y diputados.
- Análisis de Alberto
Diaz-Cayeros sobre el comportamiento del voto urbano y el rural.
- Análisis de Victor Romero
sobre la dependencia temporal de los datos del PREP y del CD y sus
componentes azarosas y sistemáticas.
- Irregularidades reportadas por
la Coalición PBT.
- Tere Villarreal envió una lista de inconsistencias entre las
votaciones por Presidente, Senadores y Diputados en Nuevo León.
- Boletín sobre un documento
entregado al TRIFE con resultados de diversos estudios sobre las elecciones.
- Rici Lake ha dado una explicación
tentativa de lo que pudo haber sucedido dentro del IFE durante
el intervalo de tiempo en que el reporte del PREP muestra errores.
- Fernando Rodriguez ha hecho
una crítica a la hipótesis de
equiprobabilidad de los últimos dígitos.
- Análisis de Luis Gerardo
Magaña sobre el recuento llevado a cabo en el Cómputo Distrital.
- Copia de una entrevista e la
Crónica a Javier Aparicio.
- Copia del escrito que la
Asociación Nacional de Abogados Democráticos (ANAD) envió al TRIFE el
día 3 de agosto del 2006.
- Algunos comentarios críticos
de Fernando Rodríguez.
- Copia del
artículo México: la batalla de los renegados de
Hector Díaz Polanco.
- En una nota
electrónica, Luis Horacio Gutierrez ha facilitado un artículo sobre la teoría matemática que
sustenta a la Ley de Benford y a su amplia aplicabilidad y otro
artículo escrito por el profesor
W. R. Mebane de la U. de Cornell en que aplica dicha ley al segundo
dígito más significativo para estudiar
sistemáticamente los resultados de nuestra reciente elección y la
elección de Florida en 2004. Finalmente, aquí hay una presentación con un estudio
detallado de nuestra eleeción empleando la ley de Benford.
- Discusión de Pablo de la
Mora sobre la imposibilidad de los comportamientos estadísticos
anómalos en una elección limpia.
- Análisis de
Gerardo Horvilleur sobre resultados muestreados sobre las actas con
inconsistencias y comentario de
L. Fernando Jaime Padilla.
- Análisis de Jaime Ruiz sobre inconsistencias entre la
información
dada a conocer la tarde del Cómputo Distrital y la información
asentada en las bases de datos correspondientes. (Ver mensaje y figuras 50 y 51
- Análisis detallado de los
resultados estimados en base a las actas con
inconsistencias. Curiosamente, este enorme subconjunto parece no
formar una muestra sin sesgo. Este, o un estudio similar, aparece
comentado aquí.
-
Histogramas de la elección presidencial en México (número de votos
que recibió cada candidato como función del porcentaje de
participación ciudadana) preparados por Raymond Hall. Muestran que
Calderón obtuvo ventaja sobre
AMLO en aquellas casillas donde el porcentaje de participación fue más
baja o más alta que la participación promedio. De acuerdo a este
artículo de John Brady, este tipo de correlaciones podría ser
indicativo de prácticas tales y como los carruseles.
- Otro análisis preparado
independientemente por Ernesto M. Espinosa Asuar sobre la correlación
entre grado de participación ciudadana y votación para los distintos
candidatos. Además, hizo una cuantificación de los datos, la cual
muestra que: Tomando sólo las casillas que tienen una participación
entre el 72.5% y el 80% la diferencia está a favor de Calderón por
casi 330 mil votos. Son 7725 casillas (poco más de 4 millones de
votantes en el padrón)....Las 122 casillas con un porcentaje de
participación mayor al 100%
- Pietro envió páginas del PREP
capturadas desde las 8:00PM el día de la elección. La primera tenía
fecha del sábado.
- Un
escrito del Dr. Jaime Ruiz titulado Algunas
Reflecciones del por qué los Datos del IFE para la Eleccion para
Presidente no son Creibles (
vesrión previa).
- Conclusiones del estudio
realizado por el Dr. Victor Romero, investigador del Instituto de
Física de la UNAM:
- Texto (pdf)
- Figura 1
- Figura 2
- Figura 3
- Figura 4
- Figura 5
- Figura 6
- Figura 7
- ...Tercero, decir que la
afirmación de que primero llegan las
actas de las zonas urbanas y luego las de la zona rural es
relativamente cierto; pero sólo relativamente. Es proceso es mucho más
complicado...Su trabajo es muy mesurado en sus conclusiones. Es, por
ello, que me parece que sea una lástima que esté siendo usado por
personas extremadamente acaloradas...
- ...Si uno hacia el seguimiento
del avance del PREP por estado, lo
siguiente resalta:...
- Resumen: durante en conteo del prep, hay un intervalo durante el que
el numero de votos por el prd es una funcion lineal del numero de
votos por el pan, con una CHI CUADRADA DE 4 en un fit de VEINTE GRADOS
DE LIBERTAD (el valor esperado hubiera sido 20 en vez de 4). Este
comportamiento lineal:...lo cual es MUY INUSUAL al
ajustar datos reales INCLUSO EN CASOS DONDE SE SABE QUE HAY UNA
DEPENDENCIA LINEAL. En este caso, esto es aun mas improbable, pues EL
NUMERO DE VOTOS NO TIENE POR QUE SEGUIR UN COMPORTAMIENTO LINEAL Y
UNIFORME, menos durante un intervalo tan grande.
- Texto
- Imagen 1
- Imagen 2
- Imagen 3
- Imagen 4
- Análisis
de los resultados
electorales a partir de la Ley de Benford, por R. Mansilla CEIICH,
UNAM. Conclusiones: Resulta muy difícil explicar el comportamiento de las distribuciones empíricas de los candidatos a la luz de los resultados teóricos antes expuestos. La ley de Benford es una regularidad bastante universal y toda divergencia de la misma debe ser observada con suspicacia.
...Mas aun, si sumas
los porcentajes de todos los partidos, nulos y candidatos no
registrados que proporciona el PREP nunca obtienes 100%.
Mexico remains without an elected president. In the last few days
a number of problems have
surfaced in the election.
Indice
- Códigos empleados: Disculpas, pero como los elaboré a la carrera
son algo crípticos y no creo poder entenderlos en un par de días
más. Quizás estas versiones no sean las últimas y no funcionen; sólo
son las que me encontré regadas por mi computadora. Ilustran en todo
caso que Linux es mejor que Windows, pues tiene herramientas
poderosísimas gratis... (pero eso es otra batalla)
- Mi programa en perl para capturar
los datos del prep.
- Mi programa en bash para
extraer los totales de votos de una página web del prep.
- Mi programa en bash para
extraer los porcentajes de la votación de una página web del prep.
- Comando típico para emplear los programas previos que extraen datos de las
páginas web:
for i in index_contenido.html.* ; do ~/txt/papers/06/elecciones/extraenumerosh $i >>rem.dat; done
- Comando para formatear las tablas correspondientes a la figura
1:
perl -pe 's/\s*//; s/%//g;chomp; $_.=[" "," ", " ", "\n"]->[$i++%4]; ' rem1.dat
- Comando para formatear los datos correspondientes a la figura
3:
perl -pe 's/\s*//; s/,//g;chomp; $_.=[" "," ", " ", "\n"]->[$i++%4]; ' rem1.dat
- Comando para preparar los datos de la figura 4:
perl -nae 'BEGIN{@o=(0,0,0,0)} {@n=@F; print "$n[0]", join " ", (map {" ".($n[$_]-$o[$_])/($n[0]-$o[0])} (1,2,3)), "\n";@o=@n }' numeros.dat >diferenciasporcasilla.dat
-
Base de datos del PREP
-
Datos completos del PREP en la elección para presidente ¡por casilla!
(¡Gracias Mauricio!)
- La misma base (sin el encabezado
de e-mail de Mauricio).
- La misma base pero ordenada por
orden cronológico de sellado
- Una sección de la base
de datos, mostrando votos por casilla como función del tiempo sin
agregar. Los campos seleccionados son TIEMPO (en minutos transcurridos
a partir del inicio del conteo ¡a las 18:35!), datos del PAN,
ALIANZA_POR_MEXICO, POR_EL_BIEN_DE_TODOS, NUEVA_ALIANZA,
ALTERNATIVA_SOCIAL_DEMOCRATA, NO_REGISTRADOS, NULOS y
NUMERO_VOTANTES.
- Un pequeño programa en perl para extraer
campos seleccionados de la base de datos previas. El programa puede
ser fácilmente adaptado a otras bases de datos similares y para
hacer proceso sobre los datos obtenidos.
- Una sección de la base
de datos, mostrando votos acumulados como función del tiempo.
- Base de datos del PREP para la
elección de senadores, casilla por casilla.
- Base de datos del PREP para la
elección de diputados, casilla por casilla.
- Bases de datos del CONTEO DISTRITAL
para la elección de presidente, diputados y senadores, casilla por casilla.
- Programa en PERL para extraer datos
específicos de las bases anteriores. Puede ser modificado fácilmente
para procesar dichos datos.
- Versiones comprimidas originales de las bases de datos del CONTEO
DISTRITAL para la elección de presidente, diputados y senadores, casilla por
casilla, obtenidas de aquí.
Nota: mis versiones '.txt' difieren de las contenidas en
estos archivos en los retornos de carro. El IFE comprimió esos
archivos en máquinas WINDOWS ¡¡Lo cual me horroriza!! Manejar
información delicada con sistemas operativos tan susceptibles a
ataques me parece una imprudencia. ¿Uds. han sabido de alguna máquina
infectada por virus? ¿Recuerda el nombre de su sistema operativo?
- Bases de datos con el campo TIME_STAMP añadido (tiempo en minutos
desde el inicio del conteo distrital presidencial), con '#' para
distinguir comentarios, con los campos separados por espacios y con
los campos vacíos reemplazados por ceros.
(presidente, diputados y senadores).
- Las mismas bases de datos pero ordenadas de acuerdo al momento de
conteo para
(presidente, diputados y senadores).
- Nota:Las bases de datos mencionadas arriba tenían un error
que fue corregido el 27/vii/06. El error involucra únicamente la
primera columna a la cual llamé TIME_STAMP y que denota el tiempo
en minutos transcurrido desde que se registró la primer acta de la
elección presidencial. Los registros de los archivos correspondientes
a presidente, diputados y senadores) fueron ordenados de
acuerdo a dicho campo y por lo tanto estaban mal ordenados. El error
provino de la línea
my $timesec=(((($dia-05)*24+$hora*60)+$min)*60+$seg);
cuyo propósito es convertir la fecha y hora en el número de segundos
transcurridos desde la media noche del 5/vii/06. Si estudian esa
línea con cuidado descubrirán el error. Pido una disculpa por el mismo.
visitas
desde el 14 de julio de 2006, 18:15:04.

Indice

{kind=link}
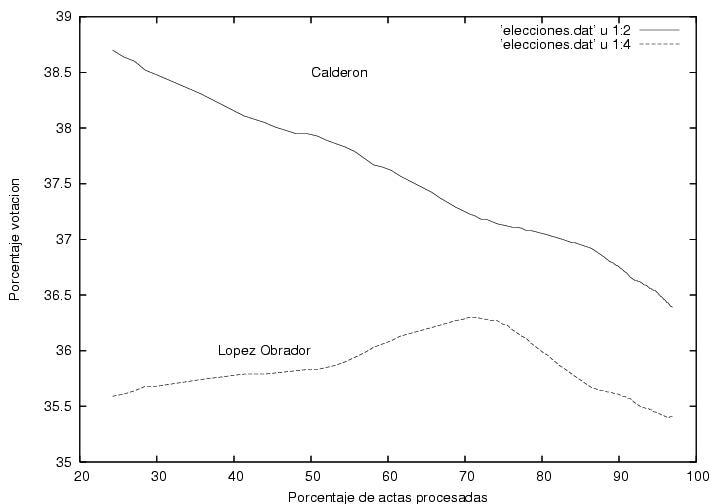{kind=link}
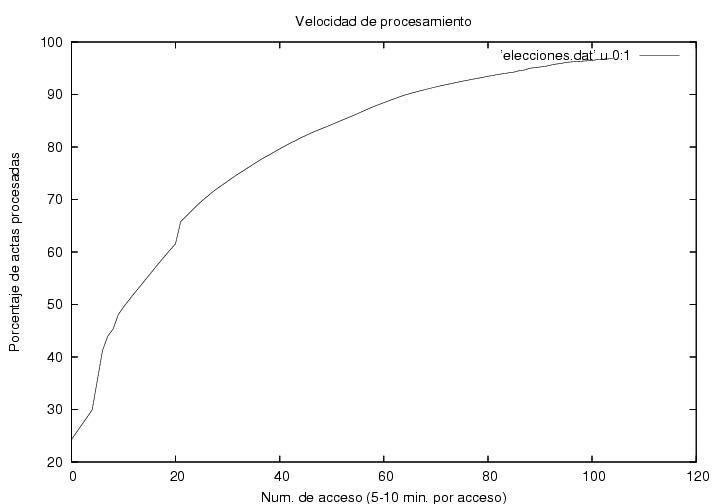{kind=link}
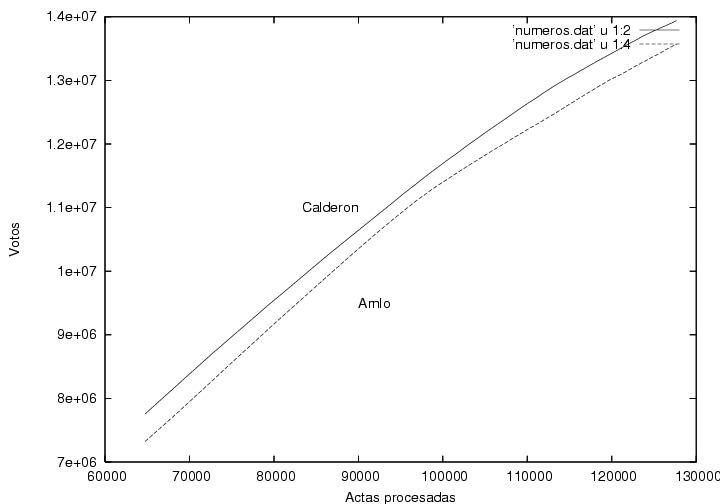{kind=link}
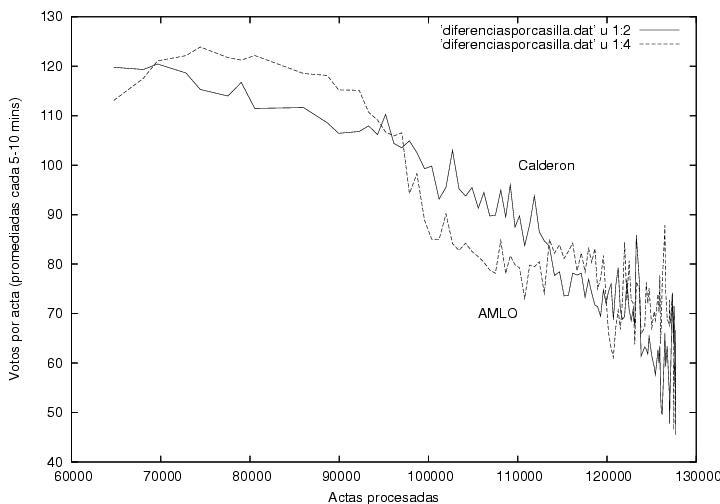{kind=link}
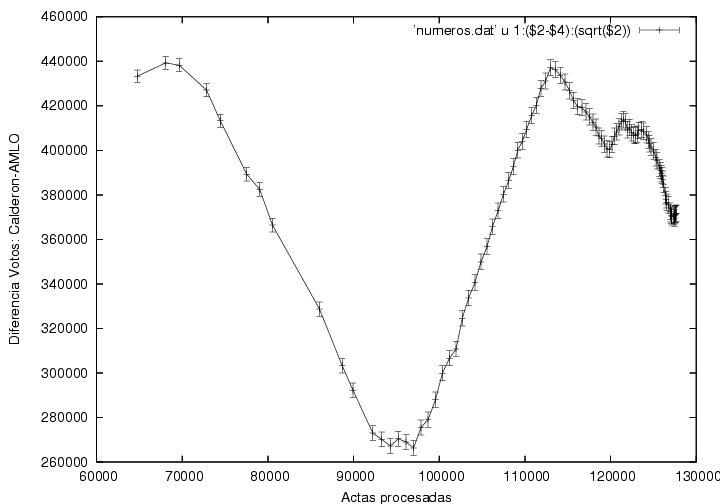{kind=link}
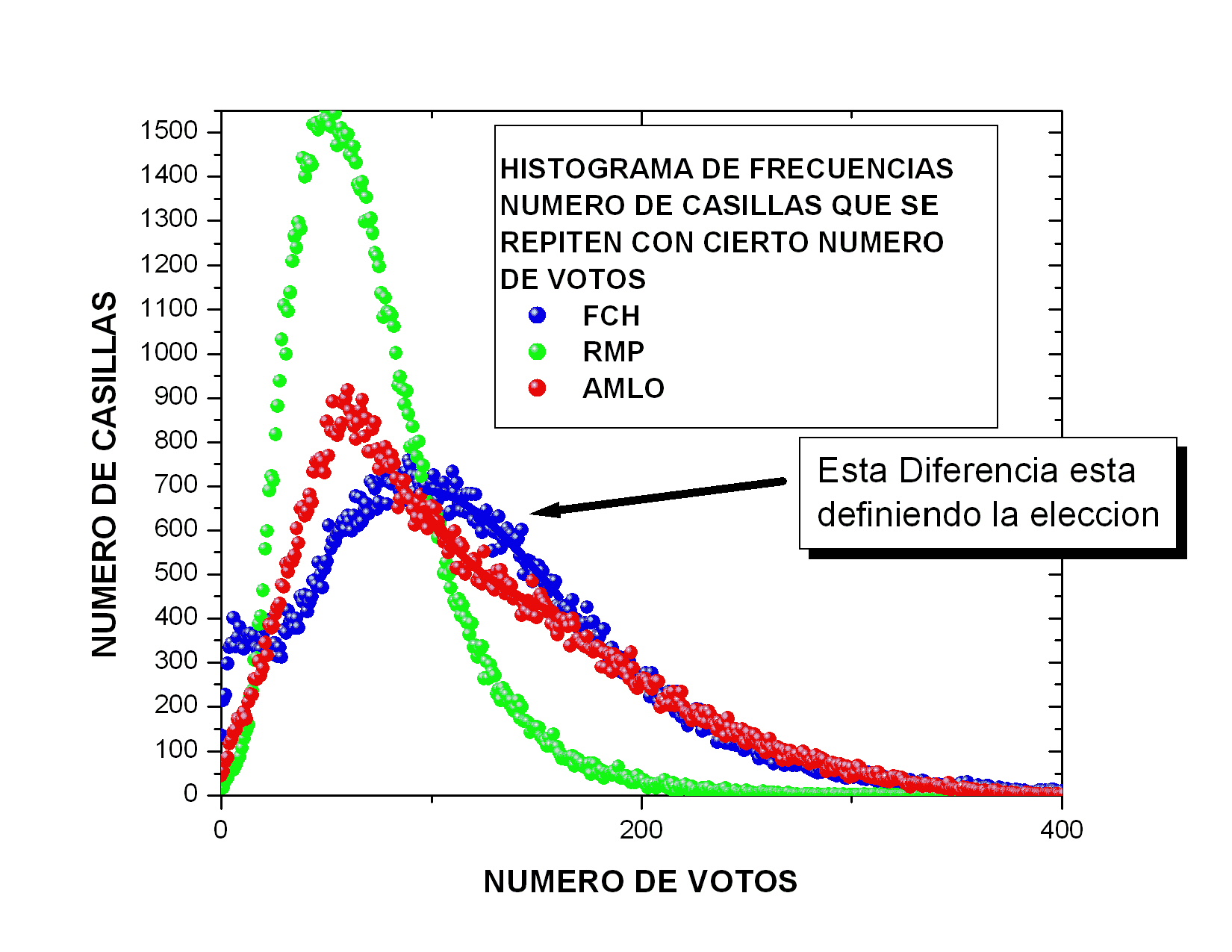{kind=link}
{kind=link}
{kind=link}
{kind=link}
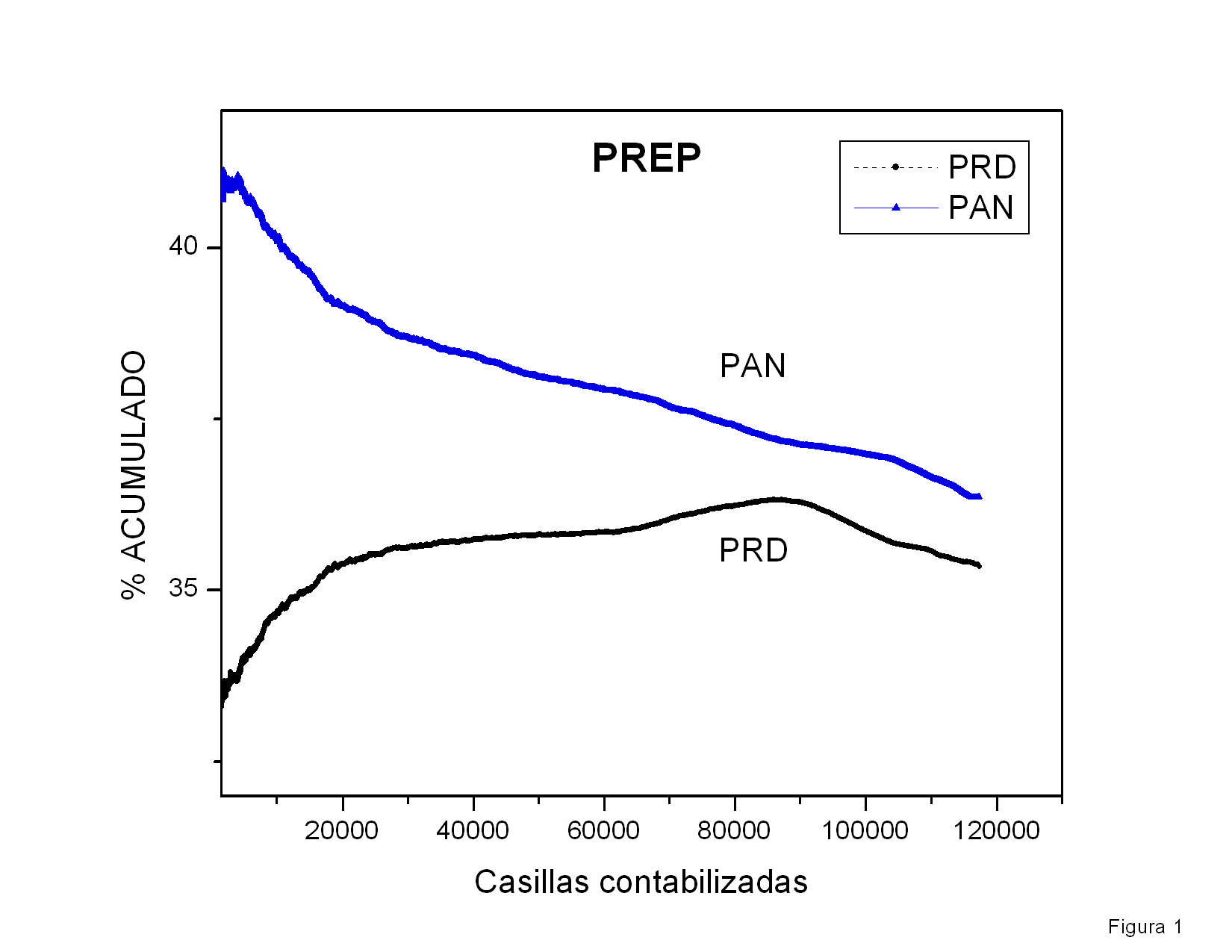{kind=link}
{kind=link}
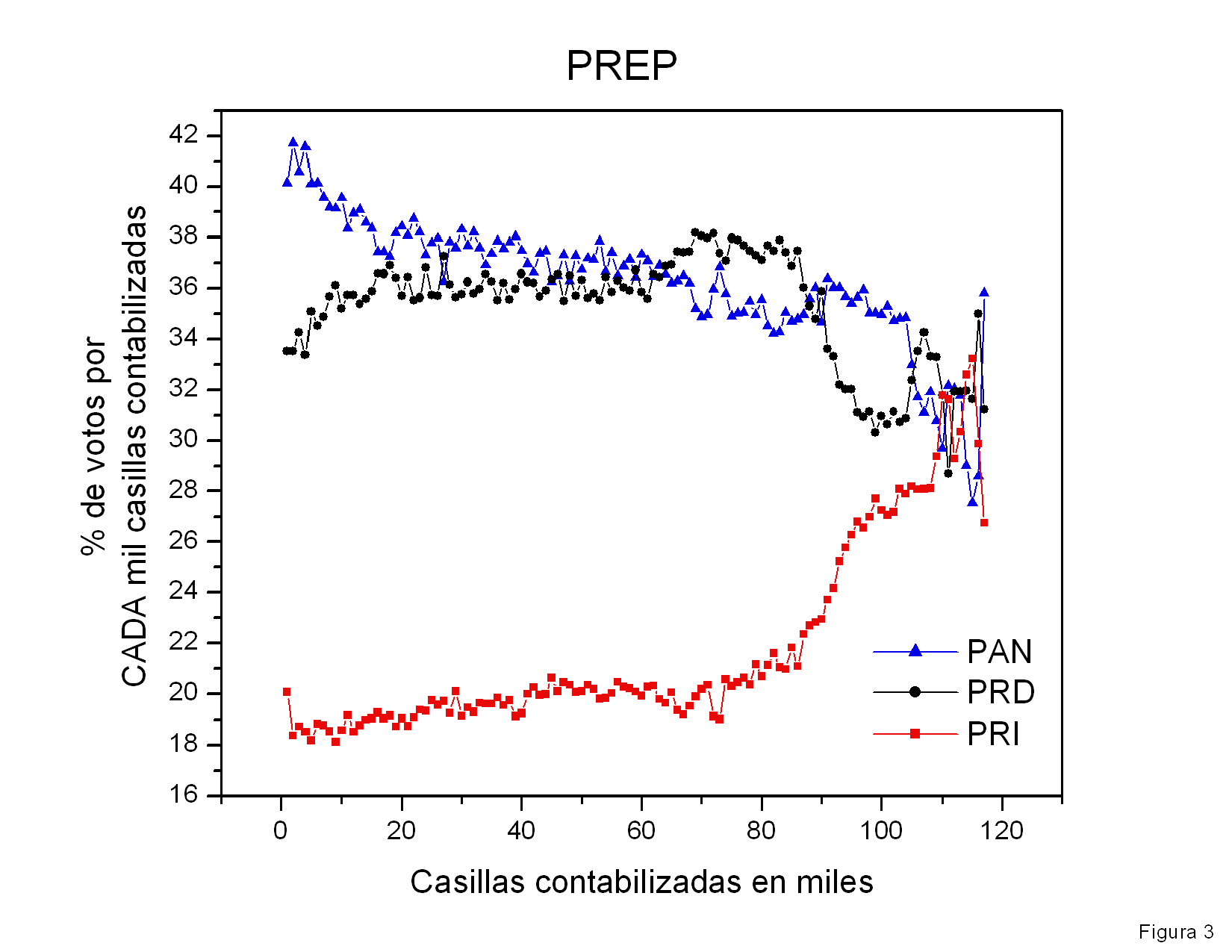{kind=link}
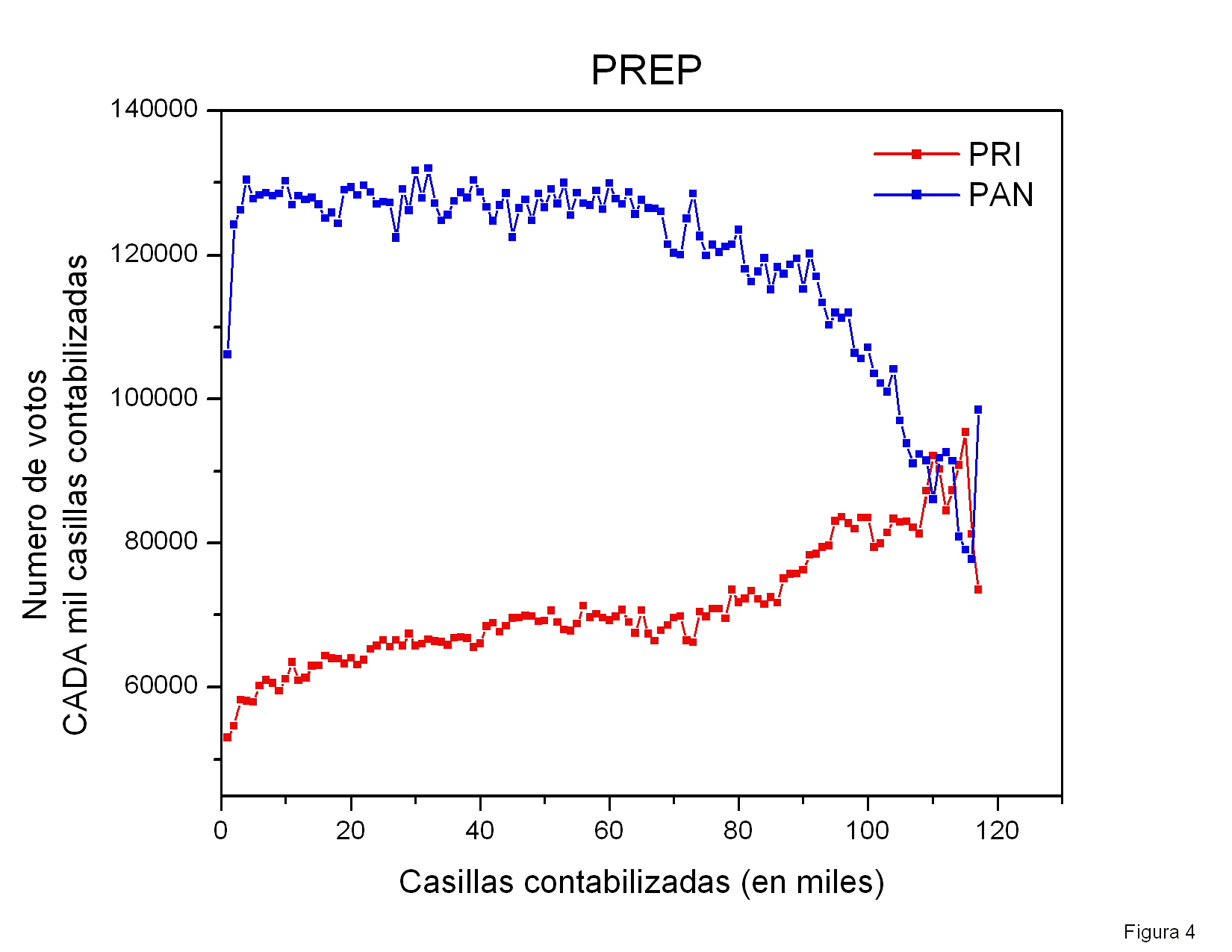{kind=link}
{kind=link}
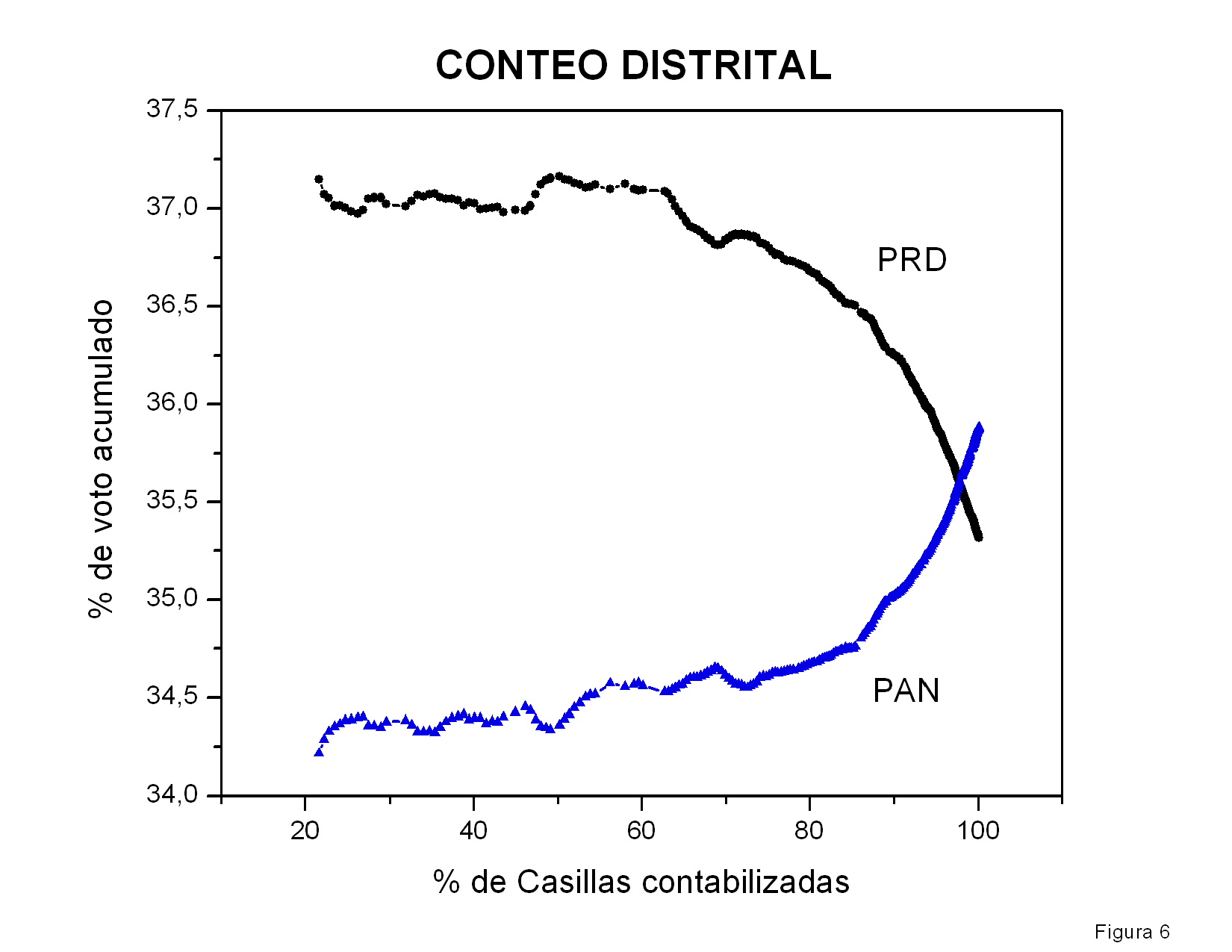{kind=link}
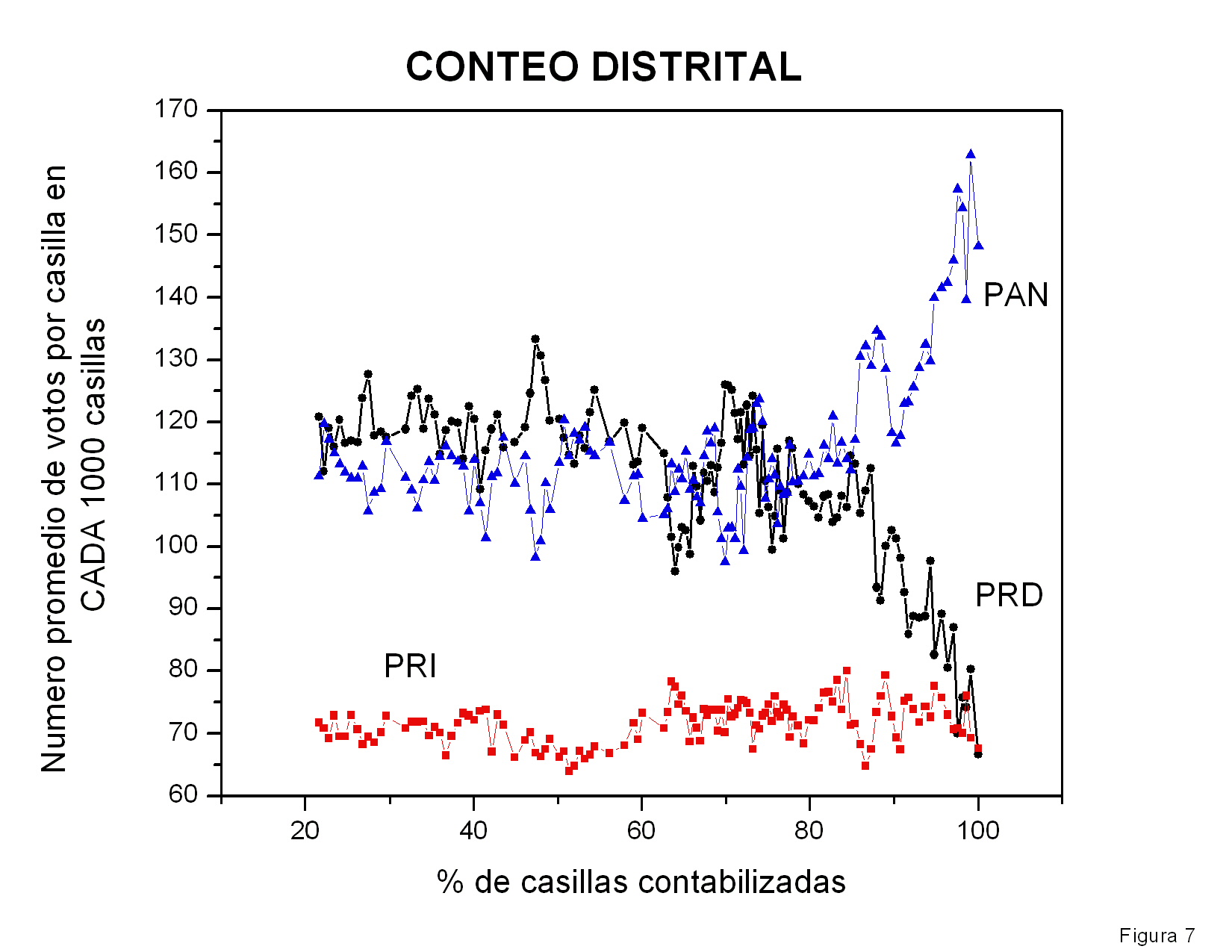{kind=link}
{kind=link}
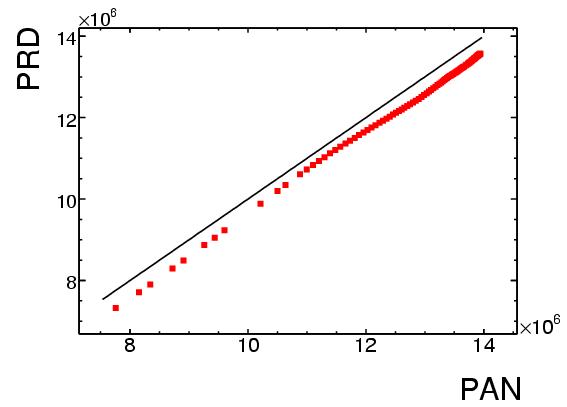{kind=link}
{kind=link}
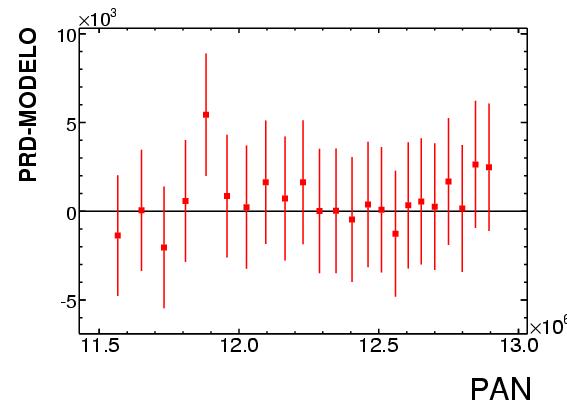{kind=link}